 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Effectively Explore in Context-Based Meta-RL
Jun 15, 2020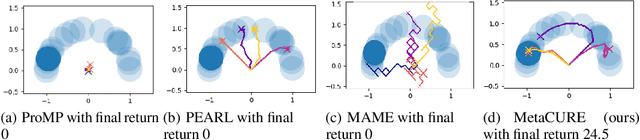

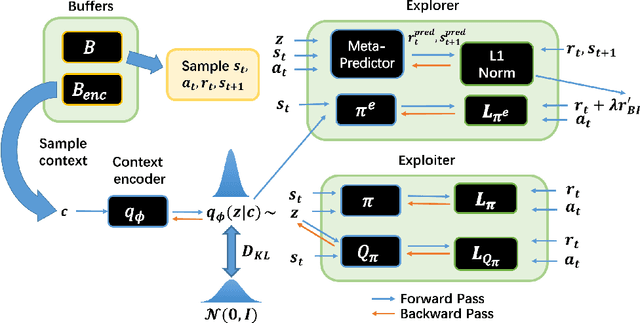
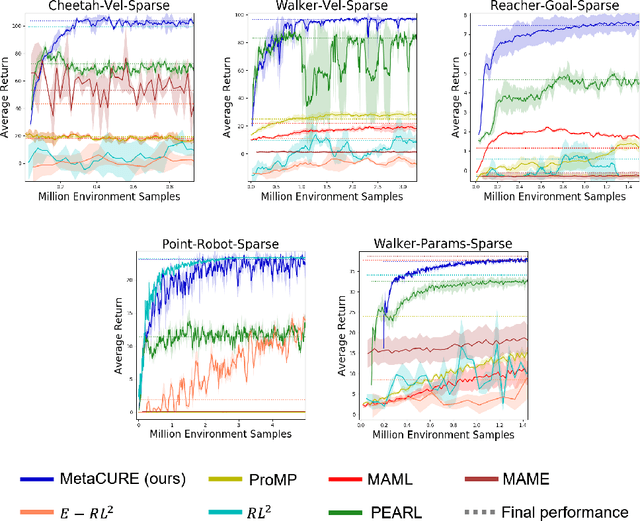
Meta reinforcement learning (meta-RL) provides a principled approach for fast adaptation to novel tasks by extracting prior knowledge from previous tasks. Under such settings, it is crucial for the agent to perform efficient exploration during adaptation to collect useful experiences. However, existing methods suffer from poor adaptation performance caused by inefficient exploration mechanisms, especially in sparse-reward problems. In this paper, we present a novel off-policy context-based meta-RL approach that efficiently learns a separate exploration policy to support fast adaptation, as well as a context-aware exploitation policy to maximize extrinsic return. The explorer is motivated by an information-theoretical intrinsic reward that encourages the agent to collect experiences that provide rich information about the task. Experiment results on both MuJoCo and Meta-World benchmarks show that our method significantly outperforms baselines by performing efficient exploration strategies.
