 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAMI: Training-Free Bias Mitigation in GUI Grounding
May 07, 2026GUI grounding is a critical capability for enabling GUI agents to execute tasks such as clicking and dragging. However, in complex scenarios like the ScreenSpot-Pro benchmark, existing models often suffer from suboptimal performance. Utilizing the proposed \textbf{Masked Prediction Distribution (MPD)} attribution method, we identify that the primary sources of errors are twofold: high image resolution (leading to precision bias) and intricate interface elements (resulting in ambiguity bias). To address these challenges, we introduce \textbf{Bias-Aware Manipulation Inference (BAMI)}, which incorporates two key manipulations, coarse-to-fine focus and candidate selection, to effectively mitigate these biases. Our extensive experimental results demonstrate that BAMI significantly enhances the accuracy of various GUI grounding models in a training-free setting. For instance, applying our method to the TianXi-Action-7B model boosts its accuracy on the ScreenSpot-Pro benchmark from 51.9\% to 57.8\%. Furthermore, ablation studies confirm the robustness of the BAMI approach across diverse parameter configurations, highlighting its stability and effectiveness. Code is available at https://github.com/Neur-IO/BAMI.
AdaZoom-GUI: Adaptive Zoom-based GUI Grounding with Instruction Refinement
Mar 18, 2026GUI grounding is a critical capability for vision-language models (VLMs) that enables automated interaction with graphical user interfaces by locating target elements from natural language instructions. However, grounding on GUI screenshots remains challenging due to high-resolution images, small UI elements, and ambiguous user instructions. In this work, we propose AdaZoom-GUI, an adaptive zoom-based GUI grounding framework that improves both localization accuracy and instruction understanding. Our approach introduces an instruction refinement module that rewrites natural language commands into explicit and detailed descriptions, allowing the grounding model to focus on precise element localization. In addition, we design a conditional zoom-in strategy that selectively performs a second-stage inference on predicted small elements, improving localization accuracy while avoiding unnecessary computation and context loss on simpler cases. To support this framework, we construct a high-quality GUI grounding dataset and train the grounding model using Group Relative Policy Optimization (GRPO), enabling the model to predict both click coordinates and element bounding boxes. Experiments on public benchmarks demonstrate that our method achieves state-of-the-art performance among models with comparable or even larger parameter sizes, highlighting its effectiveness for high-resolution GUI understanding and practical GUI agent deployment.
Nuanced Emotion Recognition Based on a Segment-based MLLM Framework Leveraging Qwen3-Omni for AH Detection
Mar 12, 2026Emotion recognition in videos is a pivotal task in affective computing, where identifying subtle psychological states such as Ambivalence and Hesitancy holds significant value for behavioral intervention and digital health. Ambivalence and Hesitancy states often manifest through cross-modal inconsistencies such as discrepancies between facial expressions, vocal tones, and textual semantics, posing a substantial challenge for automated recognition. This paper proposes a recognition framework that integrates temporal segment modeling with Multimodal Large Language Models. To address computational efficiency and token constraints in long video processing, we employ a segment-based strategy, partitioning videos into short clips with a maximum duration of 5 seconds. We leverage the Qwen3-Omni-30B-A3B model, fine-tuned on the BAH dataset using LoRA and full-parameter strategies via the MS-Swift framework, enabling the model to synergistically analyze visual and auditory signals. Experimental results demonstrate that the proposed method achieves an accuracy of 85.1% on the test set, significantly outperforming existing benchmarks and validating the superior capability of Multimodal Large Language Models in capturing complex and nuanced emotional conflicts. The code is released at https://github.com/dlnn123/A-H-Detection-with-Qwen-Omni.git.
