 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoing for GOAL: A Resource for Grounded Football Commentaries
Nov 08, 2022



Recent video+language datasets cover domains where the interaction is highly structured, such as instructional videos, or where the interaction is scripted, such as TV shows. Both of these properties can lead to spurious cues to be exploited by models rather than learning to ground language. In this paper, we present GrOunded footbAlL commentaries (GOAL), a novel dataset of football (or `soccer') highlights videos with transcribed live commentaries in English. As the course of a game is unpredictable, so are commentaries, which makes them a unique resource to investigate dynamic language grounding. We also provide state-of-the-art baselines for the following tasks: frame reordering, moment retrieval, live commentary retrieval and play-by-play live commentary generation. Results show that SOTA models perform reasonably well in most tasks. We discuss the implications of these results and suggest new tasks for which GOAL can be used. Our codebase is available at: https://gitlab.com/grounded-sport-convai/goal-baselines.
An Empirical Study on the Generalization Power of Neural Representations Learned via Visual Guessing Games
Jan 31, 2021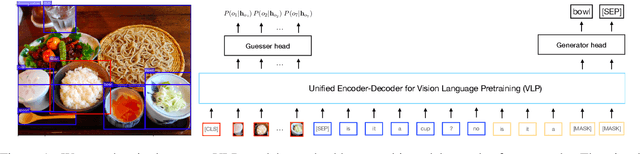


Guessing games are a prototypical instance of the "learning by interacting" paradigm. This work investigates how well an artificial agent can benefit from playing guessing games when later asked to perform on novel NLP downstream tasks such as Visual Question Answering (VQA). We propose two ways to exploit playing guessing games: 1) a supervised learning scenario in which the agent learns to mimic successful guessing games and 2) a novel way for an agent to play by itself, called Self-play via Iterated Experience Learning (SPIEL). We evaluate the ability of both procedures to generalize: an in-domain evaluation shows an increased accuracy (+7.79) compared with competitors on the evaluation suite CompGuessWhat?!; a transfer evaluation shows improved performance for VQA on the TDIUC dataset in terms of harmonic average accuracy (+5.31) thanks to more fine-grained object representations learned via SPIEL.
Encoding Syntactic Constituency Paths for Frame-Semantic Parsing with Graph Convolutional Networks
Nov 26, 2020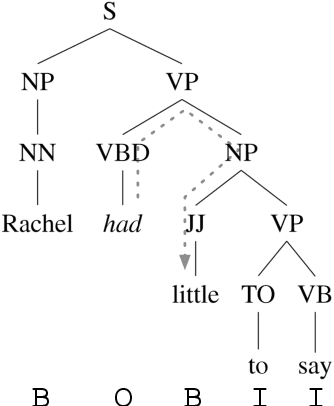
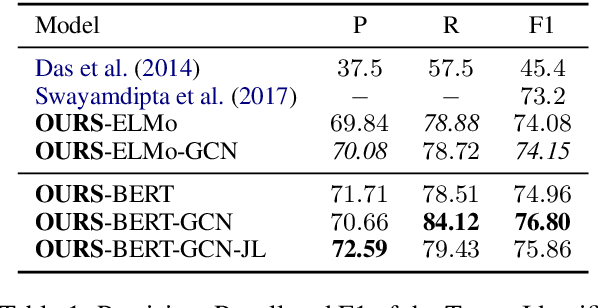
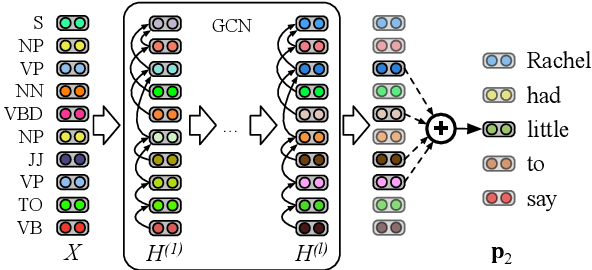
We study the problem of integrating syntactic information from constituency trees into a neural model in Frame-semantic parsing sub-tasks, namely Target Identification (TI), FrameIdentification (FI), and Semantic Role Labeling (SRL). We use a Graph Convolutional Network to learn specific representations of constituents, such that each constituent is profiled as the production grammar rule it corresponds to. We leverage these representations to build syntactic features for each word in a sentence, computed as the sum of all the constituents on the path between a word and a task-specific node in the tree, e.g. the target predicate for SRL. Our approach improves state-of-the-art results on the TI and SRL of ~1%and~3.5% points, respectively (+2.5% additional points are gained with BERT as input), when tested on FrameNet 1.5, while yielding comparable results on the CoNLL05 dataset to other syntax-aware systems.