Exploring Unknown States with Action Balance
Mar 10, 2020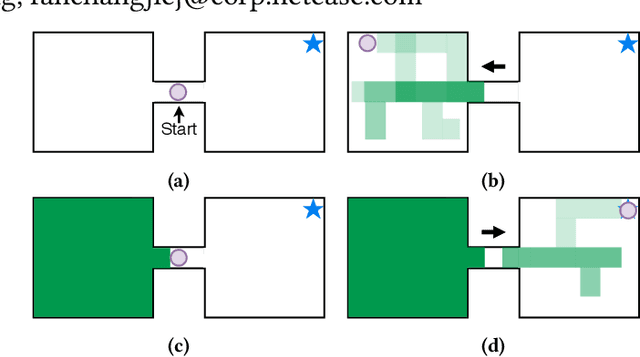
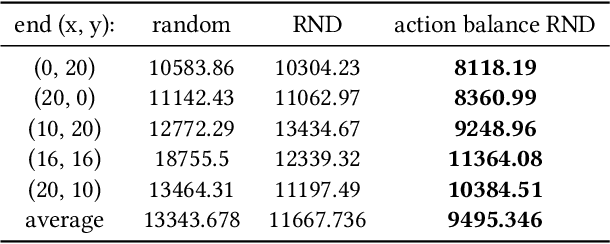
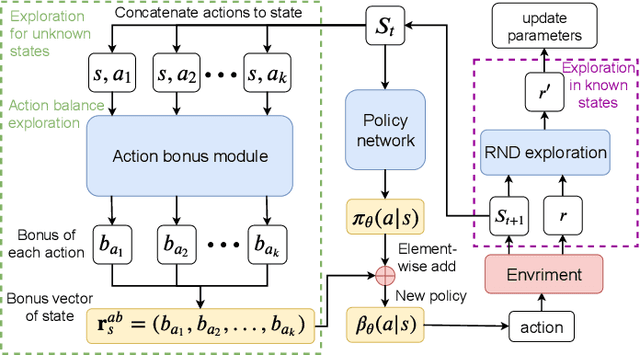
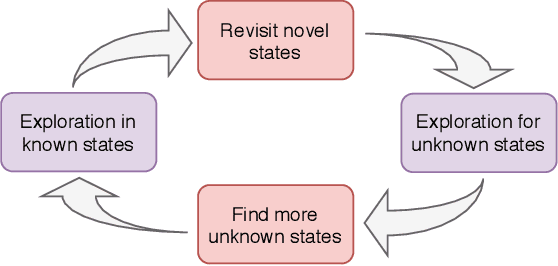
Exploration is a key problem in reinforcement learning. Recently bonus-based methods have achieved considerable successes in environments where exploration is difficult such as Montezuma's Revenge, which assign additional bonus (e.g., intrinsic reward) to guide the agent to rarely visited states. Since the bonus is calculated according to the novelty of the next state after performing an action, we call such methods the next-state bonus methods. However, the next-state bonus methods bring extra issues. It may lead agent to be trapped in states that fewer being visited and ignore to explore unknown states. Moreover, the behavior policy of the agent is also influenced by the bonus added to the state (or state-action) values indirectly. In contrast to the bonus-based methods which explore in known states, in this paper, we focus on the other part of exploration: exploration for finding unknown states. We propose the action balance exploration method to overcome the defects of the next-state bonus methods, which balances the chosen time of each action in each state and can be treated as an extension of upper confidence bound (UCB) to deep reinforcement learning. To take both the advantages of the next-state bonus method and our action balance exploration method, we propose the action balance RND method, which takes both parts of exploration into consideration. The experiments on grid world and Atari games demonstrate action balance exploration has a better capability in finding unknown states and can improve the real performance of RND in some hard exploration environments respectively.
