 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Foreground Extraction via Deep Region Competition
Nov 09, 2021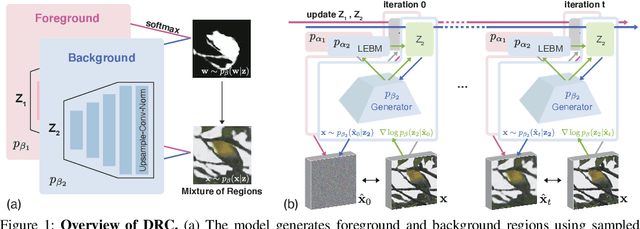
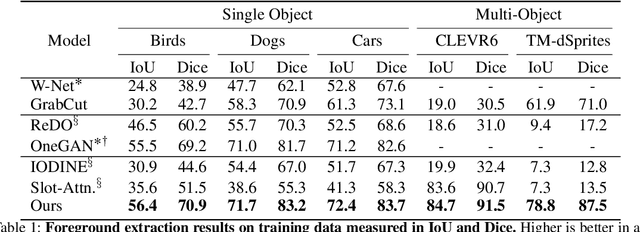
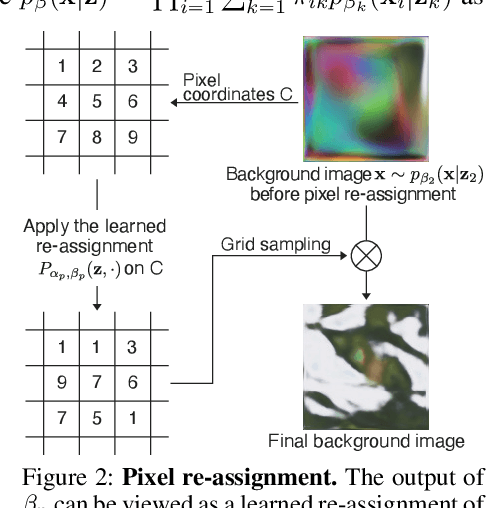
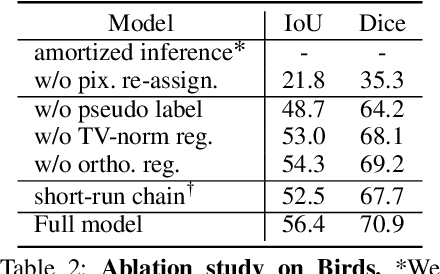
We present Deep Region Competition (DRC), an algorithm designed to extract foreground objects from images in a fully unsupervised manner. Foreground extraction can be viewed as a special case of generic image segmentation that focuses on identifying and disentangling objects from the background. In this work, we rethink the foreground extraction by reconciling energy-based prior with generative image modeling in the form of Mixture of Experts (MoE), where we further introduce the learned pixel re-assignment as the essential inductive bias to capture the regularities of background regions. With this modeling, the foreground-background partition can be naturally found through Expectation-Maximization (EM). We show that the proposed method effectively exploits the interaction between the mixture components during the partitioning process, which closely connects to region competition, a seminal approach for generic image segmentation. Experiments demonstrate that DRC exhibits more competitive performances on complex real-world data and challenging multi-object scenes compared with prior methods. Moreover, we show empirically that DRC can potentially generalize to novel foreground objects even from categories unseen during training.
YouRefIt: Embodied Reference Understanding with Language and Gesture
Sep 15, 2021
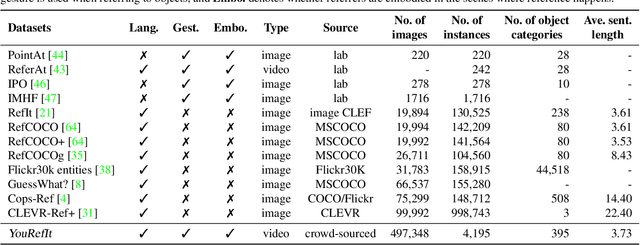

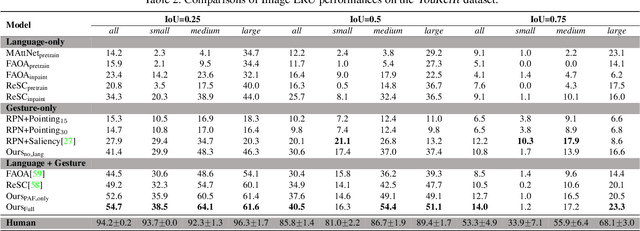
We study the understanding of embodied reference: One agent uses both language and gesture to refer to an object to another agent in a shared physical environment. Of note, this new visual task requires understanding multimodal cues with perspective-taking to identify which object is being referred to. To tackle this problem, we introduce YouRefIt, a new crowd-sourced dataset of embodied reference collected in various physical scenes; the dataset contains 4,195 unique reference clips in 432 indoor scenes. To the best of our knowledge, this is the first embodied reference dataset that allows us to study referring expressions in daily physical scenes to understand referential behavior, human communication, and human-robot interaction. We further devise two benchmarks for image-based and video-based embodied reference understanding. Comprehensive baselines and extensive experiments provide the very first result of machine perception on how the referring expressions and gestures affect the embodied reference understanding. Our results provide essential evidence that gestural cues are as critical as language cues in understanding the embodied reference.