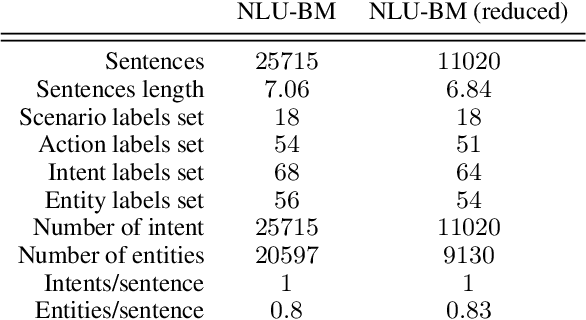
SLURP: A Spoken Language Understanding Resource Package
Nov 26, 2020

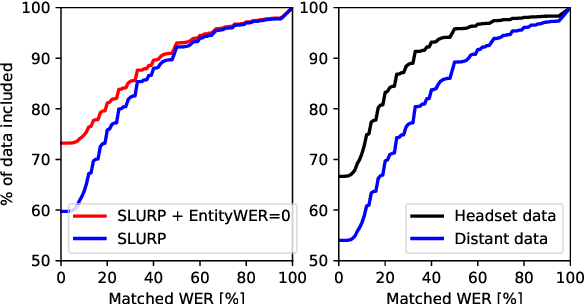
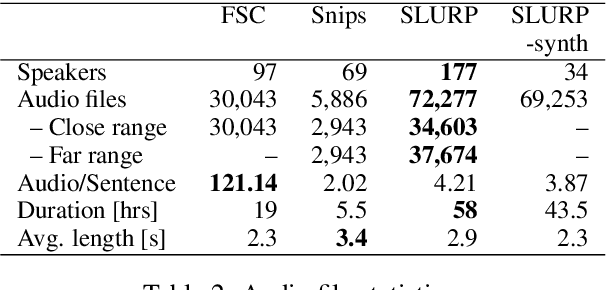
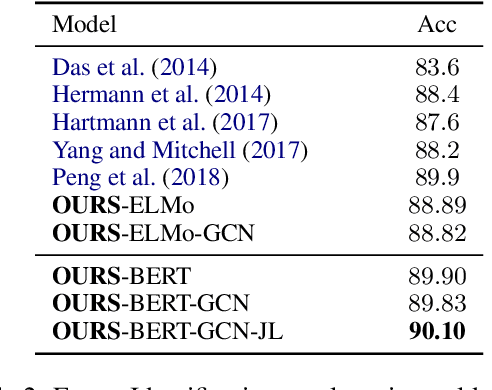
Spoken Language Understanding infers semantic meaning directly from audio data, and thus promises to reduce error propagation and misunderstandings in end-user applications. However, publicly available SLU resources are limited. In this paper, we release SLURP, a new SLU package containing the following: (1) A new challenging dataset in English spanning 18 domains, which is substantially bigger and linguistically more diverse than existing datasets; (2) Competitive baselines based on state-of-the-art NLU and ASR systems; (3) A new transparent metric for entity labelling which enables a detailed error analysis for identifying potential areas of improvement. SLURP is available at https: //github.com/pswietojanski/slurp.