From Few to More: Large-scale Dynamic Multiagent Curriculum Learning
Sep 06, 2019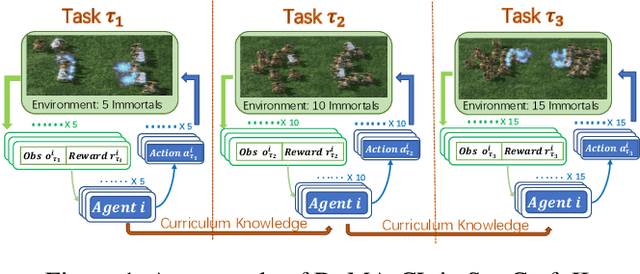
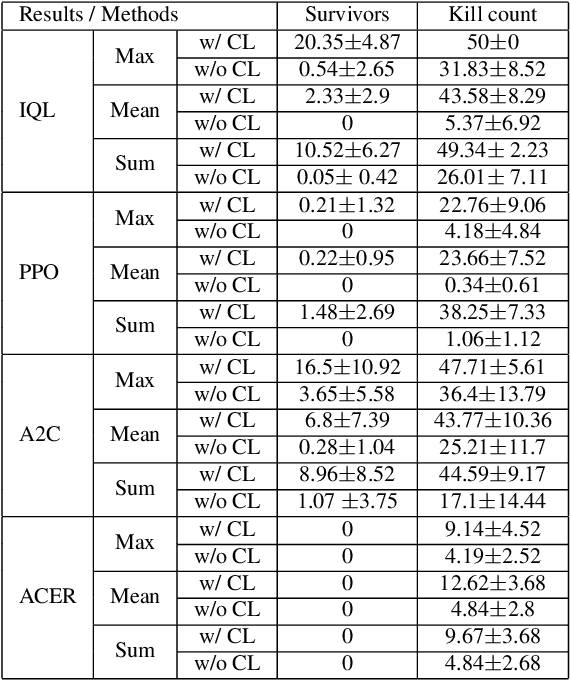
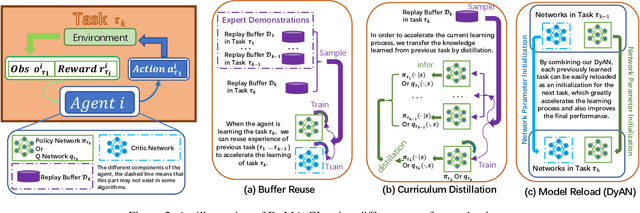

A lot of efforts have been devoted to investigating how agents can learn effectively and achieve coordination in multiagent systems. However, it is still challenging in large-scale multiagent settings due to the complex dynamics between the environment and agents and the explosion of state-action space. In this paper, we design a novel Dynamic Multiagent Curriculum Learning (DyMA-CL) to solve large-scale problems by starting from learning on a multiagent scenario with a small size and progressively increasing the number of agents. We propose three transfer mechanisms across curricula to accelerate the learning process. Moreover, due to the fact that the state dimension varies across curricula,, and existing network structures cannot be applied in such a transfer setting since their network input sizes are fixed. Therefore, we design a novel network structure called Dynamic Agent-number Network (DyAN) to handle the dynamic size of the network input. Experimental results show that DyMA-CL using DyAN greatly improves the performance of large-scale multiagent learning compared with state-of-the-art deep reinforcement learning approaches. We also investigate the influence of three transfer mechanisms across curricula through extensive simulations.
Learning Action-Transferable Policy with Action Embedding
Sep 06, 2019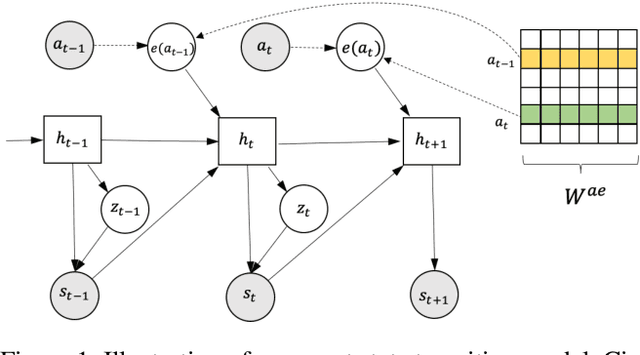

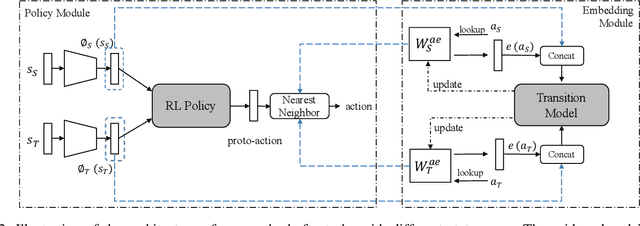
Despite achieving great success on performance in various sequential decision task, deep reinforcement learning is extremely data inefficient. Many approaches have been proposed to improve the data efficiency, e.g. transfer learning which utilizes knowledge learned from related tasks to accelerate training. Previous researches on transfer learning mostly attempt to learn a common feature space of states across related tasks to exploit knowledge as much as possible. However, semantic information of actions may be shared as well, even between tasks with different action space size. In this work, we first propose a method to learn action embedding for discrete actions in RL from generated trajectories without any prior knowledge, and then leverage it to transfer policy across tasks with different state space and/or discrete action space. We validate our method on a set of gridworld navigation tasks, discretized continuous control tasks and fighting tasks in a commercial video game. Our experimental results show that our method can effectively learn informative action embeddings and accelerate learning by policy transfer across tasks.
