 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocraticPO: Policy Optimization via Interactive Guidance
Jun 03, 2026Reinforcement learning (RL) for large language models usually supervises reasoning with scalar outcome rewards, such as binary correctness. Such rewards provide an optimization direction but rarely explain how a model should revise its mistaken reasoning, which can encourage shortcut learning and brittle policies. We propose \textbf{SocraticPO} (Socratic Policy Optimization), a policy-optimization framework that augments RL rollouts with Socratic-style natural-language guidance. During rollout, the student first answers independently; if the answer is incorrect, a teacher diagnoses the attempt and provides concise corrective guidance, after which the student continues under the expanded context. Crucially, this guidance is paired with reward decay: correct answers obtained after teacher intervention only receive decayed rewards, preventing the policy from treating teacher help as a free path to reward. Since SocraticPO only modifies the rollout process while leaving the standard expected-reward objective intact, it can be plugged into existing policy-gradient backends such as Reinforce++. Moreover, because the teacher provides only text-level guidance, SocraticPO can leverage stronger black-box teacher models without requiring access to logits or distribution matching. On undergraduate-level scientific reasoning benchmarks from SciKnowEval, SocraticPO improves over strong RL and self-distillation baselines. Ablations show that both targeted guidance and reward decay are necessary, with reward decay mitigating reliance on assisted correction.
PaperScout: An Autonomous Agent for Academic Paper Search with Process-Aware Sequence-Level Policy Optimization
Jan 15, 2026Academic paper search is a fundamental task in scientific research, yet most existing approaches rely on rigid, predefined workflows that struggle with complex, conditional queries. To address this limitation, we propose PaperScout, an autonomous agent that reformulates paper search as a sequential decision-making process. Unlike static workflows, PaperScout dynamically decides whether, when, and how to invoke search and expand tools based on accumulated retrieval context. However, training such agents presents a fundamental challenge: standard reinforcement learning methods, typically designed for single-turn tasks, suffer from a granularity mismatch when applied to multi-turn agentic tasks, where token-level optimization diverges from the granularity of sequence-level interactions, leading to noisy credit assignment. We introduce Proximal Sequence Policy Optimization (PSPO), a process-aware, sequence-level policy optimization method that aligns optimization with agent-environment interaction. Comprehensive experiments on both synthetic and real-world benchmarks demonstrate that PaperScout significantly outperforms strong workflow-driven and RL baselines in both recall and relevance, validating the effectiveness of our adaptive agentic framework and optimization strategy.
Time Series Forecasting as Reasoning: A Slow-Thinking Approach with Reinforced LLMs
Jun 12, 2025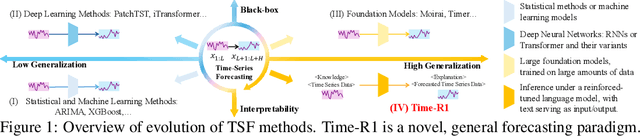