SEA: Self-Evolution Agent with Step-wise Reward for Computer Use
Aug 06, 2025Computer use agent is an emerging area in artificial intelligence that aims to operate the computers to achieve the user's tasks, which attracts a lot of attention from both industry and academia. However, the present agents' performance is far from being used. In this paper, we propose the Self-Evolution Agent (SEA) for computer use, and to develop this agent, we propose creative methods in data generation, reinforcement learning, and model enhancement. Specifically, we first propose an automatic pipeline to generate the verifiable trajectory for training. And then, we propose efficient step-wise reinforcement learning to alleviate the significant computational requirements for long-horizon training. In the end, we propose the enhancement method to merge the grounding and planning ability into one model without any extra training. Accordingly, based on our proposed innovation of data generation, training strategy, and enhancement, we get the Selfevolution Agent (SEA) for computer use with only 7B parameters, which outperforms models with the same number of parameters and has comparable performance to larger ones. We will make the models' weight and related codes open-source in the future.
Enhancing binary classification: A new stacking method via leveraging computational geometry
Oct 30, 2024



Stacking, a potent ensemble learning method, leverages a meta-model to harness the strengths of multiple base models, thereby enhancing prediction accuracy. Traditional stacking techniques typically utilize established learning models, such as logistic regression, as the meta-model. This paper introduces a novel approach that integrates computational geometry techniques, specifically solving the maximum weighted rectangle problem, to develop a new meta-model for binary classification. Our method is evaluated on multiple open datasets, with statistical analysis showing its stability and demonstrating improvements in accuracy compared to current state-of-the-art stacking methods with out-of-fold predictions. This new stacking method also boasts two significant advantages: enhanced interpretability and the elimination of hyperparameter tuning for the meta-model, thus increasing its practicality. These merits make our method highly applicable not only in stacking ensemble learning but also in various real-world applications, such as hospital health evaluation scoring and bank credit scoring systems, offering a fresh evaluation perspective.