Action Semantics Network: Considering the Effects of Actions in Multiagent Systems
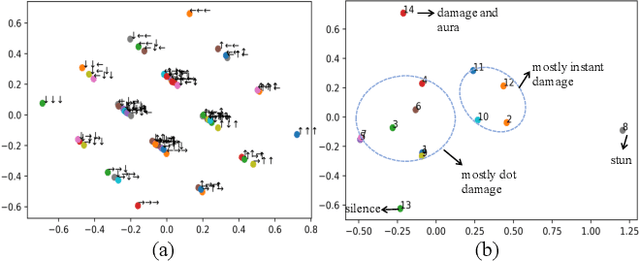
Jul 26, 2019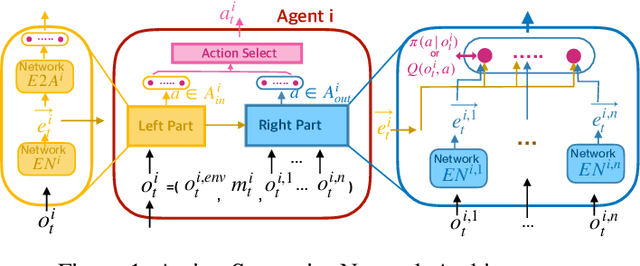
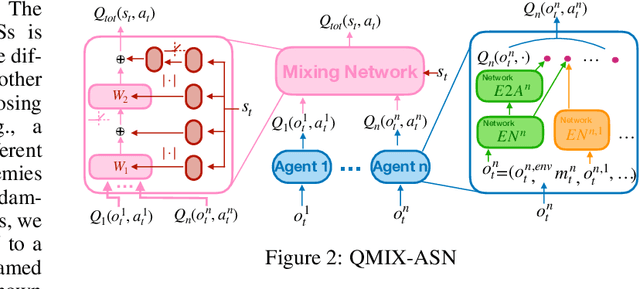

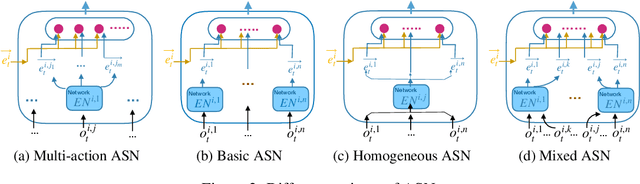
In multiagent systems (MASs), each agent makes individual decisions but all of them contribute globally to the system evolution. Learning in MASs is difficult since the selection of actions must take place in the presence of other co-learning agents. Moreover, the environmental stochasticity and uncertainties increase exponentially with the number of agents. A number of previous works borrow various multiagent coordination mechanisms into deep multiagent learning architecture to facilitate multiagent coordination. However, none of them explicitly consider action semantics between agents. In this paper, we propose a novel network architecture, named Action Semantics Network (ASN), that explicitly represents such action semantics between agents. ASN characterizes different actions' influence on other agents using neural networks based on the action semantics between agents. ASN can be easily combined with existing deep reinforcement learning (DRL) algorithms to boost their performance. Experimental results on StarCraft II and Neural MMO show ASN significantly improves the performance of state-of-the-art DRL approaches compared with a number of network architectures.
