 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissimilar Nodes Improve Graph Active Learning
Dec 05, 2022



Training labels for graph embedding algorithms could be costly to obtain in many practical scenarios. Active learning (AL) algorithms are very helpful to obtain the most useful labels for training while keeping the total number of label queries under a certain budget. The existing Active Graph Embedding framework proposes to use centrality score, density score, and entropy score to evaluate the value of unlabeled nodes, and it has been shown to be capable of bringing some improvement to the node classification tasks of Graph Convolutional Networks. However, when evaluating the importance of unlabeled nodes, it fails to consider the influence of existing labeled nodes on the value of unlabeled nodes. In other words, given the same unlabeled node, the computed informative score is always the same and is agnostic to the labeled node set. With the aim to address this limitation, in this work, we introduce 3 dissimilarity-based information scores for active learning: feature dissimilarity score (FDS), structure dissimilarity score (SDS), and embedding dissimilarity score (EDS). We find out that those three scores are able to take the influence of the labeled set on the value of unlabeled candidates into consideration, boosting our AL performance. According to experiments, our newly proposed scores boost the classification accuracy by 2.1% on average and are capable of generalizing to different Graph Neural Network architectures.
A Mobility-Aware Deep Learning Model for Long-Term COVID-19 Pandemic Prediction and Policy Impact Analysis
Dec 05, 2022



Pandemic(epidemic) modeling, aiming at disease spreading analysis, has always been a popular research topic especially following the outbreak of COVID-19 in 2019. Some representative models including SIR-based deep learning prediction models have shown satisfactory performance. However, one major drawback for them is that they fall short in their long-term predictive ability. Although graph convolutional networks (GCN) also perform well, their edge representations do not contain complete information and it can lead to biases. Another drawback is that they usually use input features which they are unable to predict. Hence, those models are unable to predict further future. We propose a model that can propagate predictions further into the future and it has better edge representations. In particular, we model the pandemic as a spatial-temporal graph whose edges represent the transition of infections and are learned by our model. We use a two-stream framework that contains GCN and recursive structures (GRU) with an attention mechanism. Our model enables mobility analysis that provides an effective toolbox for public health researchers and policy makers to predict how different lock-down strategies that actively control mobility can influence the spread of pandemics. Experiments show that our model outperforms others in its long-term predictive power. Moreover, we simulate the effects of certain policies and predict their impacts on infection control.
Prototypical Fine-tuning: Towards Robust Performance Under Varying Data Sizes
Nov 24, 2022



In this paper, we move towards combining large parametric models with non-parametric prototypical networks. We propose prototypical fine-tuning, a novel prototypical framework for fine-tuning pretrained language models (LM), which automatically learns a bias to improve predictive performance for varying data sizes, especially low-resource settings. Our prototypical fine-tuning approach can automatically adjust the model capacity according to the number of data points and the model's inherent attributes. Moreover, we propose four principles for effective prototype fine-tuning towards the optimal solution. Experimental results across various datasets show that our work achieves significant performance improvements under various low-resource settings, as well as comparable and usually better performances in high-resource scenarios.
Introducing Semantics into Speech Encoders
Nov 15, 2022



Recent studies find existing self-supervised speech encoders contain primarily acoustic rather than semantic information. As a result, pipelined supervised automatic speech recognition (ASR) to large language model (LLM) systems achieve state-of-the-art results on semantic spoken language tasks by utilizing rich semantic representations from the LLM. These systems come at the cost of labeled audio transcriptions, which is expensive and time-consuming to obtain. We propose a task-agnostic unsupervised way of incorporating semantic information from LLMs into self-supervised speech encoders without labeled audio transcriptions. By introducing semantics, we improve existing speech encoder spoken language understanding performance by over 10\% on intent classification, with modest gains in named entity resolution and slot filling, and spoken question answering FF1 score by over 2\%. Our unsupervised approach achieves similar performance as supervised methods trained on over 100 hours of labeled audio transcripts, demonstrating the feasibility of unsupervised semantic augmentations to existing speech encoders.
