 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023



This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.
Frequency-aware Dimension Selection for Static Word Embedding by Mixed Product Distance
May 13, 2023Static word embedding is still useful, particularly for context-unavailable tasks, because in the case of no context available, pre-trained language models often perform worse than static word embeddings. Although dimension is a key factor determining the quality of static word embeddings, automatic dimension selection is rarely discussed. In this paper, we investigate the impact of word frequency on the dimension selection, and empirically find that word frequency is so vital that it needs to be taken into account during dimension selection. Based on such an empirical finding, this paper proposes a dimension selection method that uses a metric (Mixed Product Distance, MPD) to select a proper dimension for word embedding algorithms without training any word embedding. Through applying a post-processing function to oracle matrices, the MPD-based method can de-emphasize the impact of word frequency. Experiments on both context-unavailable and context-available tasks demonstrate the better efficiency-performance trade-off of our MPD-based dimension selection method over baselines.
FusionDepth: Complement Self-Supervised Monocular Depth Estimation with Cost Volume
May 10, 2023Multi-view stereo depth estimation based on cost volume usually works better than self-supervised monocular depth estimation except for moving objects and low-textured surfaces. So in this paper, we propose a multi-frame depth estimation framework which monocular depth can be refined continuously by multi-frame sequential constraints, leveraging a Bayesian fusion layer within several iterations. Both monocular and multi-view networks can be trained with no depth supervision. Our method also enhances the interpretability when combining monocular estimation with multi-view cost volume. Detailed experiments show that our method surpasses state-of-the-art unsupervised methods utilizing single or multiple frames at test time on KITTI benchmark.
MD-VQA: Multi-Dimensional Quality Assessment for UGC Live Videos
Apr 19, 2023



User-generated content (UGC) live videos are often bothered by various distortions during capture procedures and thus exhibit diverse visual qualities. Such source videos are further compressed and transcoded by media server providers before being distributed to end-users. Because of the flourishing of UGC live videos, effective video quality assessment (VQA) tools are needed to monitor and perceptually optimize live streaming videos in the distributing process. In this paper, we address \textbf{UGC Live VQA} problems by constructing a first-of-a-kind subjective UGC Live VQA database and developing an effective evaluation tool. Concretely, 418 source UGC videos are collected in real live streaming scenarios and 3,762 compressed ones at different bit rates are generated for the subsequent subjective VQA experiments. Based on the built database, we develop a \underline{M}ulti-\underline{D}imensional \underline{VQA} (\textbf{MD-VQA}) evaluator to measure the visual quality of UGC live videos from semantic, distortion, and motion aspects respectively. Extensive experimental results show that MD-VQA achieves state-of-the-art performance on both our UGC Live VQA database and existing compressed UGC VQA databases.
EWT: Efficient Wavelet-Transformer for Single Image Denoising
Apr 13, 2023Transformer-based image denoising methods have achieved encouraging results in the past year. However, it must uses linear operations to model long-range dependencies, which greatly increases model inference time and consumes GPU storage space. Compared with convolutional neural network-based methods, current Transformer-based image denoising methods cannot achieve a balance between performance improvement and resource consumption. In this paper, we propose an Efficient Wavelet Transformer (EWT) for image denoising. Specifically, we use Discrete Wavelet Transform (DWT) and Inverse Wavelet Transform (IWT) for downsampling and upsampling, respectively. This method can fully preserve the image features while reducing the image resolution, thereby greatly reducing the device resource consumption of the Transformer model. Furthermore, we propose a novel Dual-stream Feature Extraction Block (DFEB) to extract image features at different levels, which can further reduce model inference time and GPU memory usage. Experiments show that our method speeds up the original Transformer by more than 80%, reduces GPU memory usage by more than 60%, and achieves excellent denoising results. All code will be public.
TextShield: Beyond Successfully Detecting Adversarial Sentences in Text Classification
Feb 03, 2023Adversarial attack serves as a major challenge for neural network models in NLP, which precludes the model's deployment in safety-critical applications. A recent line of work, detection-based defense, aims to distinguish adversarial sentences from benign ones. However, {the core limitation of previous detection methods is being incapable of giving correct predictions on adversarial sentences unlike defense methods from other paradigms.} To solve this issue, this paper proposes TextShield: (1) we discover a link between text attack and saliency information, and then we propose a saliency-based detector, which can effectively detect whether an input sentence is adversarial or not. (2) We design a saliency-based corrector, which converts the detected adversary sentences to benign ones. By combining the saliency-based detector and corrector, TextShield extends the detection-only paradigm to a detection-correction paradigm, thus filling the gap in the existing detection-based defense. Comprehensive experiments show that (a) TextShield consistently achieves higher or comparable performance than state-of-the-art defense methods across various attacks on different benchmarks. (b) our saliency-based detector outperforms existing detectors for detecting adversarial sentences.
Semi-Supervised Heterogeneous Graph Learning with Multi-level Data Augmentation
Nov 30, 2022In recent years, semi-supervised graph learning with data augmentation (DA) is currently the most commonly used and best-performing method to enhance model robustness in sparse scenarios with few labeled samples. Differing from homogeneous graph, DA in heterogeneous graph has greater challenges: heterogeneity of information requires DA strategies to effectively handle heterogeneous relations, which considers the information contribution of different types of neighbors and edges to the target nodes. Furthermore, over-squashing of information is caused by the negative curvature that formed by the non-uniformity distribution and strong clustering in complex graph. To address these challenges, this paper presents a novel method named Semi-Supervised Heterogeneous Graph Learning with Multi-level Data Augmentation (HG-MDA). For the problem of heterogeneity of information in DA, node and topology augmentation strategies are proposed for the characteristics of heterogeneous graph. And meta-relation-based attention is applied as one of the indexes for selecting augmented nodes and edges. For the problem of over-squashing of information, triangle based edge adding and removing are designed to alleviate the negative curvature and bring the gain of topology. Finally, the loss function consists of the cross-entropy loss for labeled data and the consistency regularization for unlabeled data. In order to effectively fuse the prediction results of various DA strategies, the sharpening is used. Existing experiments on public datasets, i.e., ACM, DBLP, OGB, and industry dataset MB show that HG-MDA outperforms current SOTA models. Additionly, HG-MDA is applied to user identification in internet finance scenarios, helping the business to add 30% key users, and increase loans and balances by 3.6%, 11.1%, and 9.8%.
MFDNet: Towards Real-time Image Denoising On Mobile Devices
Nov 09, 2022



