 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSASN: A Multitask Attention-Based Framework for Heterogeneous Thyroid Carcinoma Classification in Ultrasound Images
May 04, 2025Heterogeneous morphological features and data imbalance pose significant challenges in rare thyroid carcinoma classification using ultrasound imaging. To address this issue, we propose a novel multitask learning framework, Channel-Spatial Attention Synergy Network (CSASN), which integrates a dual-branch feature extractor - combining EfficientNet for local spatial encoding and ViT for global semantic modeling, with a cascaded channel-spatial attention refinement module. A residual multiscale classifier and dynamically weighted loss function further enhance classification stability and accuracy. Trained on a multicenter dataset comprising more than 2000 patients from four clinical institutions, our framework leverages a residual multiscale classifier and dynamically weighted loss function to enhance classification stability and accuracy. Extensive ablation studies demonstrate that each module contributes significantly to model performance, particularly in recognizing rare subtypes such as FTC and MTC carcinomas. Experimental results show that CSASN outperforms existing single-stream CNN or Transformer-based models, achieving a superior balance between precision and recall under class-imbalanced conditions. This framework provides a promising strategy for AI-assisted thyroid cancer diagnosis.
Phantora: Live GPU Cluster Simulation for Machine Learning System Performance Estimation
May 02, 2025To accommodate ever-increasing model complexity, modern machine learning (ML) systems have to scale to large GPU clusters. Changes in ML model architecture, ML system implementation, and cluster configuration can significantly affect overall ML system performance. However, quantifying the performance impact before deployment is challenging. Existing performance estimation methods use performance modeling or static workload simulation. These techniques are not general: they requires significant human effort and computation capacity to generate training data or a workload. It is also difficult to adapt ML systems to use these techniques. This paper introduces, Phantora, a live GPU cluster simulator for performance estimation. Phantora runs minimally modified ML models and frameworks, intercepting and simulating GPU-related operations to enable high-fidelity performance estimation. Phantora overcomes several research challenges in integrating an event-driven network simulator with live system execution, and introduces a set of techniques to improve simulation speed, scalability, and accuracy. Our evaluation results show that Phantora can deliver similar estimation accuracy to the state-of-the-art workload simulation approach with only one GPU, while reducing human effort and increasing generalizability.
Salient Region-Guided Spacecraft Image Arbitrary-Scale Super-Resolution Network
Apr 25, 2025Spacecraft image super-resolution seeks to enhance low-resolution spacecraft images into high-resolution ones. Although existing arbitrary-scale super-resolution methods perform well on general images, they tend to overlook the difference in features between the spacecraft core region and the large black space background, introducing irrelevant noise. In this paper, we propose a salient region-guided spacecraft image arbitrary-scale super-resolution network (SGSASR), which uses features from the spacecraft core salient regions to guide latent modulation and achieve arbitrary-scale super-resolution. Specifically, we design a spacecraft core region recognition block (SCRRB) that identifies the core salient regions in spacecraft images using a pre-trained saliency detection model. Furthermore, we present an adaptive-weighted feature fusion enhancement mechanism (AFFEM) to selectively aggregate the spacecraft core region features with general image features by dynamic weight parameter to enhance the response of the core salient regions. Experimental results demonstrate that the proposed SGSASR outperforms state-of-the-art approaches.
Optimal Power Allocation for OFDM-based Ranging Using Random Communication Signals
Apr 25, 2025High-precision ranging plays a crucial role in future 6G Integrated Sensing and Communication (ISAC) systems. To improve the ranging performance while maximizing the resource utilization efficiency, future 6G ISAC networks have to reuse data payload signals for both communication and sensing, whose inherent randomness may deteriorate the ranging performance. To address this issue, this paper investigates the power allocation (PA) design for an OFDM-based ISAC system under random signaling, aiming to reduce the ranging sidelobe level of both periodic and aperiodic auto-correlation functions (P-ACF and A-ACF) of the ISAC signal. Towards that end, we first derive the closed-form expressions of the average squared P-ACF and A-ACF, and then propose to minimize the expectation of the integrated sidelobe level (EISL) under arbitrary constellation mapping. We then rigorously prove that the uniform PA scheme achieves the global minimum of the EISL for both P-ACF and A-ACF. As a step further, we show that this scheme also minimizes the P-ACF sidelobe level at every lag. Moreover, we extend our analysis to the P-ACF case with frequency-domain zero-padding, which is a typical approach to improve the ranging resolution. We reveal that there exists a tradeoff between sidelobe level and mainlobe width, and propose a project gradient descent algorithm to seek a locally optimal PA scheme that reduces the EISL. Finally, we validate our theoretical findings through extensive simulation results, confirming the effectiveness of the proposed PA methods in reducing the ranging sidelobe level for random OFDM signals.