Spatio-temporal Self-Supervised Representation Learning for 3D Point Clouds
Sep 01, 2021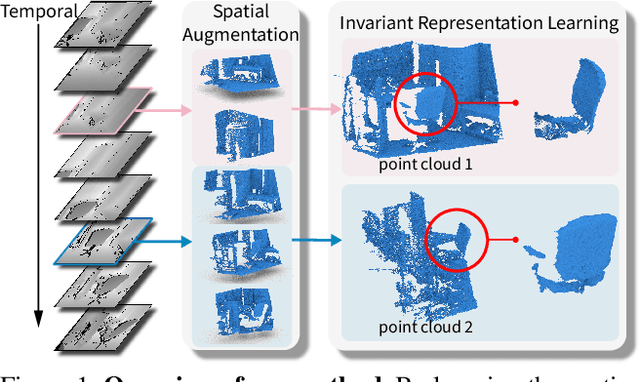
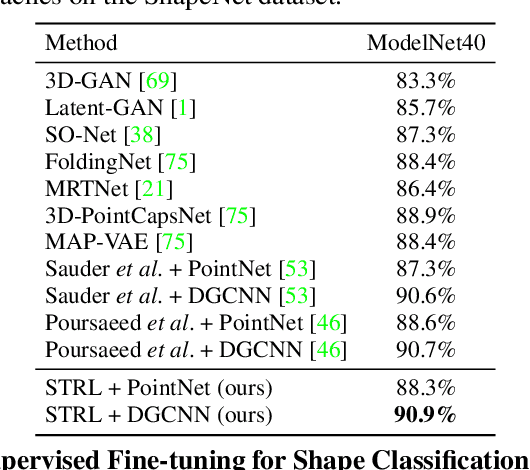
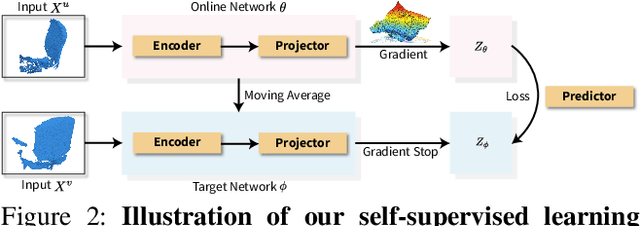
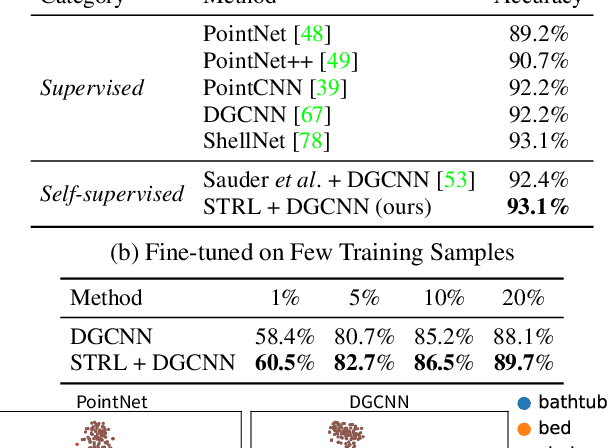
To date, various 3D scene understanding tasks still lack practical and generalizable pre-trained models, primarily due to the intricate nature of 3D scene understanding tasks and their immense variations introduced by camera views, lighting, occlusions, etc. In this paper, we tackle this challenge by introducing a spatio-temporal representation learning (STRL) framework, capable of learning from unlabeled 3D point clouds in a self-supervised fashion. Inspired by how infants learn from visual data in the wild, we explore the rich spatio-temporal cues derived from the 3D data. Specifically, STRL takes two temporally-correlated frames from a 3D point cloud sequence as the input, transforms it with the spatial data augmentation, and learns the invariant representation self-supervisedly. To corroborate the efficacy of STRL, we conduct extensive experiments on three types (synthetic, indoor, and outdoor) of datasets. Experimental results demonstrate that, compared with supervised learning methods, the learned self-supervised representation facilitates various models to attain comparable or even better performances while capable of generalizing pre-trained models to downstream tasks, including 3D shape classification, 3D object detection, and 3D semantic segmentation. Moreover, the spatio-temporal contextual cues embedded in 3D point clouds significantly improve the learned representations.
