 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV2UV: Generating High-quality UV Texture Maps with Multiview Prompts
Mar 16, 2026Generating high-quality textures for 3D assets is a challenging task. Existing multiview texture generation methods suffer from the multiview inconsistency and missing textures on unseen parts, while UV inpainting texture methods do not generalize well due to insufficient UV data and cannot well utilize 2D image diffusion priors. In this paper, we propose a new method called MV2UV that combines 2D generative priors from multiview generation and the inpainting ability of UV refinement to get high-quality texture maps. Our key idea is to adopt a UV space generative model that simultaneously inpaints unseen parts of multiview images while resolving the inconsistency of multiview images. Experiments show that our method enables a better texture generation quality than existing methods, especially in unseen occluded and multiview-inconsistent parts.
Parameter Estimation based Automatic Modulation Recognition for Radio Frequency Signal
Dec 11, 2024



Automatic modulation recognition (AMR) critically contributes to spectrum sensing, dynamic spectrum access, and intelligent communications in cognitive radio systems. The introduction of deep learning has greatly improved the accuracy of AMR. However, current automatic identification methods require the input of key parameters such as the carrier frequency, which is necessary to convert the radio frequency (RF) to a base-band signal before it can be used for identification. In addition, the high complexity of deep learning models leads to high computational effort and long recognition times of existing methods, which are difficult to implement in demodulation system deployments. To address the above issues, in this paper, we first use power spectrum analysis to estimate the carrier frequency and signal bandwidth, which realizes the effective conversion from RF signals to base-band signals. This paper chooses the long short-term memory (LSTM) network as the model for automatic identification, which has low implementation complexity while maintaining high accuracy. Finally, by training the LSTM with actual sampling data combined with parameter estimation (PE), the method proposed in this paper can guarantee more than 90% format recognition accuracy.
Transfer Learning Guided Noise Reduction for Automatic Modulation Classification
Nov 13, 2024



Automatic modulation classification (AMC) has emerged as a key technique in cognitive radio networks in sixth-generation (6G) communications. AMC enables effective data transmission without requiring prior knowledge of modulation schemes. However, the low classification accuracy under the condition of low signal-to-noise ratio (SNR) limits the implementation of AMC techniques under the rapidly changing physical channels in 6G and beyond. This paper investigates the AMC technique for the signals with dynamic and varying SNRs, and a deep learning based noise reduction network is proposed to reduce the noise introduced by the wireless channel and the receiving equipment. In particular, a transfer learning guided learning framework (TNR-AMC) is proposed to utilize the scarce annotated modulation signals and improve the classification accuracy for low SNR modulation signals. The numerical results show that the proposed noise reduction network achieves an accuracy improvement of over 20\% in low SNR scenarios, and the TNR-AMC framework can improve the classification accuracy under unstable SNRs.
Spatial Shortcut Network for Human Pose Estimation
Apr 05, 2019
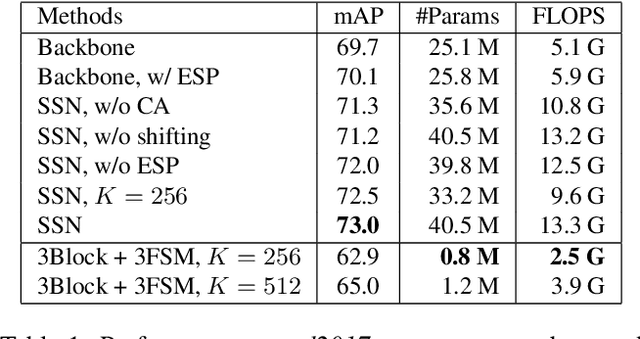
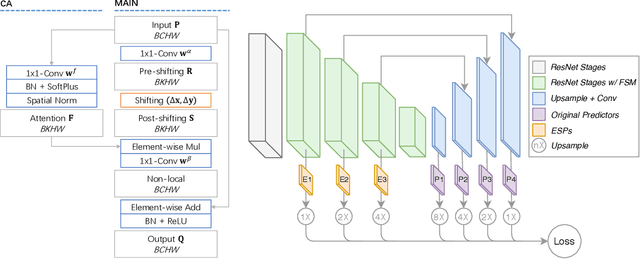

Like many computer vision problems, human pose estimation is a challenging problem in that recognizing a body part requires not only information from local area but also from areas with large spatial distance. In order to spatially pass information, large convolutional kernels and deep layers have been normally used, introducing high computation cost and large parameter space. Luckily for pose estimation, human body is geometrically structured in images, enabling modeling of spatial dependency. In this paper, we propose a spatial shortcut network for pose estimation task, where information is easier to flow spatially. We evaluate our model with detailed analyses and present its outstanding performance with smaller structure.
Learning deep representation from coarse to fine for face alignment
Jul 31, 2016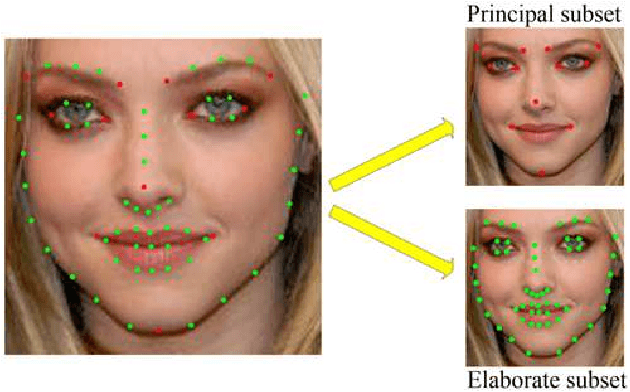
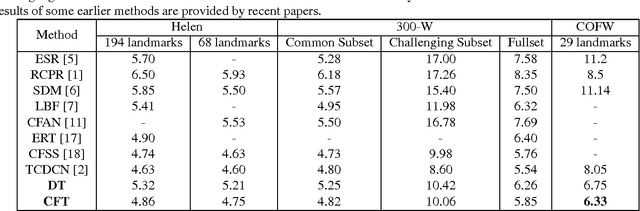
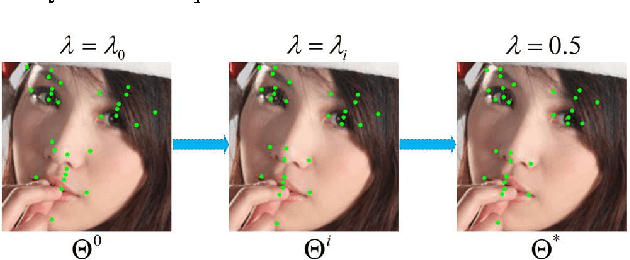
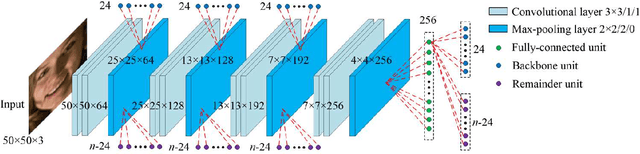
In this paper, we propose a novel face alignment method that trains deep convolutional network from coarse to fine. It divides given landmarks into principal subset and elaborate subset. We firstly keep a large weight for principal subset to make our network primarily predict their locations while slightly take elaborate subset into account. Next the weight of principal subset is gradually decreased until two subsets have equivalent weights. This process contributes to learn a good initial model and search the optimal model smoothly to avoid missing fairly good intermediate models in subsequent procedures. On the challenging COFW dataset [1], our method achieves 6.33% mean error with a reduction of 21.37% compared with the best previous result [2].