 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Calibration to Collaboration: LLM Uncertainty Quantification Should Be More Human-Centered
Jun 09, 2025Large Language Models (LLMs) are increasingly assisting users in the real world, yet their reliability remains a concern. Uncertainty quantification (UQ) has been heralded as a tool to enhance human-LLM collaboration by enabling users to know when to trust LLM predictions. We argue that current practices for uncertainty quantification in LLMs are not optimal for developing useful UQ for human users making decisions in real-world tasks. Through an analysis of 40 LLM UQ methods, we identify three prevalent practices hindering the community's progress toward its goal of benefiting downstream users: 1) evaluating on benchmarks with low ecological validity; 2) considering only epistemic uncertainty; and 3) optimizing metrics that are not necessarily indicative of downstream utility. For each issue, we propose concrete user-centric practices and research directions that LLM UQ researchers should consider. Instead of hill-climbing on unrepresentative tasks using imperfect metrics, we argue that the community should adopt a more human-centered approach to LLM uncertainty quantification.
Adjust for Trust: Mitigating Trust-Induced Inappropriate Reliance on AI Assistance
Feb 18, 2025



Trust biases how users rely on AI recommendations in AI-assisted decision-making tasks, with low and high levels of trust resulting in increased under- and over-reliance, respectively. We propose that AI assistants should adapt their behavior through trust-adaptive interventions to mitigate such inappropriate reliance. For instance, when user trust is low, providing an explanation can elicit more careful consideration of the assistant's advice by the user. In two decision-making scenarios -- laypeople answering science questions and doctors making medical diagnoses -- we find that providing supporting and counter-explanations during moments of low and high trust, respectively, yields up to 38% reduction in inappropriate reliance and 20% improvement in decision accuracy. We are similarly able to reduce over-reliance by adaptively inserting forced pauses to promote deliberation. Our results highlight how AI adaptation to user trust facilitates appropriate reliance, presenting exciting avenues for improving human-AI collaboration.
Better Slow than Sorry: Introducing Positive Friction for Reliable Dialogue Systems
Jan 31, 2025



While theories of discourse and cognitive science have long recognized the value of unhurried pacing, recent dialogue research tends to minimize friction in conversational systems. Yet, frictionless dialogue risks fostering uncritical reliance on AI outputs, which can obscure implicit assumptions and lead to unintended consequences. To meet this challenge, we propose integrating positive friction into conversational AI, which promotes user reflection on goals, critical thinking on system response, and subsequent re-conditioning of AI systems. We hypothesize systems can improve goal alignment, modeling of user mental states, and task success by deliberately slowing down conversations in strategic moments to ask questions, reveal assumptions, or pause. We present an ontology of positive friction and collect expert human annotations on multi-domain and embodied goal-oriented corpora. Experiments on these corpora, along with simulated interactions using state-of-the-art systems, suggest incorporating friction not only fosters accountable decision-making, but also enhances machine understanding of user beliefs and goals, and increases task success rates.
Compare without Despair: Reliable Preference Evaluation with Generation Separability
Jul 02, 2024



Human evaluation of generated language through pairwise preference judgments is pervasive. However, under common scenarios, such as when generations from a model pair are very similar, or when stochastic decoding results in large variations in generations, it results in inconsistent preference ratings. We address these challenges by introducing a meta-evaluation measure, separability, which estimates how suitable a test instance is for pairwise preference evaluation. For a candidate test instance, separability samples multiple generations from a pair of models, and measures how distinguishable the two sets of generations are. Our experiments show that instances with high separability values yield more consistent preference ratings from both human- and auto-raters. Further, the distribution of separability allows insights into which test benchmarks are more valuable for comparing models. Finally, we incorporate separability into ELO ratings, accounting for how suitable each test instance might be for reliably ranking LLMs. Overall, separability has implications for consistent, efficient and robust preference evaluation of LLMs with both human- and auto-raters.
Selective "Selective Prediction": Reducing Unnecessary Abstention in Vision-Language Reasoning
Feb 23, 2024



Prior work on selective prediction minimizes incorrect predictions from vision-language models (VLMs) by allowing them to abstain from answering when uncertain. However, when deploying a vision-language system with low tolerance for inaccurate predictions, selective prediction may be over-cautious and abstain too frequently, even on many correct predictions. We introduce ReCoVERR, an inference-time algorithm to reduce the over-abstention of a selective vision-language system without decreasing prediction accuracy. When the VLM makes a low-confidence prediction, instead of abstaining ReCoVERR tries to find relevant clues in the image that provide additional evidence for the prediction. ReCoVERR uses an LLM to pose related questions to the VLM, collects high-confidence evidences, and if enough evidence confirms the prediction the system makes a prediction instead of abstaining. ReCoVERR enables two VLMs, BLIP2 and InstructBLIP, to answer up to 20% more questions on the A-OKVQA task than vanilla selective prediction without decreasing system accuracy, thus improving overall system reliability.
WinoViz: Probing Visual Properties of Objects Under Different States
Feb 21, 2024