Consolidating Kinematic Models to Promote Coordinated Mobile Manipulations
Aug 10, 2021
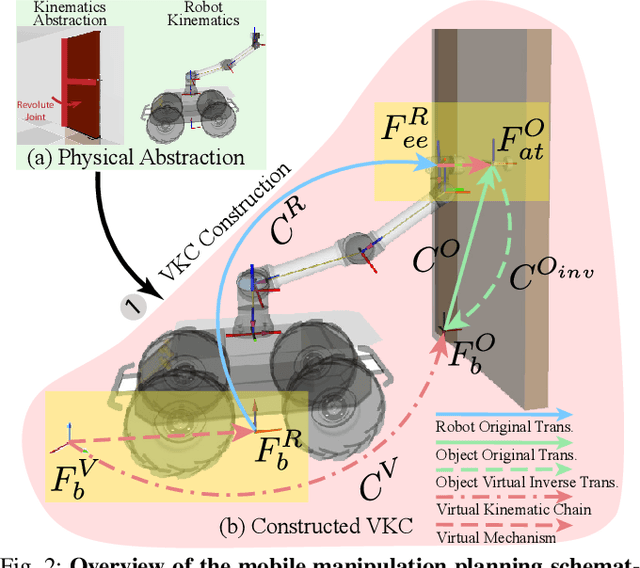
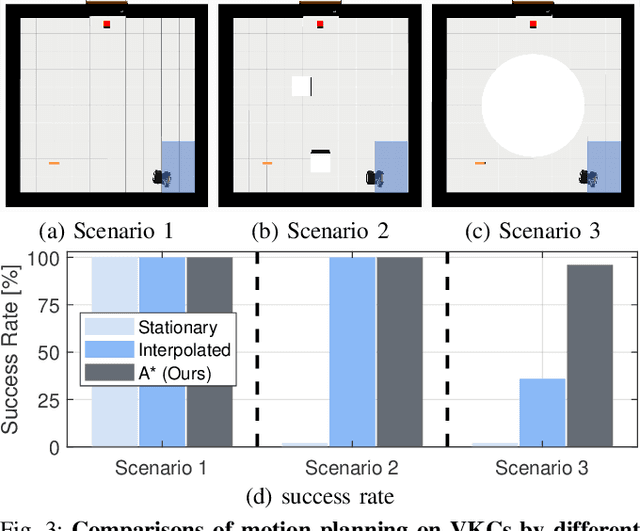
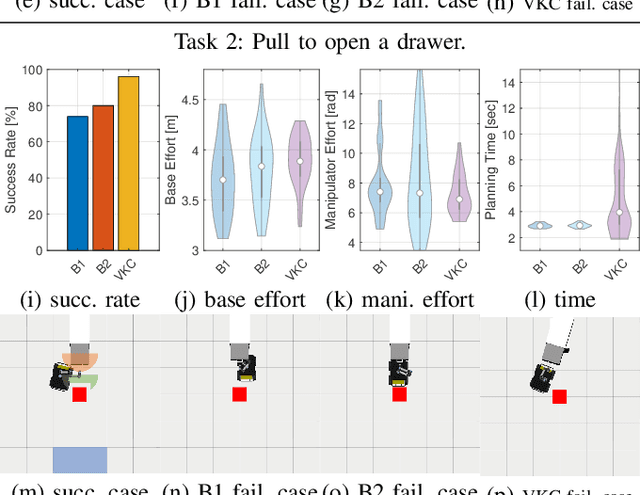
We construct a Virtual Kinematic Chain (VKC) that readily consolidates the kinematics of the mobile base, the arm, and the object to be manipulated in mobile manipulations. Accordingly, a mobile manipulation task is represented by altering the state of the constructed VKC, which can be converted to a motion planning problem, formulated, and solved by trajectory optimization. This new VKC perspective of mobile manipulation allows a service robot to (i) produce well-coordinated motions, suitable for complex household environments, and (ii) perform intricate multi-step tasks while interacting with multiple objects without an explicit definition of intermediate goals. In simulated experiments, we validate these advantages by comparing the VKC-based approach with baselines that solely optimize individual components. The results manifest that VKC-based joint modeling and planning promote task success rates and produce more efficient trajectories.