The Winning Solution to the iFLYTEK Challenge 2021 Cultivated Land Extraction from High-Resolution Remote Sensing Image
Feb 25, 2022
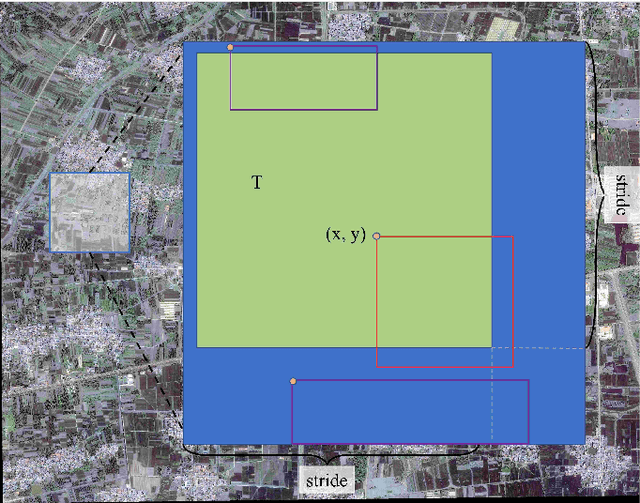
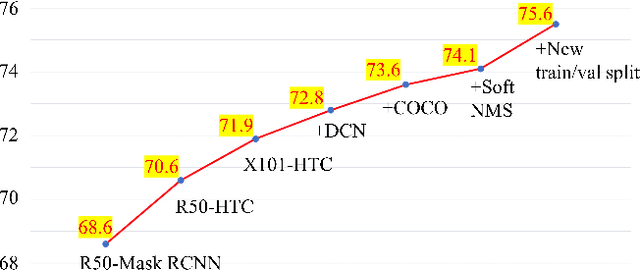
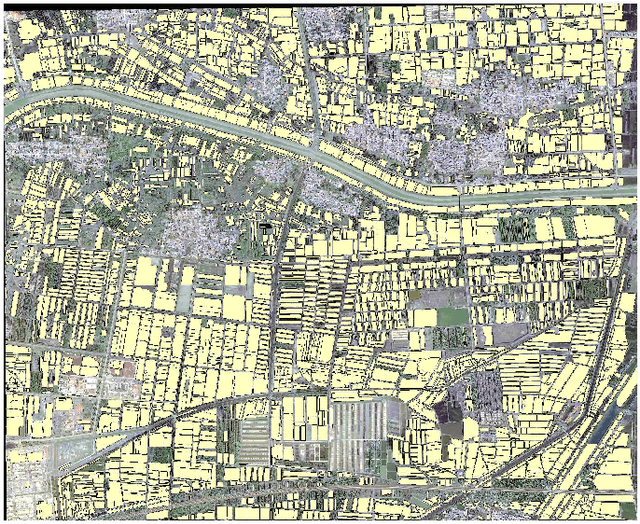
Extracting cultivated land accurately from high-resolution remote images is a basic task for precision agriculture. This report introduces our solution to the iFLYTEK challenge 2021 cultivated land extraction from high-resolution remote sensing image. The challenge requires segmenting cultivated land objects in very high-resolution multispectral remote sensing images. We established a highly effective and efficient pipeline to solve this problem. We first divided the original images into small tiles and separately performed instance segmentation on each tile. We explored several instance segmentation algorithms that work well on natural images and developed a set of effective methods that are applicable to remote sensing images. Then we merged the prediction results of all small tiles into seamless, continuous segmentation results through our proposed overlap-tile fusion strategy. We achieved the first place among 486 teams in the challenge.
End-to-End Face Parsing via Interlinked Convolutional Neural Networks
Feb 12, 2020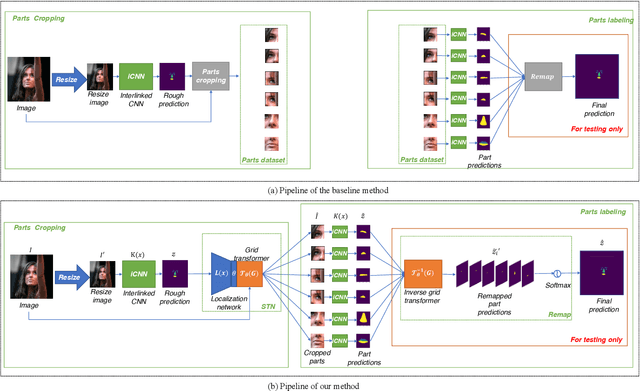

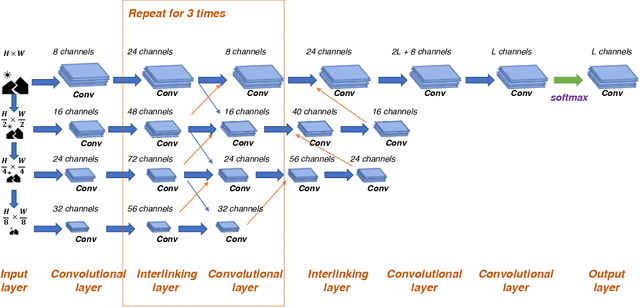
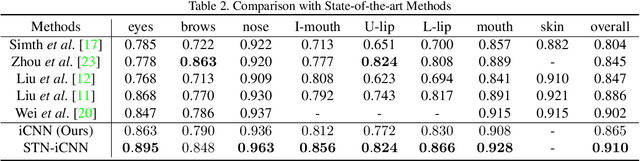
Face parsing is an important computer vision task that requires accurate pixel segmentation of facial parts (such as eyes, nose, mouth, etc.), providing a basis for further face analysis, modification, and other applications. In this paper, we introduce a simple, end-to-end face parsing framework: STN-aided iCNN (STN-iCNN), which extends interlinked Convolutional Neural Network (iCNN) by adding a Spatial Transformer Network (STN) between the two isolated stages. The STN-iCNN uses the STN to provide a trainable connection to the original two-stage iCNN pipe-line, making end-to-end joint training possible. Moreover, as a by-product, STN also provides more precise cropped parts than the original cropper. Due to the two advantages, our approach significantly improves the accuracy of the original model.
