 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Approval of Access Control Flow in Office Automation Systems via Relational Modeling
Apr 13, 2026Office automation (OA) systems play a crucial role in enterprise operations and management, with access control flow approval (ACFA) being a key component that manages the accessibility of various resources. However, traditional ACFA requires approval from the person in charge at each step, which consumes a significant amount of manpower and time. Its intelligence is a crucial issue that needs to be addressed urgently by all companies. In this paper, we propose a novel relational modeling-driven intelligent approval (RMIA) framework to automate ACFA. Specifically, our RMIA consists of two core modules: (1) The binary relation modeling module aims to characterize the coupling relation between applicants and approvers and provide reliable basic information for ACFA decision-making from a coarse-grained perspective. (2) The ternary relation modeling module utilizes specific resource information as its core, characterizing the complex relations between applicants, resources, and approvers, and thus provides fine-grained gain information for informed decision-making. Then, our RMIA effectively fuses these two kinds of information to form the final decision. Finally, extensive experiments are conducted on two product datasets and an online A/B test to verify the effectiveness of RMIA.
Towards Human-Like Grading: A Unified LLM-Enhanced Framework for Subjective Question Evaluation
Oct 09, 2025Automatic grading of subjective questions remains a significant challenge in examination assessment due to the diversity in question formats and the open-ended nature of student responses. Existing works primarily focus on a specific type of subjective question and lack the generality to support comprehensive exams that contain diverse question types. In this paper, we propose a unified Large Language Model (LLM)-enhanced auto-grading framework that provides human-like evaluation for all types of subjective questions across various domains. Our framework integrates four complementary modules to holistically evaluate student answers. In addition to a basic text matching module that provides a foundational assessment of content similarity, we leverage the powerful reasoning and generative capabilities of LLMs to: (1) compare key knowledge points extracted from both student and reference answers, (2) generate a pseudo-question from the student answer to assess its relevance to the original question, and (3) simulate human evaluation by identifying content-related and non-content strengths and weaknesses. Extensive experiments on both general-purpose and domain-specific datasets show that our framework consistently outperforms traditional and LLM-based baselines across multiple grading metrics. Moreover, the proposed system has been successfully deployed in real-world training and certification exams at a major e-commerce enterprise.
Object Navigation with Structure-Semantic Reasoning-Based Multi-level Map and Multimodal Decision-Making LLM
Jun 06, 2025The zero-shot object navigation (ZSON) in unknown open-ended environments coupled with semantically novel target often suffers from the significant decline in performance due to the neglect of high-dimensional implicit scene information and the long-range target searching task. To address this, we proposed an active object navigation framework with Environmental Attributes Map (EAM) and MLLM Hierarchical Reasoning module (MHR) to improve its success rate and efficiency. EAM is constructed by reasoning observed environments with SBERT and predicting unobserved ones with Diffusion, utilizing human space regularities that underlie object-room correlations and area adjacencies. MHR is inspired by EAM to perform frontier exploration decision-making, avoiding the circuitous trajectories in long-range scenarios to improve path efficiency. Experimental results demonstrate that the EAM module achieves 64.5\% scene mapping accuracy on MP3D dataset, while the navigation task attains SPLs of 28.4\% and 26.3\% on HM3D and MP3D benchmarks respectively - representing absolute improvements of 21.4\% and 46.0\% over baseline methods.
TCM-Ladder: A Benchmark for Multimodal Question Answering on Traditional Chinese Medicine
May 29, 2025Traditional Chinese Medicine (TCM), as an effective alternative medicine, has been receiving increasing attention. In recent years, the rapid development of large language models (LLMs) tailored for TCM has underscored the need for an objective and comprehensive evaluation framework to assess their performance on real-world tasks. However, existing evaluation datasets are limited in scope and primarily text-based, lacking a unified and standardized multimodal question-answering (QA) benchmark. To address this issue, we introduce TCM-Ladder, the first multimodal QA dataset specifically designed for evaluating large TCM language models. The dataset spans multiple core disciplines of TCM, including fundamental theory, diagnostics, herbal formulas, internal medicine, surgery, pharmacognosy, and pediatrics. In addition to textual content, TCM-Ladder incorporates various modalities such as images and videos. The datasets were constructed using a combination of automated and manual filtering processes and comprise 52,000+ questions in total. These questions include single-choice, multiple-choice, fill-in-the-blank, diagnostic dialogue, and visual comprehension tasks. We trained a reasoning model on TCM-Ladder and conducted comparative experiments against 9 state-of-the-art general domain and 5 leading TCM-specific LLMs to evaluate their performance on the datasets. Moreover, we propose Ladder-Score, an evaluation method specifically designed for TCM question answering that effectively assesses answer quality regarding terminology usage and semantic expression. To our knowledge, this is the first work to evaluate mainstream general domain and TCM-specific LLMs on a unified multimodal benchmark. The datasets and leaderboard are publicly available at https://tcmladder.com or https://54.211.107.106 and will be continuously updated.