Imagining Grounded Conceptual Representations from Perceptual Information in Situated Guessing Games
Nov 05, 2020
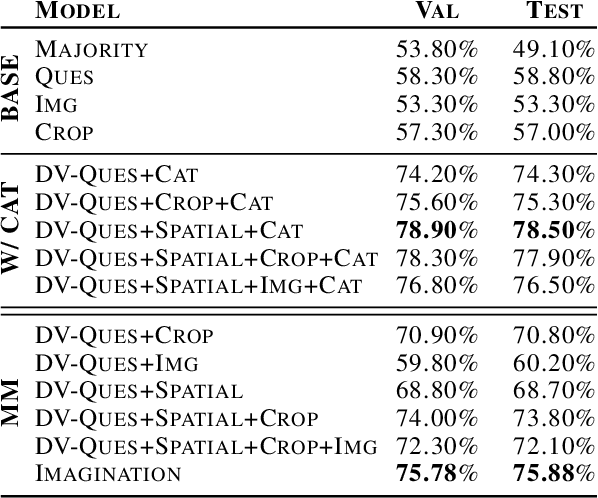

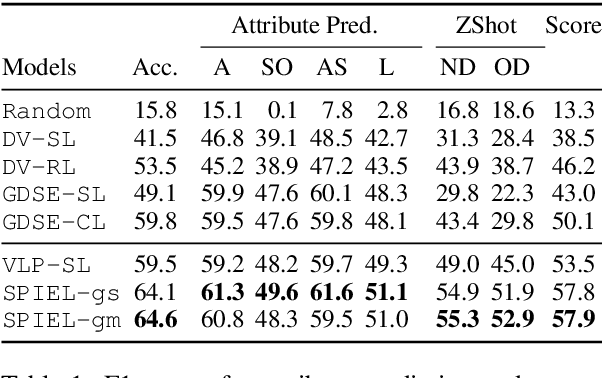
In visual guessing games, a Guesser has to identify a target object in a scene by asking questions to an Oracle. An effective strategy for the players is to learn conceptual representations of objects that are both discriminative and expressive enough to ask questions and guess correctly. However, as shown by Suglia et al. (2020), existing models fail to learn truly multi-modal representations, relying instead on gold category labels for objects in the scene both at training and inference time. This provides an unnatural performance advantage when categories at inference time match those at training time, and it causes models to fail in more realistic "zero-shot" scenarios where out-of-domain object categories are involved. To overcome this issue, we introduce a novel "imagination" module based on Regularized Auto-Encoders, that learns context-aware and category-aware latent embeddings without relying on category labels at inference time. Our imagination module outperforms state-of-the-art competitors by 8.26% gameplay accuracy in the CompGuessWhat?! zero-shot scenario (Suglia et al., 2020), and it improves the Oracle and Guesser accuracy by 2.08% and 12.86% in the GuessWhat?! benchmark, when no gold categories are available at inference time. The imagination module also boosts reasoning about object properties and attributes.
CompGuessWhat?!: A Multi-task Evaluation Framework for Grounded Language Learning
Jun 03, 2020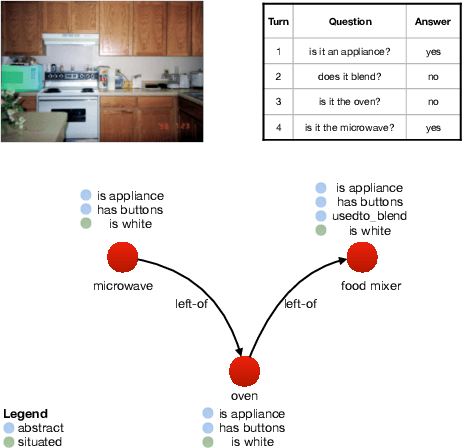
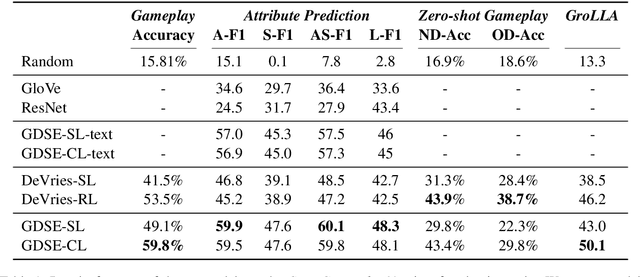


Approaches to Grounded Language Learning typically focus on a single task-based final performance measure that may not depend on desirable properties of the learned hidden representations, such as their ability to predict salient attributes or to generalise to unseen situations. To remedy this, we present GROLLA, an evaluation framework for Grounded Language Learning with Attributes with three sub-tasks: 1) Goal-oriented evaluation; 2) Object attribute prediction evaluation; and 3) Zero-shot evaluation. We also propose a new dataset CompGuessWhat?! as an instance of this framework for evaluating the quality of learned neural representations, in particular concerning attribute grounding. To this end, we extend the original GuessWhat?! dataset by including a semantic layer on top of the perceptual one. Specifically, we enrich the VisualGenome scene graphs associated with the GuessWhat?! images with abstract and situated attributes. By using diagnostic classifiers, we show that current models learn representations that are not expressive enough to encode object attributes (average F1 of 44.27). In addition, they do not learn strategies nor representations that are robust enough to perform well when novel scenes or objects are involved in gameplay (zero-shot best accuracy 50.06%).
