 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Series Forecasting as Reasoning: A Slow-Thinking Approach with Reinforced LLMs
Paper and Code
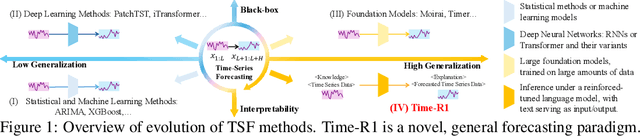

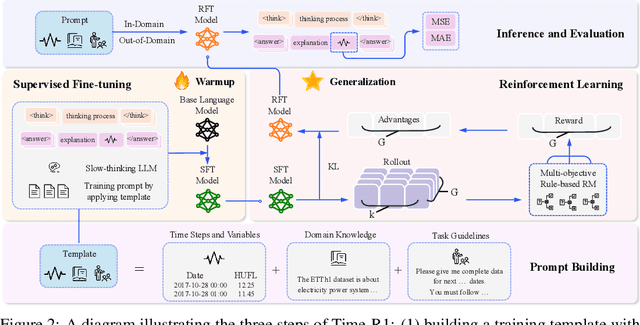
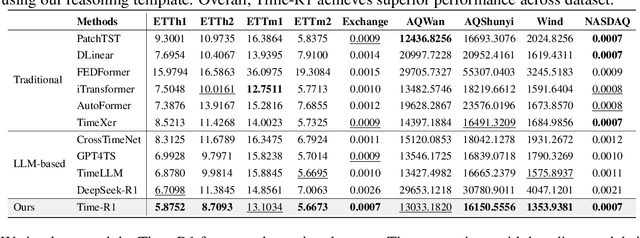
To advance time series forecasting (TSF), various methods have been proposed to improve prediction accuracy, evolving from statistical techniques to data-driven deep learning architectures. Despite their effectiveness, most existing methods still adhere to a fast thinking paradigm-relying on extracting historical patterns and mapping them to future values as their core modeling philosophy, lacking an explicit thinking process that incorporates intermediate time series reasoning. Meanwhile, emerging slow-thinking LLMs (e.g., OpenAI-o1) have shown remarkable multi-step reasoning capabilities, offering an alternative way to overcome these issues. However, prompt engineering alone presents several limitations - including high computational cost, privacy risks, and limited capacity for in-depth domain-specific time series reasoning. To address these limitations, a more promising approach is to train LLMs to develop slow thinking capabilities and acquire strong time series reasoning skills. For this purpose, we propose Time-R1, a two-stage reinforcement fine-tuning framework designed to enhance multi-step reasoning ability of LLMs for time series forecasting. Specifically, the first stage conducts supervised fine-tuning for warmup adaptation, while the second stage employs reinforcement learning to improve the model's generalization ability. Particularly, we design a fine-grained multi-objective reward specifically for time series forecasting, and then introduce GRIP (group-based relative importance for policy optimization), which leverages non-uniform sampling to further encourage and optimize the model's exploration of effective reasoning paths. Experiments demonstrate that Time-R1 significantly improves forecast performance across diverse datasets.