Reinforcement Learning Experience Reuse with Policy Residual Representation
May 31, 2019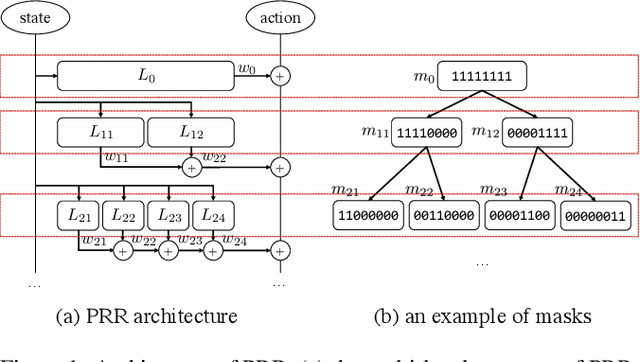

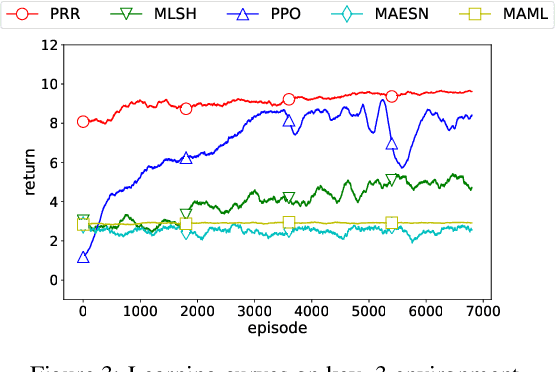
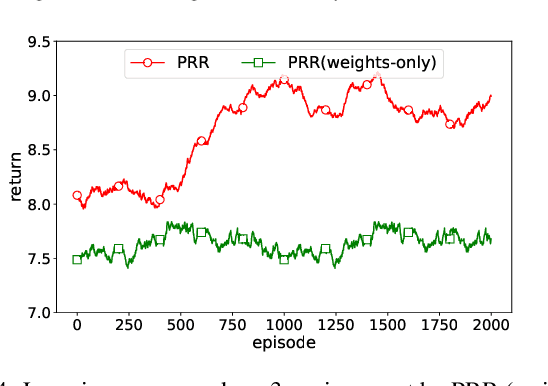
Experience reuse is key to sample-efficient reinforcement learning. One of the critical issues is how the experience is represented and stored. Previously, the experience can be stored in the forms of features, individual models, and the average model, each lying at a different granularity. However, new tasks may require experience across multiple granularities. In this paper, we propose the policy residual representation (PRR) network, which can extract and store multiple levels of experience. PRR network is trained on a set of tasks with a multi-level architecture, where a module in each level corresponds to a subset of the tasks. Therefore, the PRR network represents the experience in a spectrum-like way. When training on a new task, PRR can provide different levels of experience for accelerating the learning. We experiment with the PRR network on a set of grid world navigation tasks, locomotion tasks, and fighting tasks in a video game. The results show that the PRR network leads to better reuse of experience and thus outperforms some state-of-the-art approaches.