Empowering Language Models with Knowledge Graph Reasoning for Question Answering
Nov 15, 2022Answering open-domain questions requires world knowledge about in-context entities. As pre-trained Language Models (LMs) lack the power to store all required knowledge, external knowledge sources, such as knowledge graphs, are often used to augment LMs. In this work, we propose knOwledge REasOning empowered Language Model (OREO-LM), which consists of a novel Knowledge Interaction Layer that can be flexibly plugged into existing Transformer-based LMs to interact with a differentiable Knowledge Graph Reasoning module collaboratively. In this way, LM guides KG to walk towards the desired answer, while the retrieved knowledge improves LM. By adopting OREO-LM to RoBERTa and T5, we show significant performance gain, achieving state-of-art results in the Closed-Book setting. The performance enhancement is mainly from the KG reasoning's capacity to infer missing relational facts. In addition, OREO-LM provides reasoning paths as rationales to interpret the model's decision.
Code Recommendation for Open Source Software Developers
Oct 20, 2022
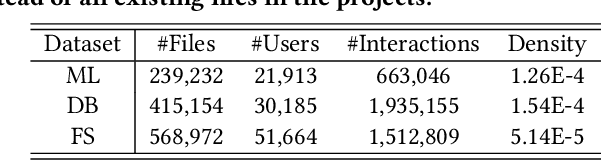
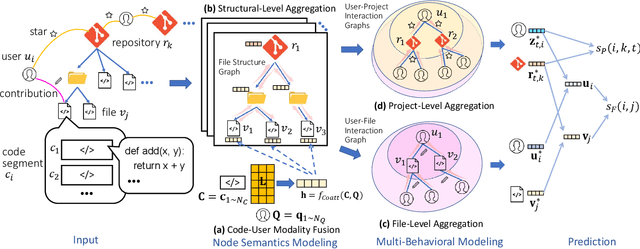
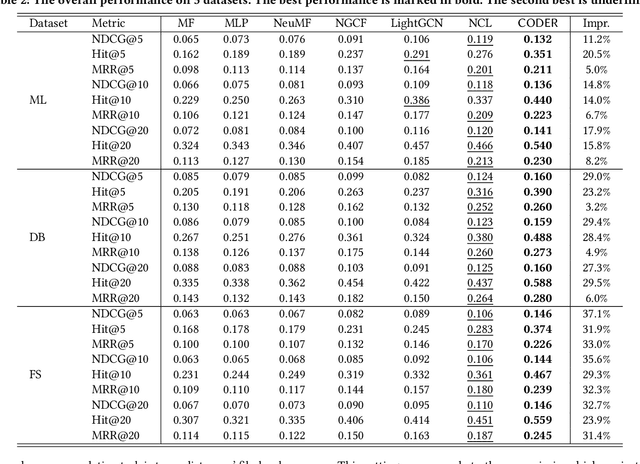
Open Source Software (OSS) is forming the spines of technology infrastructures, attracting millions of talents to contribute. Notably, it is challenging and critical to consider both the developers' interests and the semantic features of the project code to recommend appropriate development tasks to OSS developers. In this paper, we formulate the novel problem of code recommendation, whose purpose is to predict the future contribution behaviors of developers given their interaction history, the semantic features of source code, and the hierarchical file structures of projects. Considering the complex interactions among multiple parties within the system, we propose CODER, a novel graph-based code recommendation framework for open source software developers. CODER jointly models microscopic user-code interactions and macroscopic user-project interactions via a heterogeneous graph and further bridges the two levels of information through aggregation on file-structure graphs that reflect the project hierarchy. Moreover, due to the lack of reliable benchmarks, we construct three large-scale datasets to facilitate future research in this direction. Extensive experiments show that our CODER framework achieves superior performance under various experimental settings, including intra-project, cross-project, and cold-start recommendation. We will release all the datasets, code, and utilities for data retrieval upon the acceptance of this work.
Learning Probabilities of Causation from Finite Population Data
Oct 16, 2022
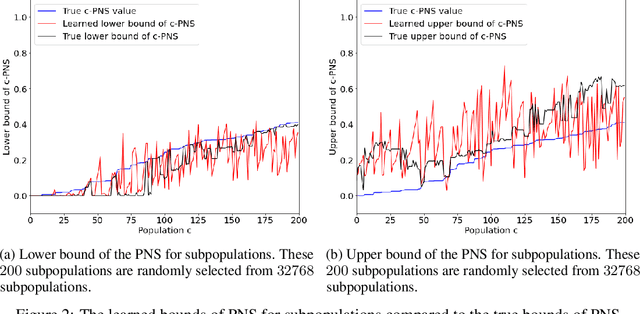
This paper deals with the problem of learning the probabilities of causation of subpopulations given finite population data. The tight bounds of three basic probabilities of causation, the probability of necessity and sufficiency (PNS), the probability of sufficiency (PS), and the probability of necessity (PN), were derived by Tian and Pearl. However, obtaining the bounds for each subpopulation requires experimental and observational distributions of each subpopulation, which is usually impractical to estimate given finite population data. We propose a machine learning model that helps to learn the bounds of the probabilities of causation for subpopulations given finite population data. We further show by a simulated study that the machine learning model is able to learn the bounds of PNS for 32768 subpopulations with only knowing roughly 500 of them from the finite population data.