Communicative Learning with Natural Gestures for Embodied Navigation Agents with Human-in-the-Scene
Aug 05, 2021
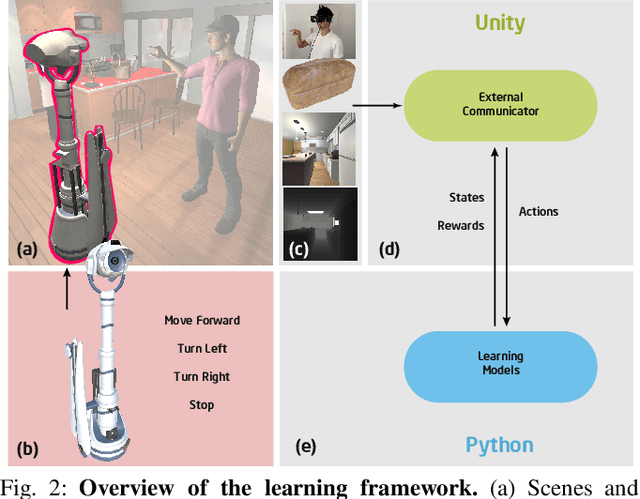
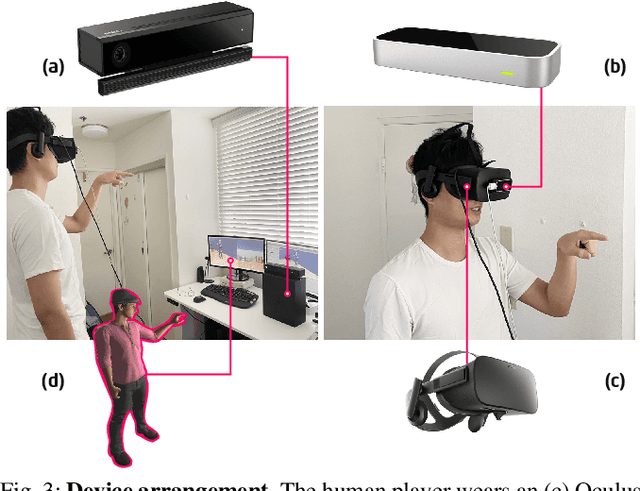
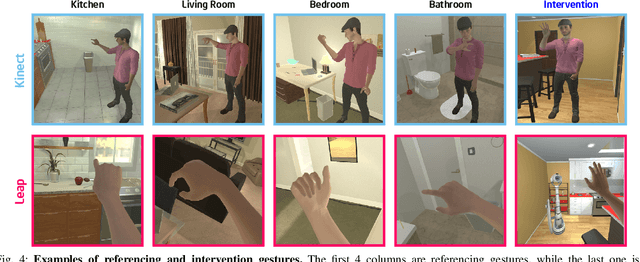
Human-robot collaboration is an essential research topic in artificial intelligence (AI), enabling researchers to devise cognitive AI systems and affords an intuitive means for users to interact with the robot. Of note, communication plays a central role. To date, prior studies in embodied agent navigation have only demonstrated that human languages facilitate communication by instructions in natural languages. Nevertheless, a plethora of other forms of communication is left unexplored. In fact, human communication originated in gestures and oftentimes is delivered through multimodal cues, e.g. "go there" with a pointing gesture. To bridge the gap and fill in the missing dimension of communication in embodied agent navigation, we propose investigating the effects of using gestures as the communicative interface instead of verbal cues. Specifically, we develop a VR-based 3D simulation environment, named Ges-THOR, based on AI2-THOR platform. In this virtual environment, a human player is placed in the same virtual scene and shepherds the artificial agent using only gestures. The agent is tasked to solve the navigation problem guided by natural gestures with unknown semantics; we do not use any predefined gestures due to the diversity and versatile nature of human gestures. We argue that learning the semantics of natural gestures is mutually beneficial to learning the navigation task--learn to communicate and communicate to learn. In a series of experiments, we demonstrate that human gesture cues, even without predefined semantics, improve the object-goal navigation for an embodied agent, outperforming various state-of-the-art methods.