Deep Multi-Agent Reinforcement Learning with Discrete-Continuous Hybrid Action Spaces
Mar 12, 2019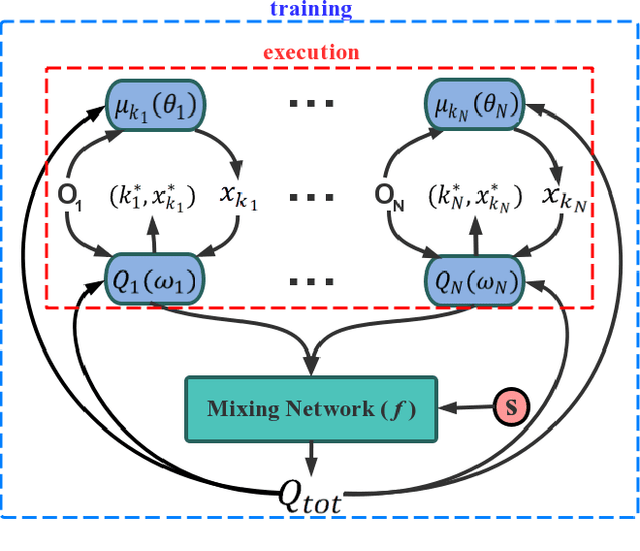
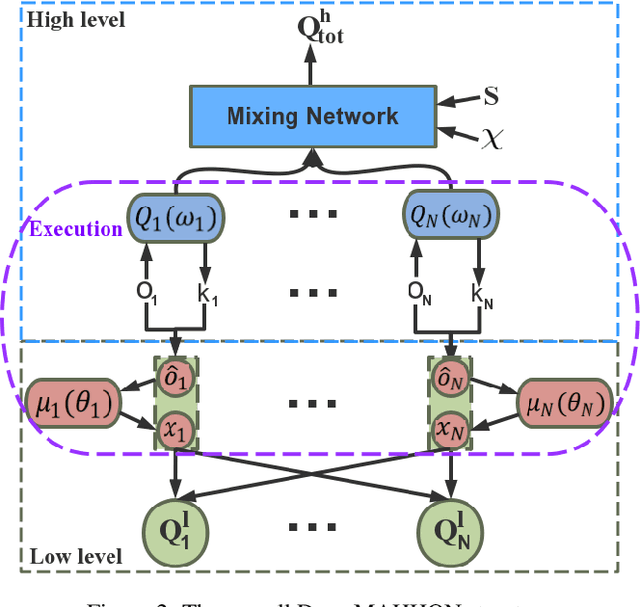
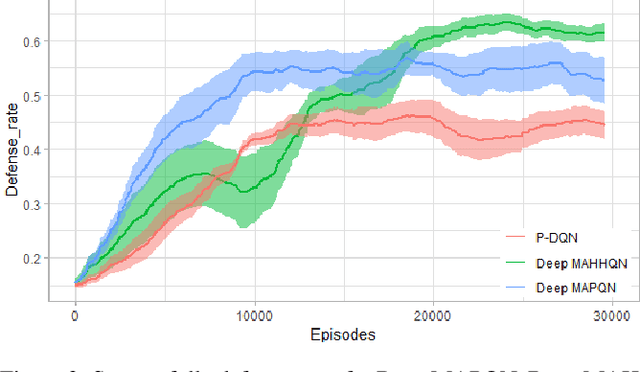
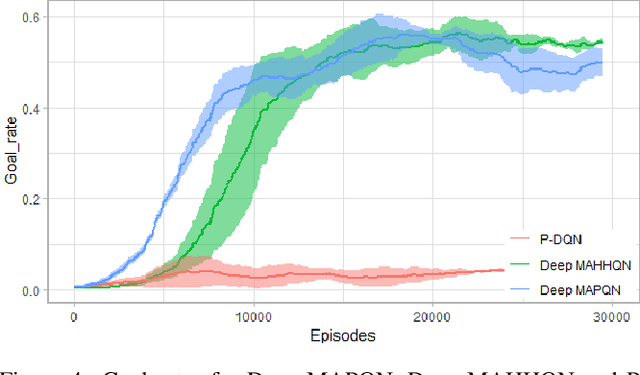
Deep Reinforcement Learning (DRL) has been applied to address a variety of cooperative multi-agent problems with either discrete action spaces or continuous action spaces. However, to the best of our knowledge, no previous work has ever succeeded in applying DRL to multi-agent problems with discrete-continuous hybrid (or parameterized) action spaces which is very common in practice. Our work fills this gap by proposing two novel algorithms: Deep Multi-Agent Parameterized Q-Networks (Deep MAPQN) and Deep Multi-Agent Hierarchical Hybrid Q-Networks (Deep MAHHQN). We follow the centralized training but decentralized execution paradigm: different levels of communication between different agents are used to facilitate the training process, while each agent executes its policy independently based on local observations during execution. Our empirical results on several challenging tasks (simulated RoboCup Soccer and game Ghost Story) show that both Deep MAPQN and Deep MAHHQN are effective and significantly outperform existing independent deep parameterized Q-learning method.