Unit Selection: Learning Benefit Function from Finite Population Data
Oct 15, 2022
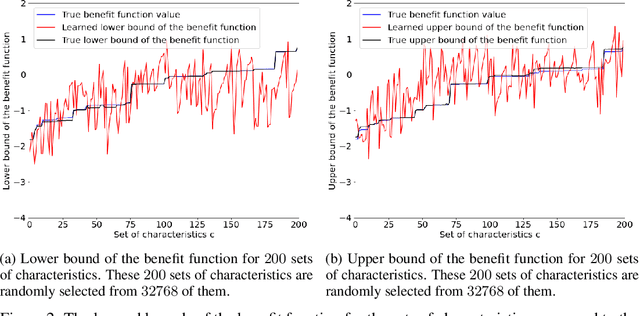
The unit selection problem is to identify a group of individuals who are most likely to exhibit a desired mode of behavior, for example, selecting individuals who would respond one way if incentivized and a different way if not. The unit selection problem consists of evaluation and search subproblems. Li and Pearl defined the "benefit function" to evaluate the average payoff of selecting a certain individual with given characteristics. The search subproblem is then to design an algorithm to identify the characteristics that maximize the above benefit function. The hardness of the search subproblem arises due to the large number of characteristics available for each individual and the sparsity of the data available in each cell of characteristics. In this paper, we present a machine learning framework that uses the bounds of the benefit function that are estimable from the finite population data to learn the bounds of the benefit function for each cell of characteristics. Therefore, we could easily obtain the characteristics that maximize the benefit function.
Dual-Geometric Space Embedding Model for Two-View Knowledge Graphs
Sep 19, 2022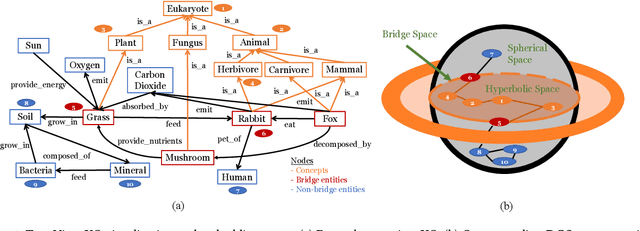
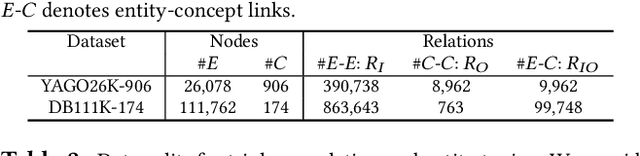
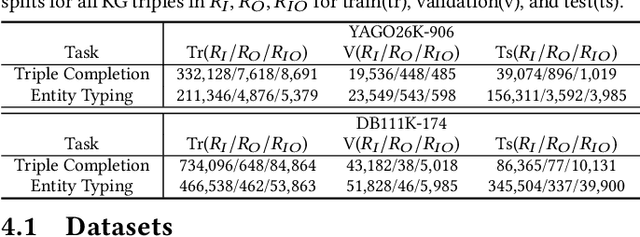
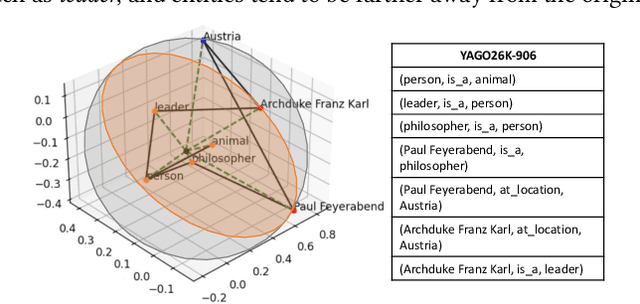
Two-view knowledge graphs (KGs) jointly represent two components: an ontology view for abstract and commonsense concepts, and an instance view for specific entities that are instantiated from ontological concepts. As such, these KGs contain heterogeneous structures that are hierarchical, from the ontology-view, and cyclical, from the instance-view. Despite these various structures in KGs, most recent works on embedding KGs assume that the entire KG belongs to only one of the two views but not both simultaneously. For works that seek to put both views of the KG together, the instance and ontology views are assumed to belong to the same geometric space, such as all nodes embedded in the same Euclidean space or non-Euclidean product space, an assumption no longer reasonable for two-view KGs where different portions of the graph exhibit different structures. To address this issue, we define and construct a dual-geometric space embedding model (DGS) that models two-view KGs using a complex non-Euclidean geometric space, by embedding different portions of the KG in different geometric spaces. DGS utilizes the spherical space, hyperbolic space, and their intersecting space in a unified framework for learning embeddings. Furthermore, for the spherical space, we propose novel closed spherical space operators that directly operate in the spherical space without the need for mapping to an approximate tangent space. Experiments on public datasets show that DGS significantly outperforms previous state-of-the-art baseline models on KG completion tasks, demonstrating its ability to better model heterogeneous structures in KGs.