Efficient Task Planning for Mobile Manipulation: a Virtual Kinematic Chain Perspective
Aug 03, 2021
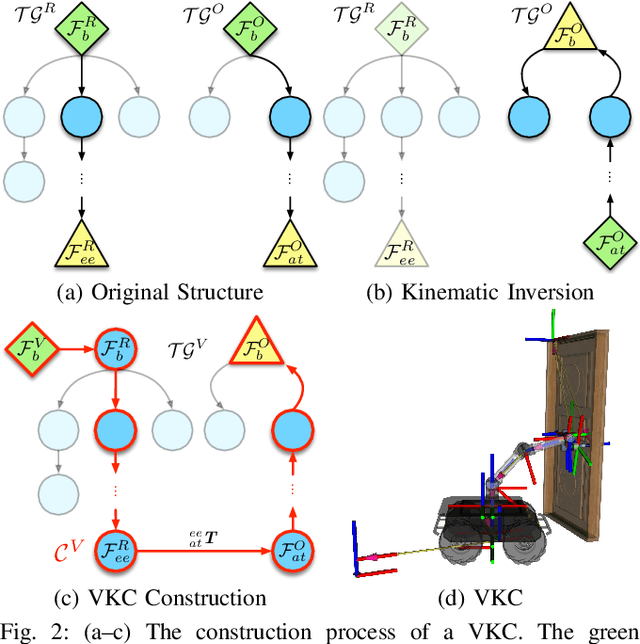
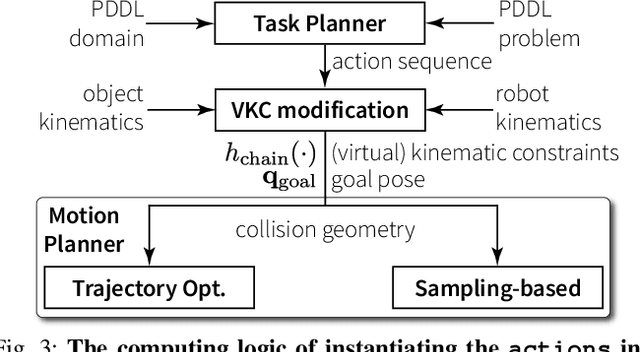
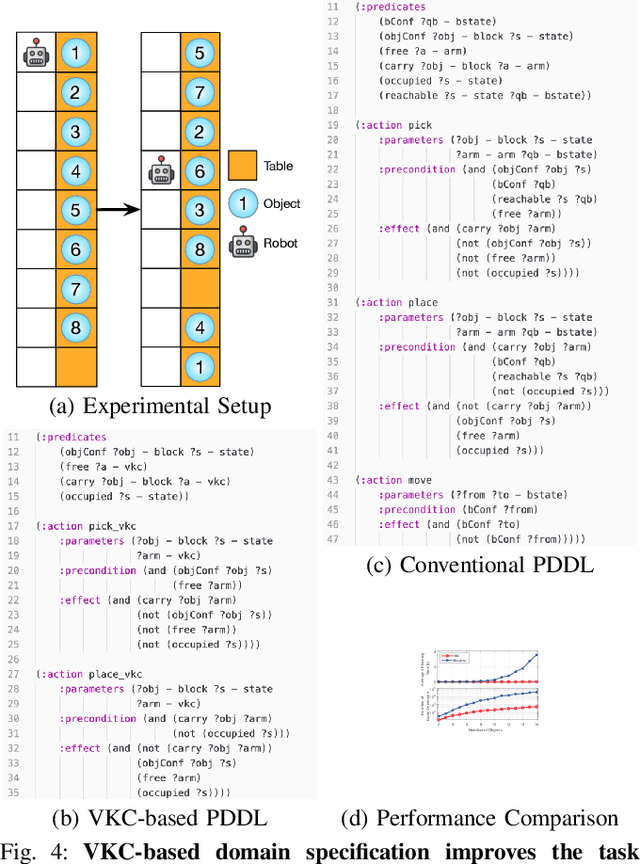
We present a Virtual Kinematic Chain (VKC) perspective, a simple yet effective method, to improve task planning efficacy for mobile manipulation. By consolidating the kinematics of the mobile base, the arm, and the object being manipulated collectively as a whole, this novel VKC perspective naturally defines abstract actions and eliminates unnecessary predicates in describing intermediate poses. As a result, these advantages simplify the design of the planning domain and significantly reduce the search space and branching factors in solving planning problems. In experiments, we implement a task planner using Planning Domain Definition Language (PDDL) with VKC. Compared with conventional domain definition, our VKC-based domain definition is more efficient in both planning time and memory. In addition, abstract actions perform better in producing feasible motion plans and trajectories. We further scale up the VKC-based task planner in complex mobile manipulation tasks. Taken together, these results demonstrate that task planning using VKC for mobile manipulation is not only natural and effective but also introduces new capabilities.