Principal Model Analysis Based on Partial Least Squares
Feb 06, 2019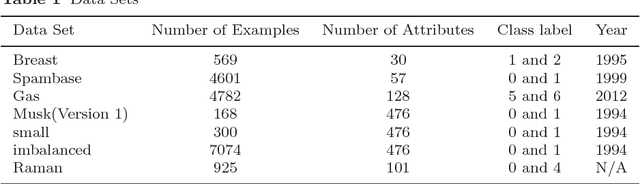
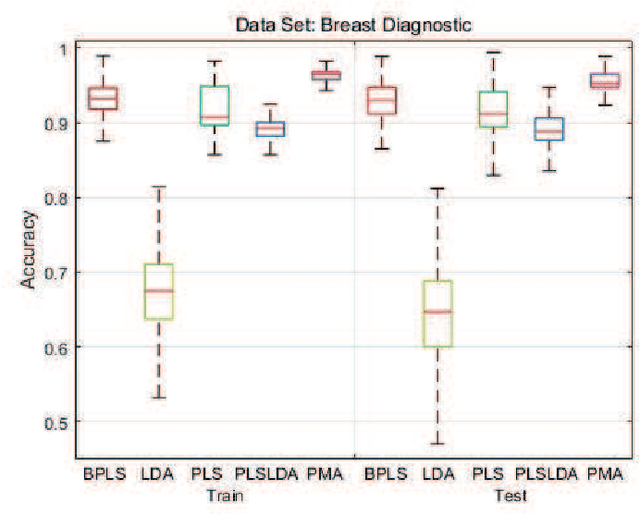
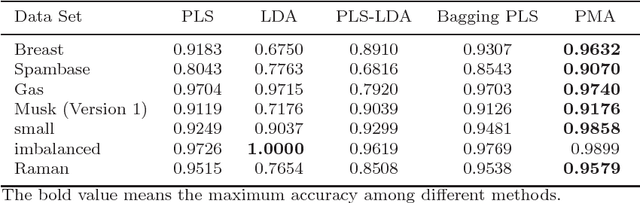
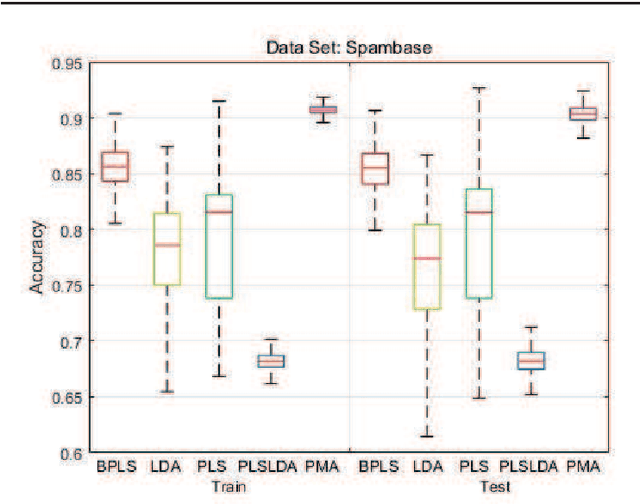
Motivated by the Bagging Partial Least Squares (PLS) and Principal Component Analysis (PCA) algorithms, we propose a Principal Model Analysis (PMA) method in this paper. In the proposed PMA algorithm, the PCA and the PLS are combined. In the method, multiple PLS models are trained on sub-training sets, derived from the original training set based on the random sampling with replacement method. The regression coefficients of all the sub-PLS models are fused in a joint regression coefficient matrix. The final projection direction is then estimated by performing the PCA on the joint regression coefficient matrix. The proposed PMA method is compared with other traditional dimension reduction methods, such as PLS, Bagging PLS, Linear discriminant analysis (LDA) and PLS-LDA. Experimental results on six public datasets show that our proposed method can achieve better classification performance and is usually more stable.