Deep convolutional neural networks have achieved great progress in image denoising tasks. However, their complicated architectures and heavy computational cost hinder their deployments on a mobile device. Some recent efforts in designing lightweight denoising networks focus on reducing either FLOPs (floating-point operations) or the number of parameters. However, these metrics are not directly correlated with the on-device latency. By performing extensive analysis and experiments, we identify the network architectures that can fully utilize powerful neural processing units (NPUs) and thus enjoy both low latency and excellent denoising performance. To this end, we propose a mobile-friendly denoising network, namely MFDNet. The experiments show that MFDNet achieves state-of-the-art performance on real-world denoising benchmarks SIDD and DND under real-time latency on mobile devices. The code and pre-trained models will be released.
Probability-Dependent Gradient Decay in Large Margin Softmax
Oct 31, 2022In the past few years, Softmax has become a common component in neural network frameworks. In this paper, a gradient decay hyperparameter is introduced in Softmax to control the probability-dependent gradient decay rate during training. By following the theoretical analysis and empirical results of a variety of model architectures trained on MNIST, CIFAR-10/100 and SVHN, we find that the generalization performance depends significantly on the gradient decay rate as the confidence probability rises, i.e., the gradient decreases convexly or concavely as the sample probability increases. Moreover, optimization with the small gradient decay shows a similar curriculum learning sequence where hard samples are in the spotlight only after easy samples are convinced sufficiently, and well-separated samples gain a higher gradient to reduce intra-class distance. Based on the analysis results, we can provide evidence that the large margin Softmax will affect the local Lipschitz constraint of the loss function by regulating the probability-dependent gradient decay rate. This paper provides a new perspective and understanding of the relationship among concepts of large margin Softmax, local Lipschitz constraint and curriculum learning by analyzing the gradient decay rate. Besides, we propose a warm-up strategy to dynamically adjust Softmax loss in training, where the gradient decay rate increases from over-small to speed up the convergence rate.
Rediscovery of Numerical Lüscher's Formula from the Neural Network
Oct 05, 2022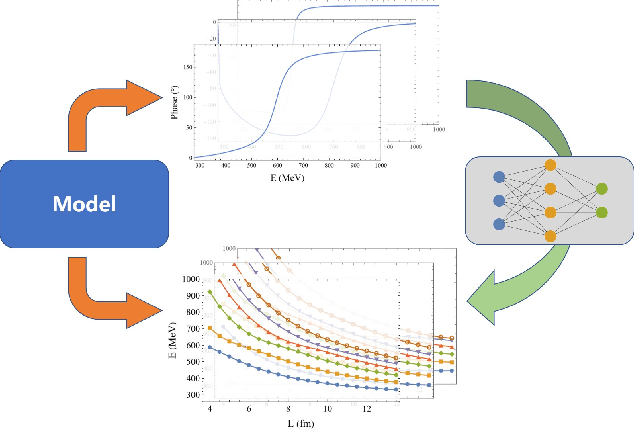
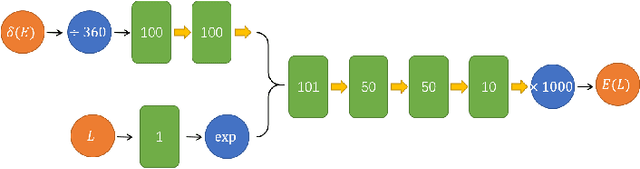
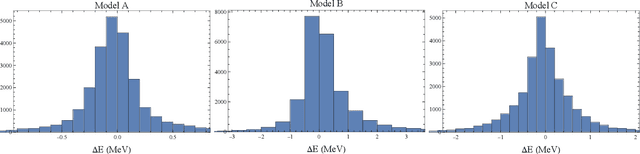
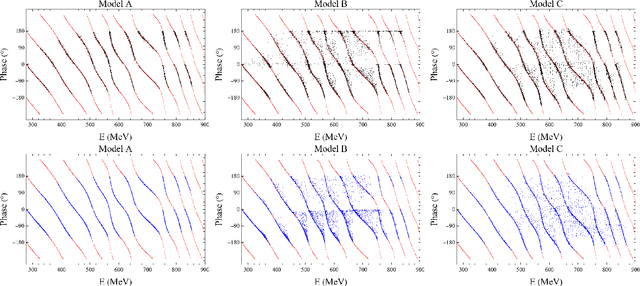
We present that by predicting the spectrum in discrete space from the phase shift in continuous space, the neural network can remarkably reproduce the numerical L\"uscher's formula to a high precision. The model-independent property of the L\"uscher's formula is naturally realized by the generalizability of the neural network. This exhibits the great potential of the neural network to extract model-independent relation between model-dependent quantities, and this data-driven approach could greatly facilitate the discovery of the physical principles underneath the intricate data.