Analyzing Unaligned Multimodal Sequence via Graph Convolution and Graph Pooling Fusion
Dec 02, 2020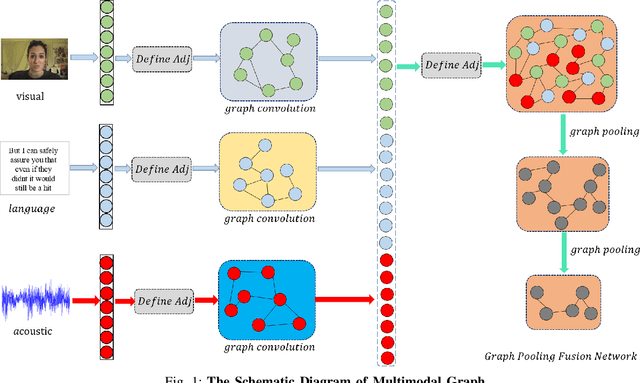

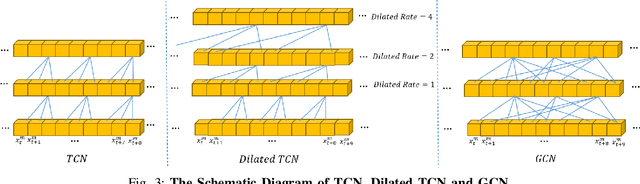
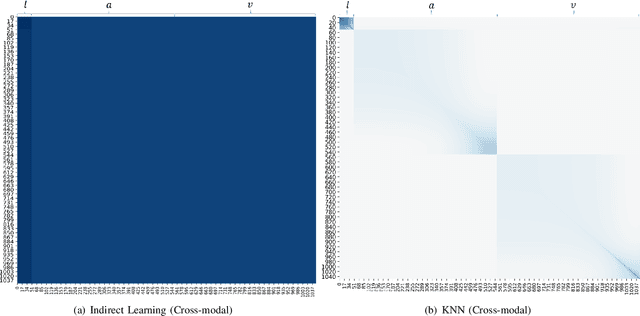
In this paper, we study the task of multimodal sequence analysis which aims to draw inferences from visual, language and acoustic sequences. A majority of existing works generally focus on aligned fusion, mostly at word level, of the three modalities to accomplish this task, which is impractical in real-world scenarios. To overcome this issue, we seek to address the task of multimodal sequence analysis on unaligned modality sequences which is still relatively underexplored and also more challenging. Recurrent neural network (RNN) and its variants are widely used in multimodal sequence analysis, but they are susceptible to the issues of gradient vanishing/explosion and high time complexity due to its recurrent nature. Therefore, we propose a novel model, termed Multimodal Graph, to investigate the effectiveness of graph neural networks (GNN) on modeling multimodal sequential data. The graph-based structure enables parallel computation in time dimension and can learn longer temporal dependency in long unaligned sequences. Specifically, our Multimodal Graph is hierarchically structured to cater to two stages, i.e., intra- and inter-modal dynamics learning. For the first stage, a graph convolutional network is employed for each modality to learn intra-modal dynamics. In the second stage, given that the multimodal sequences are unaligned, the commonly considered word-level fusion does not pertain. To this end, we devise a graph pooling fusion network to automatically learn the associations between various nodes from different modalities. Additionally, we define multiple ways to construct the adjacency matrix for sequential data. Experimental results suggest that our graph-based model reaches state-of-the-art performance on two benchmark datasets.