Hierarchical Deep Multiagent Reinforcement Learning
Sep 25, 2018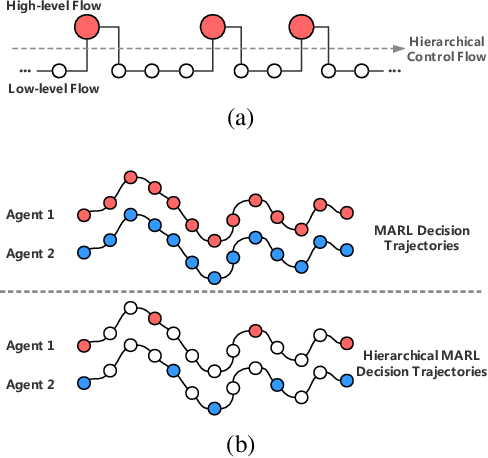
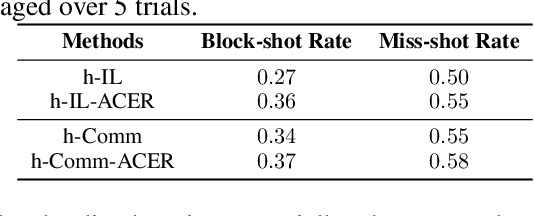
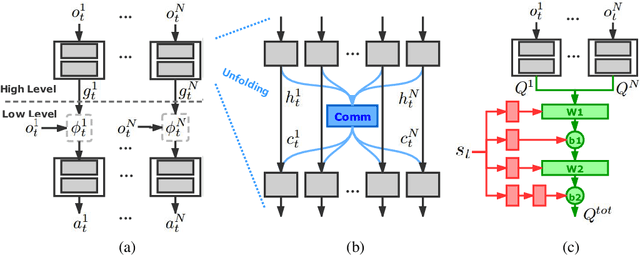
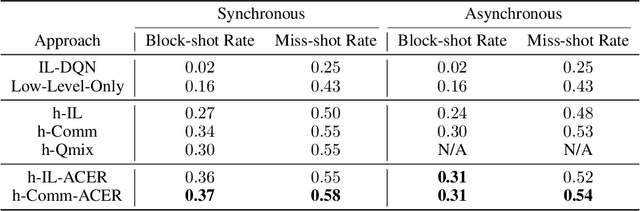
Despite deep reinforcement learning has recently achieved great successes, however in multiagent environments, a number of challenges still remain. Multiagent reinforcement learning (MARL) is commonly considered to suffer from the problem of non-stationary environments and exponentially increasing policy space. It would be even more challenging to learn effective policies in circumstances where the rewards are sparse and delayed over long trajectories. In this paper, we study Hierarchical Deep Multiagent Reinforcement Learning (hierarchical deep MARL) in cooperative multiagent problems with sparse and delayed rewards, where efficient multiagent learning methods are desperately needed. We decompose the original MARL problem into hierarchies and investigate how effective policies can be learned hierarchically in synchronous/asynchronous hierarchical MARL frameworks. Several hierarchical deep MARL architectures, i.e., Ind-hDQN, hCom and hQmix, are introduced for different learning paradigms. Moreover, to alleviate the issues of sparse experiences in high-level learning and non-stationarity in multiagent settings, we propose a new experience replay mechanism, named as Augmented Concurrent Experience Replay (ACER). We empirically demonstrate the effects and efficiency of our approaches in several classic Multiagent Trash Collection tasks, as well as in an extremely challenging team sports game, i.e., Fever Basketball Defense.