Hierarchical Multi-Task Natural Language Understanding for Cross-domain Conversational AI: HERMIT NLU
Oct 02, 2019
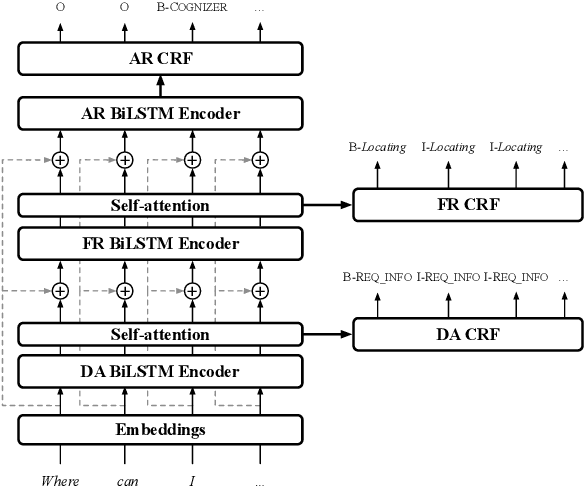
We present a new neural architecture for wide-coverage Natural Language Understanding in Spoken Dialogue Systems. We develop a hierarchical multi-task architecture, which delivers a multi-layer representation of sentence meaning (i.e., Dialogue Acts and Frame-like structures). The architecture is a hierarchy of self-attention mechanisms and BiLSTM encoders followed by CRF tagging layers. We describe a variety of experiments, showing that our approach obtains promising results on a dataset annotated with Dialogue Acts and Frame Semantics. Moreover, we demonstrate its applicability to a different, publicly available NLU dataset annotated with domain-specific intents and corresponding semantic roles, providing overall performance higher than state-of-the-art tools such as RASA, Dialogflow, LUIS, and Watson. For example, we show an average 4.45% improvement in entity tagging F-score over Rasa, Dialogflow and LUIS.
* 10 pages
MuMMER: Socially Intelligent Human-Robot Interaction in Public Spaces
Sep 15, 2019
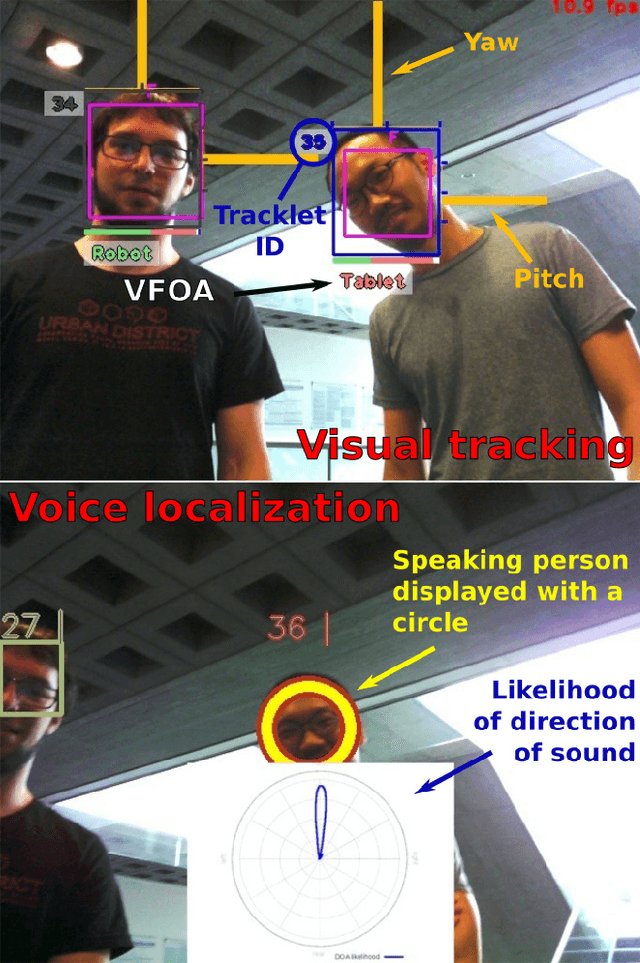

In the EU-funded MuMMER project, we have developed a social robot designed to interact naturally and flexibly with users in public spaces such as a shopping mall. We present the latest version of the robot system developed during the project. This system encompasses audio-visual sensing, social signal processing, conversational interaction, perspective taking, geometric reasoning, and motion planning. It successfully combines all these components in an overarching framework using the Robot Operating System (ROS) and has been deployed to a shopping mall in Finland interacting with customers. In this paper, we describe the system components, their interplay, and the resulting robot behaviours and scenarios provided at the shopping mall.