Humans perceive and comprehend different visual properties of an object based on specific contexts. For instance, we know that a banana turns brown ``when it becomes rotten,'' whereas it appears green ``when it is unripe.'' Previous studies on probing visual commonsense knowledge have primarily focused on examining language models' understanding of typical properties (e.g., colors and shapes) of objects. We present WinoViz, a text-only evaluation dataset, consisting of 1,380 examples that probe the reasoning abilities of language models regarding variant visual properties of objects under different contexts or states. Our task is challenging since it requires pragmatic reasoning (finding intended meanings) and visual knowledge reasoning. We also present multi-hop data, a more challenging version of our data, which requires multi-step reasoning chains to solve our task. In our experimental analysis, our findings are: a) Large language models such as GPT-4 demonstrate effective performance, but when it comes to multi-hop data, their performance is significantly degraded. b) Large models perform well on pragmatic reasoning, but visual knowledge reasoning is a bottleneck in our task. c) Vision-language models outperform their language-model counterparts. d) A model with machine-generated images performs poorly in our task. This is due to the poor quality of the generated images.
Exploring Strategies for Modeling Sign Language Phonology
Sep 30, 2023


Like speech, signs are composed of discrete, recombinable features called phonemes. Prior work shows that models which can recognize phonemes are better at sign recognition, motivating deeper exploration into strategies for modeling sign language phonemes. In this work, we learn graph convolution networks to recognize the sixteen phoneme "types" found in ASL-LEX 2.0. Specifically, we explore how learning strategies like multi-task and curriculum learning can leverage mutually useful information between phoneme types to facilitate better modeling of sign language phonemes. Results on the Sem-Lex Benchmark show that curriculum learning yields an average accuracy of 87% across all phoneme types, outperforming fine-tuning and multi-task strategies for most phoneme types.
I2I: Initializing Adapters with Improvised Knowledge
Apr 04, 2023



Adapters present a promising solution to the catastrophic forgetting problem in continual learning. However, training independent Adapter modules for every new task misses an opportunity for cross-task knowledge transfer. We propose Improvise to Initialize (I2I), a continual learning algorithm that initializes Adapters for incoming tasks by distilling knowledge from previously-learned tasks' Adapters. We evaluate I2I on CLiMB, a multimodal continual learning benchmark, by conducting experiments on sequences of visual question answering tasks. Adapters trained with I2I consistently achieve better task accuracy than independently-trained Adapters, demonstrating that our algorithm facilitates knowledge transfer between task Adapters. I2I also results in better cross-task knowledge transfer than the state-of-the-art AdapterFusion without incurring the associated parametric cost.
Multimodal Speech Recognition for Language-Guided Embodied Agents
Feb 27, 2023Benchmarks for language-guided embodied agents typically assume text-based instructions, but deployed agents will encounter spoken instructions. While Automatic Speech Recognition (ASR) models can bridge the input gap, erroneous ASR transcripts can hurt the agents' ability to complete tasks. In this work, we propose training a multimodal ASR model to reduce errors in transcribing spoken instructions by considering the accompanying visual context. We train our model on a dataset of spoken instructions, synthesized from the ALFRED task completion dataset, where we simulate acoustic noise by systematically masking spoken words. We find that utilizing visual observations facilitates masked word recovery, with multimodal ASR models recovering up to 30% more masked words than unimodal baselines. We also find that a text-trained embodied agent successfully completes tasks more often by following transcribed instructions from multimodal ASR models.
VAuLT: Augmenting the Vision-and-Language Transformer with the Propagation of Deep Language Representations
Aug 18, 2022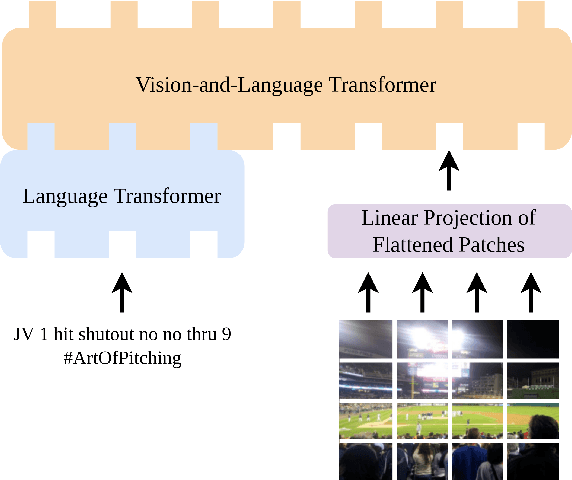

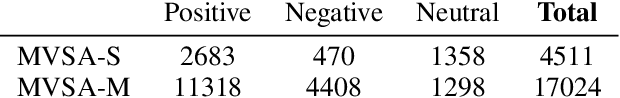

We propose the Vision-and-Augmented-Language Transformer (VAuLT). VAuLT is an extension of the popular Vision-and-Language Transformer (ViLT), and improves performance on vision-and-language tasks that involve more complex text inputs than image captions while having minimal impact on training and inference efficiency. ViLT, importantly, enables efficient training and inference in vision-and-language tasks, achieved by using a shallow image encoder. However, it is pretrained on captioning and similar datasets, where the language input is simple, literal, and descriptive, therefore lacking linguistic diversity. So, when working with multimedia data in the wild, such as multimodal social media data (in our work, Twitter), there is a notable shift from captioning language data, as well as diversity of tasks, and we indeed find evidence that the language capacity of ViLT is lacking instead. The key insight of VAuLT is to propagate the output representations of a large language model like BERT to the language input of ViLT. We show that such a strategy significantly improves over ViLT on vision-and-language tasks involving richer language inputs and affective constructs, such as TWITTER-2015, TWITTER-2017, MVSA-Single and MVSA-Multiple, but lags behind pure reasoning tasks such as the Bloomberg Twitter Text-Image Relationship dataset. We have released the code for all our experiments at https://github.com/gchochla/VAuLT.