Influence Maximization in Temporal Social Networks with a Cold-Start Problem: A Supervised Approach
Apr 15, 2025Influence Maximization (IM) in temporal graphs focuses on identifying influential "seeds" that are pivotal for maximizing network expansion. We advocate defining these seeds through Influence Propagation Paths (IPPs), which is essential for scaling up the network. Our focus lies in efficiently labeling IPPs and accurately predicting these seeds, while addressing the often-overlooked cold-start issue prevalent in temporal networks. Our strategy introduces a motif-based labeling method and a tensorized Temporal Graph Network (TGN) tailored for multi-relational temporal graphs, bolstering prediction accuracy and computational efficiency. Moreover, we augment cold-start nodes with new neighbors from historical data sharing similar IPPs. The recommendation system within an online team-based gaming environment presents subtle impact on the social network, forming multi-relational (i.e., weak and strong) temporal graphs for our empirical IM study. We conduct offline experiments to assess prediction accuracy and model training efficiency, complemented by online A/B testing to validate practical network growth and the effectiveness in addressing the cold-start issue.
Enhancing LLM Generation with Knowledge Hypergraph for Evidence-Based Medicine
Mar 18, 2025



Evidence-based medicine (EBM) plays a crucial role in the application of large language models (LLMs) in healthcare, as it provides reliable support for medical decision-making processes. Although it benefits from current retrieval-augmented generation~(RAG) technologies, it still faces two significant challenges: the collection of dispersed evidence and the efficient organization of this evidence to support the complex queries necessary for EBM. To tackle these issues, we propose using LLMs to gather scattered evidence from multiple sources and present a knowledge hypergraph-based evidence management model to integrate these evidence while capturing intricate relationships. Furthermore, to better support complex queries, we have developed an Importance-Driven Evidence Prioritization (IDEP) algorithm that utilizes the LLM to generate multiple evidence features, each with an associated importance score, which are then used to rank the evidence and produce the final retrieval results. Experimental results from six datasets demonstrate that our approach outperforms existing RAG techniques in application domains of interest to EBM, such as medical quizzing, hallucination detection, and decision support. Testsets and the constructed knowledge graph can be accessed at \href{https://drive.google.com/file/d/1WJ9QTokK3MdkjEmwuFQxwH96j_Byawj_/view?usp=drive_link}{https://drive.google.com/rag4ebm}.
G-Boost: Boosting Private SLMs with General LLMs
Mar 13, 2025Due to the limited computational resources, most Large Language Models (LLMs) developers can only fine-tune Small Language Models (SLMs) on their own data. These private SLMs typically have limited effectiveness. To boost the performance of private SLMs, this paper proposes to ask general LLMs for help. The general LLMs can be APIs or larger LLMs whose inference cost the developers can afford. Specifically, we propose the G-Boost framework where a private SLM adaptively performs collaborative inference with a general LLM under the guide of process reward. Experiments demonstrate that our framework can significantly boost the performance of private SLMs.
TimeStep Master: Asymmetrical Mixture of Timestep LoRA Experts for Versatile and Efficient Diffusion Models in Vision
Mar 10, 2025
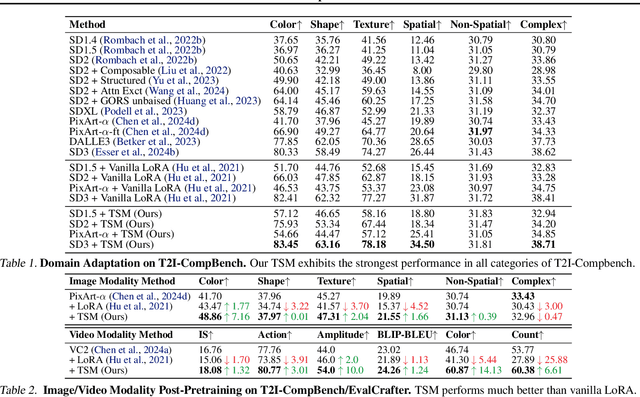
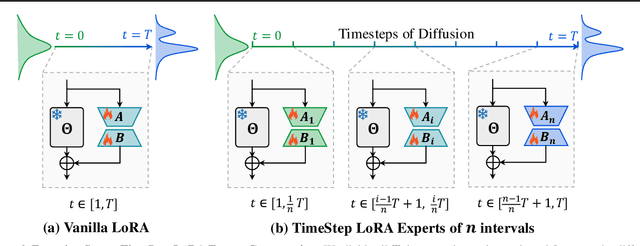
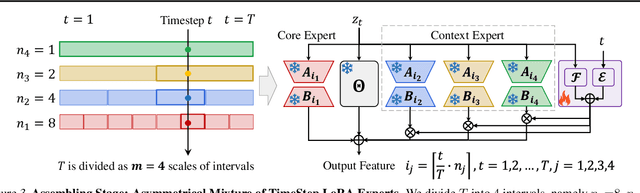
Diffusion models have driven the advancement of vision generation over the past years. However, it is often difficult to apply these large models in downstream tasks, due to massive fine-tuning cost. Recently, Low-Rank Adaptation (LoRA) has been applied for efficient tuning of diffusion models. Unfortunately, the capabilities of LoRA-tuned diffusion models are limited, since the same LoRA is used for different timesteps of the diffusion process. To tackle this problem, we introduce a general and concise TimeStep Master (TSM) paradigm with two key fine-tuning stages. In the fostering stage (1-stage), we apply different LoRAs to fine-tune the diffusion model at different timestep intervals. This results in different TimeStep LoRA experts that can effectively capture