Individual vs. Joint Perception: a Pragmatic Model of Pointing as Communicative Smithian Helping
Jun 03, 2021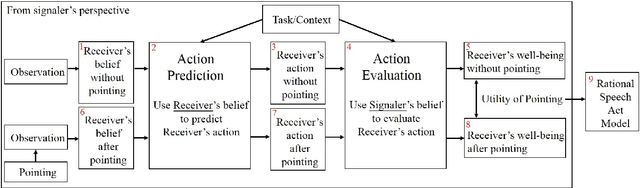
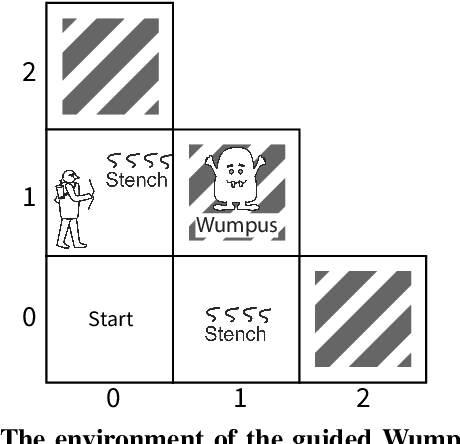
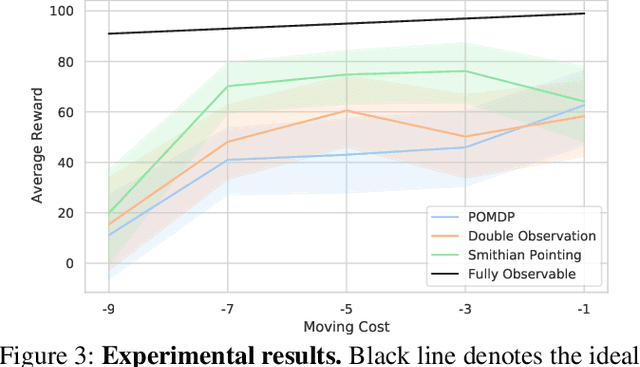
The simple gesture of pointing can greatly augment ones ability to comprehend states of the world based on observations. It triggers additional inferences relevant to ones task at hand. We model an agents update to its belief of the world based on individual observations using a partially observable Markov decision process (POMDP), a mainstream artificial intelligence (AI) model of how to act rationally according to beliefs formed through observation. On top of that, we model pointing as a communicative act between agents who have a mutual understanding that the pointed observation must be relevant and interpretable. Our model measures relevance by defining a Smithian Value of Information (SVI) as the utility improvement of the POMDP agent before and after receiving the pointing. We model that agents calculate SVI by using the cognitive theory of Smithian helping as a principle of coordinating separate beliefs for action prediction and action evaluation. We then import SVI into rational speech act (RSA) as the utility function of an utterance. These lead us to a pragmatic model of pointing allowing for contextually flexible interpretations. We demonstrate the power of our Smithian pointing model by extending the Wumpus world, a classic AI task where a hunter hunts a monster with only partial observability of the world. We add another agent as a guide who can only help by marking an observation already perceived by the hunter with a pointing or not, without providing new observations or offering any instrumental help. Our results show that this severely limited and overloaded communication nevertheless significantly improves the hunters performance. The advantage of pointing is indeed due to a computation of relevance based on Smithian helping, as it disappears completely when the task is too difficult or too easy for the guide to help.
Synthesizing Diverse and Physically Stable Grasps with Arbitrary Hand Structures by Differentiable Force Closure Estimation
Apr 19, 2021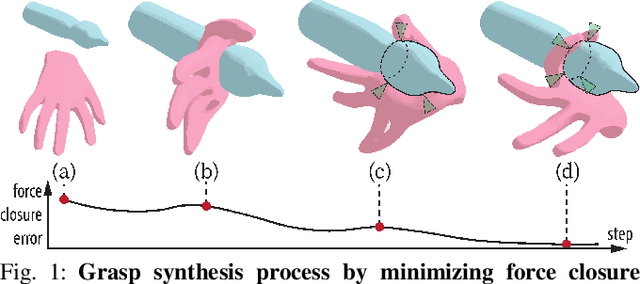

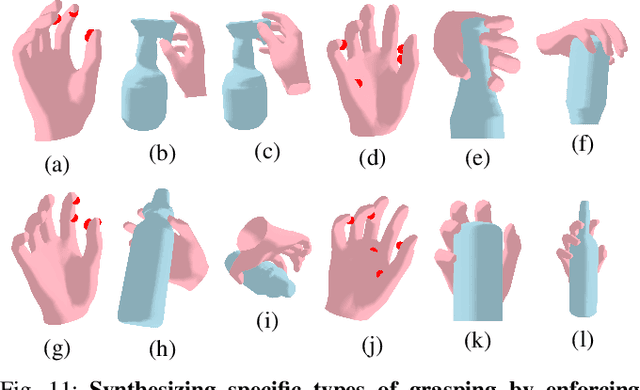
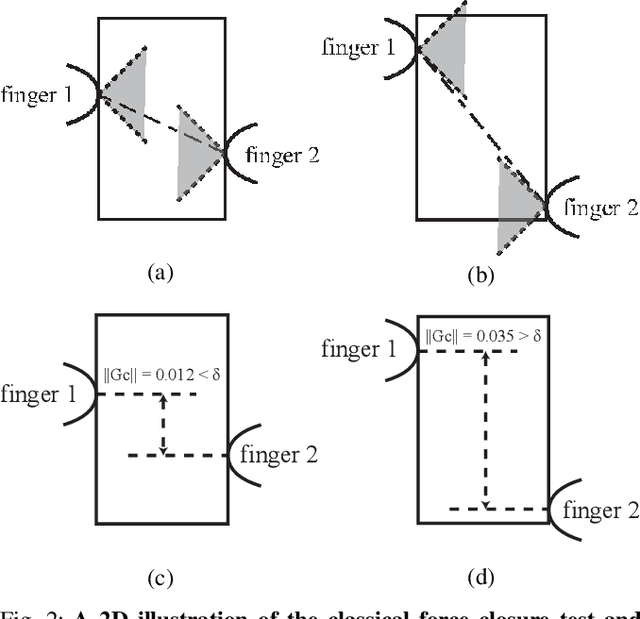