A Multi-layer LSTM-based Approach for Robot Command Interaction Modeling
Nov 13, 2018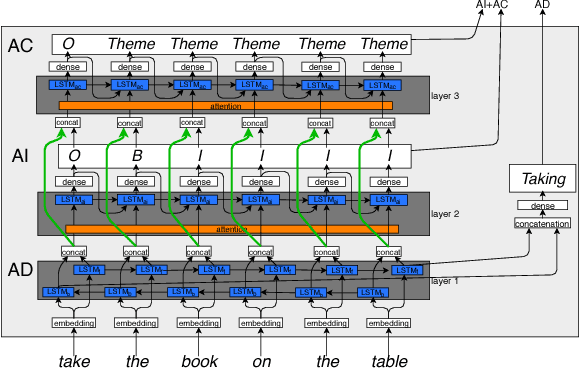
As the first robotic platforms slowly approach our everyday life, we can imagine a near future where service robots will be easily accessible by non-expert users through vocal interfaces. The capability of managing natural language would indeed speed up the process of integrating such platform in the ordinary life. Semantic parsing is a fundamental task of the Natural Language Understanding process, as it allows extracting the meaning of a user utterance to be used by a machine. In this paper, we present a preliminary study to semantically parse user vocal commands for a House Service robot, using a multi-layer Long-Short Term Memory neural network with attention mechanism. The system is trained on the Human Robot Interaction Corpus, and it is preliminarily compared with previous approaches.
Knowledge Representation for Robots through Human-Robot Interaction
Aug 01, 2013
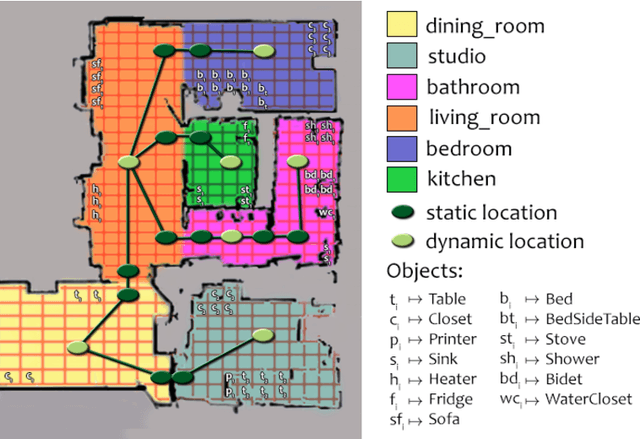
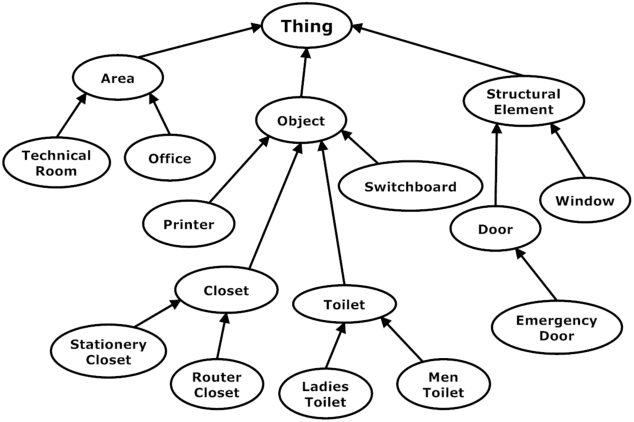
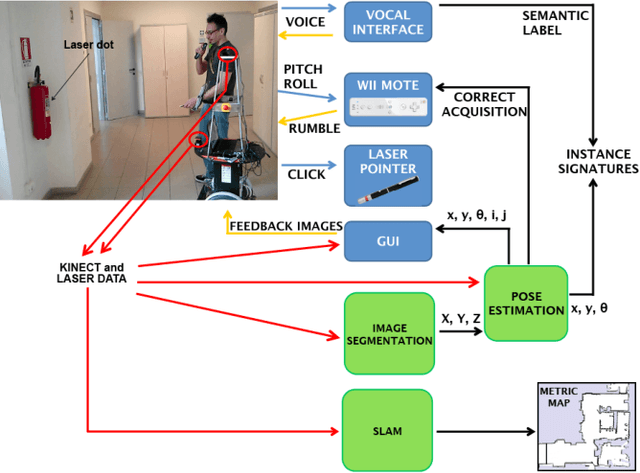
The representation of the knowledge needed by a robot to perform complex tasks is restricted by the limitations of perception. One possible way of overcoming this situation and designing "knowledgeable" robots is to rely on the interaction with the user. We propose a multi-modal interaction framework that allows to effectively acquire knowledge about the environment where the robot operates. In particular, in this paper we present a rich representation framework that can be automatically built from the metric map annotated with the indications provided by the user. Such a representation, allows then the robot to ground complex referential expressions for motion commands and to devise topological navigation plans to achieve the target locations.