different noise levels. In the assembling stage (2-stage), we design a novel asymmetrical mixture of TimeStep LoRA experts, via core-context collaboration of experts at multi-scale intervals. For each timestep, we leverage TimeStep LoRA expert within the smallest interval as the core expert without gating, and use experts within the bigger intervals as the context experts with time-dependent gating. Consequently, our TSM can effectively model the noise level via the expert in the finest interval, and adaptively integrate contexts from the experts of other scales, boosting the versatility of diffusion models. To show the effectiveness of our TSM paradigm, we conduct extensive experiments on three typical and popular LoRA-related tasks of diffusion models, including domain adaptation, post-pretraining, and model distillation. Our TSM achieves the state-of-the-art results on all these tasks, throughout various model structures (UNet, DiT and MM-DiT) and visual data modalities (Image, Video), showing its remarkable generalization capacity.
Get In Video: Add Anything You Want to the Video
Mar 08, 2025



Video editing increasingly demands the ability to incorporate specific real-world instances into existing footage, yet current approaches fundamentally fail to capture the unique visual characteristics of particular subjects and ensure natural instance/scene interactions. We formalize this overlooked yet critical editing paradigm as "Get-In-Video Editing", where users provide reference images to precisely specify visual elements they wish to incorporate into videos. Addressing this task's dual challenges, severe training data scarcity and technical challenges in maintaining spatiotemporal coherence, we introduce three key contributions. First, we develop GetIn-1M dataset created through our automated Recognize-Track-Erase pipeline, which sequentially performs video captioning, salient instance identification, object detection, temporal tracking, and instance removal to generate high-quality video editing pairs with comprehensive annotations (reference image, tracking mask, instance prompt). Second, we present GetInVideo, a novel end-to-end framework that leverages a diffusion transformer architecture with 3D full attention to process reference images, condition videos, and masks simultaneously, maintaining temporal coherence, preserving visual identity, and ensuring natural scene interactions when integrating reference objects into videos. Finally, we establish GetInBench, the first comprehensive benchmark for Get-In-Video Editing scenario, demonstrating our approach's superior performance through extensive evaluations. Our work enables accessible, high-quality incorporation of specific real-world subjects into videos, significantly advancing personalized video editing capabilities.
WeGen: A Unified Model for Interactive Multimodal Generation as We Chat
Mar 03, 2025Existing multimodal generative models fall short as qualified design copilots, as they often struggle to generate imaginative outputs once instructions are less detailed or lack the ability to maintain consistency with the provided references. In this work, we introduce WeGen, a model that unifies multimodal generation and understanding, and promotes their interplay in iterative generation. It can generate diverse results with high creativity for less detailed instructions. And it can progressively refine prior generation results or integrating specific contents from references following the instructions in its chat with users. During this process, it is capable of preserving consistency in the parts that the user is already satisfied with. To this end, we curate a large-scale dataset, extracted from Internet videos, containing rich object dynamics and auto-labeled dynamics descriptions by advanced foundation models to date. These two information are interleaved into a single sequence to enable WeGen to learn consistency-aware generation where the specified dynamics are generated while the consistency of unspecified content is preserved aligned with instructions. Besides, we introduce a prompt self-rewriting mechanism to enhance generation diversity. Extensive experiments demonstrate the effectiveness of unifying multimodal understanding and generation in WeGen and show it achieves state-of-the-art performance across various visual generation benchmarks. These also demonstrate the potential of WeGen as a user-friendly design copilot as desired. The code and models will be available at https://github.com/hzphzp/WeGen.