Existing grasp synthesis methods are either analytical or data-driven. The former one is oftentimes limited to specific application scope. The latter one depends heavily on demonstrations, thus suffers from generalization issues; e.g., models trained with human grasp data would be difficult to transfer to 3-finger grippers. To tackle these deficiencies, we formulate a fast and differentiable force closure estimation method, capable of producing diverse and physically stable grasps with arbitrary hand structures, without any training data. Although force closure has commonly served as a measure of grasp quality, it has not been widely adopted as an optimization objective for grasp synthesis primarily due to its high computational complexity; in comparison, the proposed differentiable method can test a force closure within 4ms. In experiments, we validate the proposed method's efficacy in 8 different settings.
Learning Triadic Belief Dynamics in Nonverbal Communication from Videos
Apr 07, 2021

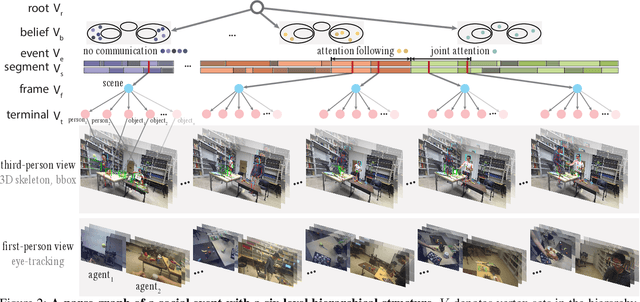
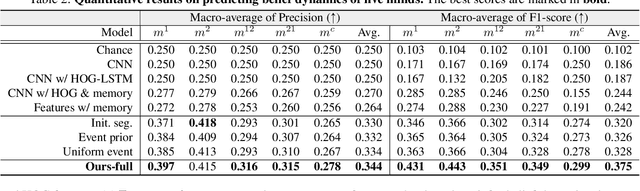
Humans possess a unique social cognition capability; nonverbal communication can convey rich social information among agents. In contrast, such crucial social characteristics are mostly missing in the existing scene understanding literature. In this paper, we incorporate different nonverbal communication cues (e.g., gaze, human poses, and gestures) to represent, model, learn, and infer agents' mental states from pure visual inputs. Crucially, such a mental representation takes the agent's belief into account so that it represents what the true world state is and infers the beliefs in each agent's mental state, which may differ from the true world states. By aggregating different beliefs and true world states, our model essentially forms "five minds" during the interactions between two agents. This "five minds" model differs from prior works that infer beliefs in an infinite recursion; instead, agents' beliefs are converged into a "common mind". Based on this representation, we further devise a hierarchical energy-based model that jointly tracks and predicts all five minds. From this new perspective, a social event is interpreted by a series of nonverbal communication and belief dynamics, which transcends the classic keyframe video summary. In the experiments, we demonstrate that using such a social account provides a better video summary on videos with rich social interactions compared with state-of-the-art keyframe video summary methods.