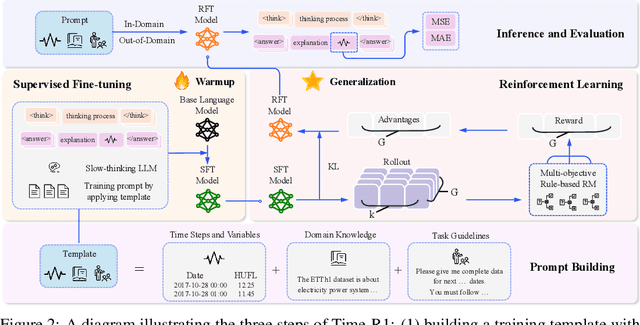
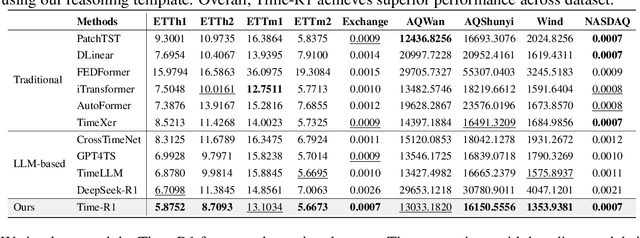
To advance time series forecasting (TSF), various methods have been proposed to improve prediction accuracy, evolving from statistical techniques to data-driven deep learning architectures. Despite their effectiveness, most existing methods still adhere to a fast thinking paradigm-relying on extracting historical patterns and mapping them to future values as their core modeling philosophy, lacking an explicit thinking process that incorporates intermediate time series reasoning. Meanwhile, emerging slow-thinking LLMs (e.g., OpenAI-o1) have shown remarkable multi-step reasoning capabilities, offering an alternative way to overcome these issues. However, prompt engineering alone presents several limitations - including high computational cost, privacy risks, and limited capacity for in-depth domain-specific time series reasoning. To address these limitations, a more promising approach is to train LLMs to develop slow thinking capabilities and acquire strong time series reasoning skills. For this purpose, we propose Time-R1, a two-stage reinforcement fine-tuning framework designed to enhance multi-step reasoning ability of LLMs for time series forecasting. Specifically, the first stage conducts supervised fine-tuning for warmup adaptation, while the second stage employs reinforcement learning to improve the model's generalization ability. Particularly, we design a fine-grained multi-objective reward specifically for time series forecasting, and then introduce GRIP (group-based relative importance for policy optimization), which leverages non-uniform sampling to further encourage and optimize the model's exploration of effective reasoning paths. Experiments demonstrate that Time-R1 significantly improves forecast performance across diverse datasets.
Multimodal Forecasting of Sparse Intraoperative Hypotension Events Powered by Language Model
May 28, 2025Intraoperative hypotension (IOH) frequently occurs under general anesthesia and is strongly linked to adverse outcomes such as myocardial injury and increased mortality. Despite its significance, IOH prediction is hindered by event sparsity and the challenge of integrating static and dynamic data across diverse patients. In this paper, we propose \textbf{IOHFuseLM}, a multimodal language model framework. To accurately identify and differentiate sparse hypotensive events, we leverage a two-stage training strategy. The first stage involves domain adaptive pretraining on IOH physiological time series augmented through diffusion methods, thereby enhancing the model sensitivity to patterns associated with hypotension. Subsequently, task fine-tuning is performed on the original clinical dataset to further enhance the ability to distinguish normotensive from hypotensive states. To enable multimodal fusion for each patient, we align structured clinical descriptions with the corresponding physiological time series at the token level. Such alignment enables the model to capture individualized temporal patterns alongside their corresponding clinical semantics. In addition, we convert static patient attributes into structured text to enrich personalized information. Experimental evaluations on two intraoperative datasets demonstrate that IOHFuseLM outperforms established baselines in accurately identifying IOH events, highlighting its applicability in clinical decision support scenarios. Our code is publicly available to promote reproducibility at https://github.com/zjt-gpu/IOHFuseLM.
Hierarchical Multimodal LLMs with Semantic Space Alignment for Enhanced Time Series Classification
Oct 24, 2024



Leveraging large language models (LLMs) has garnered increasing attention and introduced novel perspectives in time series classification. However, existing approaches often overlook the crucial dynamic temporal information inherent in time series data and face challenges in aligning this data with textual semantics. To address these limitations, we propose HiTime, a hierarchical multi-modal model that seamlessly integrates temporal information into LLMs for multivariate time series classification (MTSC). Our model employs a hierarchical feature encoder to capture diverse aspects of time series data through both data-specific and task-specific embeddings. To facilitate semantic space alignment between time series and text, we introduce a dual-view contrastive alignment module that bridges the gap between modalities. Additionally, we adopt a hybrid prompting strategy to fine-tune the pre-trained LLM in a parameter-efficient manner. By effectively incorporating dynamic temporal features and ensuring semantic alignment, HiTime enables LLMs to process continuous time series data and achieves state-of-the-art classification performance through text generation. Extensive experiments on benchmark datasets demonstrate that HiTime significantly enhances time series classification accuracy compared to most competitive baseline methods. Our findings highlight the potential of integrating temporal features into LLMs, paving the way for advanced time series analysis. The code is publicly available for further research and validation. Our codes are publicly available1.
ConvTimeNet: A Deep Hierarchical Fully Convolutional Model for Multivariate Time Series Analysis
Mar 03, 2024



This paper introduces ConvTimeNet, a novel deep hierarchical fully convolutional network designed to serve as a general-purpose model for time series analysis. The key design of this network is twofold, designed to overcome the limitations of traditional convolutional networks. Firstly, we propose an adaptive segmentation of time series into sub-series level patches, treating these as fundamental modeling units. This setting avoids the sparsity semantics associated with raw point-level time steps. Secondly, we design a fully convolutional block by skillfully integrating deepwise and pointwise convolution operations, following the advanced building block style employed in Transformer encoders. This backbone network allows for the effective capture of both global sequence and cross-variable dependence, as it not only incorporates the advancements of Transformer architecture but also inherits the inherent properties of convolution. Furthermore, multi-scale representations of given time series instances can be learned by controlling the kernel size flexibly. Extensive experiments are conducted on both time series forecasting and classification tasks. The results consistently outperformed strong baselines in most situations in terms of effectiveness.The code is publicly available.