 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhantora: Live GPU Cluster Simulation for Machine Learning System Performance Estimation
May 02, 2025To accommodate ever-increasing model complexity, modern machine learning (ML) systems have to scale to large GPU clusters. Changes in ML model architecture, ML system implementation, and cluster configuration can significantly affect overall ML system performance. However, quantifying the performance impact before deployment is challenging. Existing performance estimation methods use performance modeling or static workload simulation. These techniques are not general: they requires significant human effort and computation capacity to generate training data or a workload. It is also difficult to adapt ML systems to use these techniques. This paper introduces, Phantora, a live GPU cluster simulator for performance estimation. Phantora runs minimally modified ML models and frameworks, intercepting and simulating GPU-related operations to enable high-fidelity performance estimation. Phantora overcomes several research challenges in integrating an event-driven network simulator with live system execution, and introduces a set of techniques to improve simulation speed, scalability, and accuracy. Our evaluation results show that Phantora can deliver similar estimation accuracy to the state-of-the-art workload simulation approach with only one GPU, while reducing human effort and increasing generalizability.
Domain-specific Communication Optimization for Distributed DNN Training
Aug 16, 2020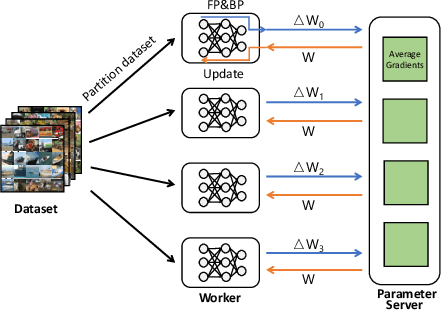

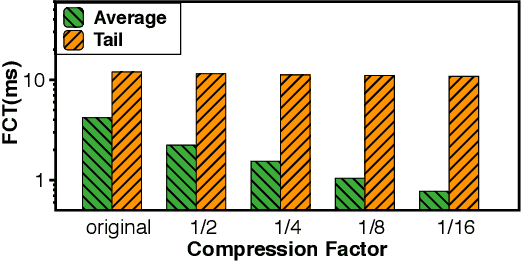
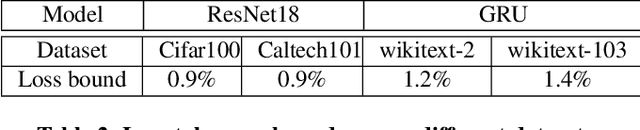
Communication overhead poses an important obstacle to distributed DNN training and draws increasing attention in recent years. Despite continuous efforts, prior solutions such as gradient compression/reduction, compute/communication overlapping and layer-wise flow scheduling, etc., are still coarse-grained and insufficient for an efficient distributed training especially when the network is under pressure. We present DLCP, a novel solution exploiting the domain-specific properties of deep learning to optimize communication overhead of DNN training in a fine-grained manner. At its heart, DLCP comprises of several key innovations beyond prior work: e.g., it exploits {\em bounded loss tolerance} of SGD-based training to improve tail communication latency which cannot be avoided purely through gradient compression. It then performs fine-grained packet-level prioritization and dropping, as opposed to flow-level scheduling, based on layers and magnitudes of gradients to further speedup model convergence without affecting accuracy. In addition, it leverages inter-packet order-independency to perform per-packet load balancing without causing classical re-ordering issues. DLCP works with both Parameter Server and collective communication routines. We have implemented DLCP with commodity switches, integrated it with various training frameworks including TensorFlow, MXNet and PyTorch, and deployed it in our small-scale testbed with 10 Nvidia V100 GPUs. Our testbed experiments and large-scale simulations show that DLCP delivers up to $84.3\%$ additional training acceleration over the best existing solutions.