Reconstructing Interactive 3D Scenes by Panoptic Mapping and CAD Model Alignments
Mar 30, 2021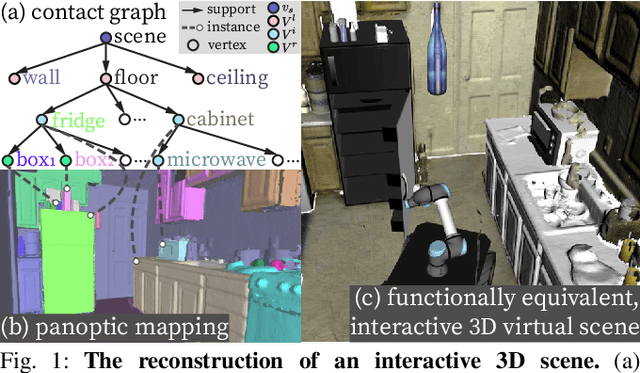
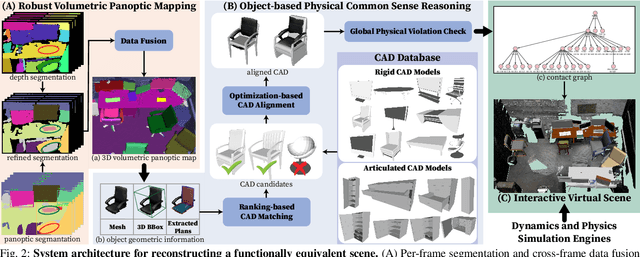
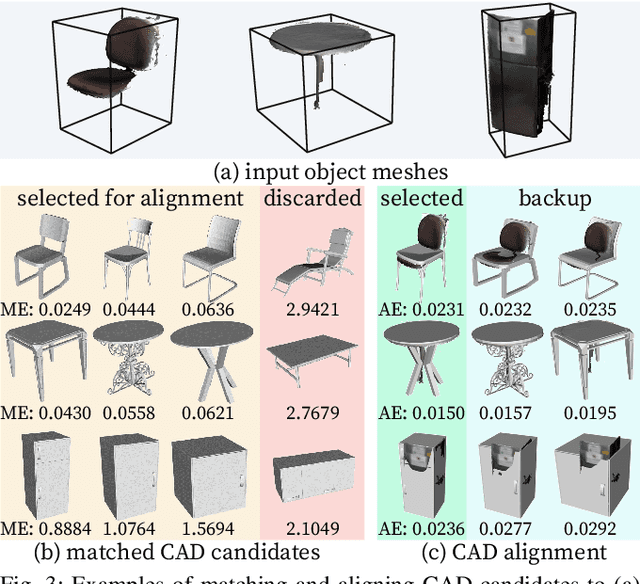
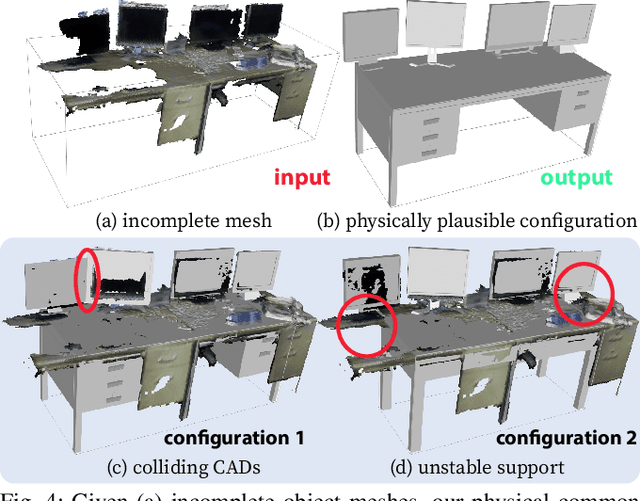
In this paper, we rethink the problem of scene reconstruction from an embodied agent's perspective: While the classic view focuses on the reconstruction accuracy, our new perspective emphasizes the underlying functions and constraints such that the reconstructed scenes provide \em{actionable} information for simulating \em{interactions} with agents. Here, we address this challenging problem by reconstructing an interactive scene using RGB-D data stream, which captures (i) the semantics and geometry of objects and layouts by a 3D volumetric panoptic mapping module, and (ii) object affordance and contextual relations by reasoning over physical common sense among objects, organized by a graph-based scene representation. Crucially, this reconstructed scene replaces the object meshes in the dense panoptic map with part-based articulated CAD models for finer-grained robot interactions. In the experiments, we demonstrate that (i) our panoptic mapping module outperforms previous state-of-the-art methods, (ii) a high-performant physical reasoning procedure that matches, aligns, and replaces objects' meshes with best-fitted CAD models, and (iii) reconstructed scenes are physically plausible and naturally afford actionable interactions; without any manual labeling, they are seamlessly imported to ROS-based simulators and virtual environments for complex robot task executions.