Detecting Political Biases of Named Entities and Hashtags on Twitter
Sep 16, 2022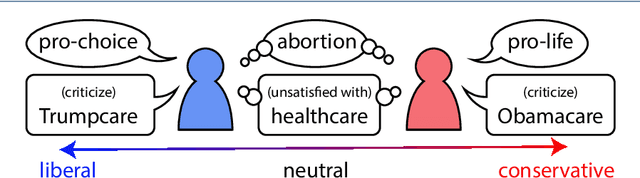

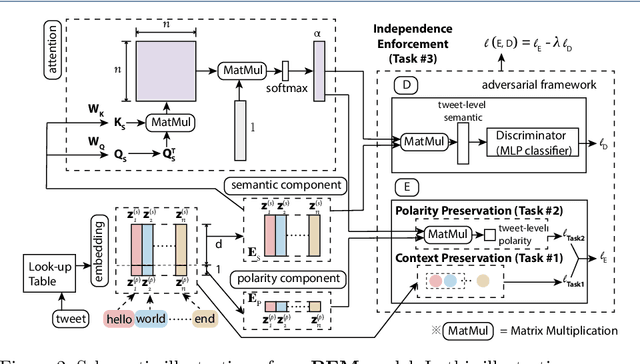
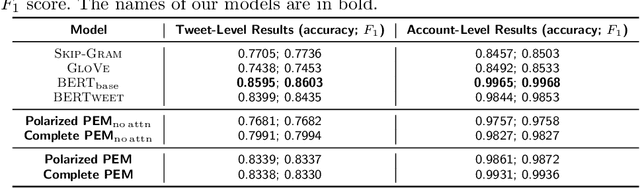
Ideological divisions in the United States have become increasingly prominent in daily communication. Accordingly, there has been much research on political polarization, including many recent efforts that take a computational perspective. By detecting political biases in a corpus of text, one can attempt to describe and discern the polarity of that text. Intuitively, the named entities (i.e., the nouns and phrases that act as nouns) and hashtags in text often carry information about political views. For example, people who use the term "pro-choice" are likely to be liberal, whereas people who use the term "pro-life" are likely to be conservative. In this paper, we seek to reveal political polarities in social-media text data and to quantify these polarities by explicitly assigning a polarity score to entities and hashtags. Although this idea is straightforward, it is difficult to perform such inference in a trustworthy quantitative way. Key challenges include the small number of known labels, the continuous spectrum of political views, and the preservation of both a polarity score and a polarity-neutral semantic meaning in an embedding vector of words. To attempt to overcome these challenges, we propose the Polarity-aware Embedding Multi-task learning (PEM) model. This model consists of (1) a self-supervised context-preservation task, (2) an attention-based tweet-level polarity-inference task, and (3) an adversarial learning task that promotes independence between an embedding's polarity dimension and its semantic dimensions. Our experimental results demonstrate that our PEM model can successfully learn polarity-aware embeddings. We examine a variety of applications and we thereby demonstrate the effectiveness of our PEM model. We also discuss important limitations of our work and stress caution when applying the PEM model to real-world scenarios.