 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Unsupervised Prompt for Vision-Language Models
Apr 25, 2024



Prompt learning has become the most effective paradigm for adapting large pre-trained vision-language models (VLMs) to downstream tasks. Recently, unsupervised prompt tuning methods, such as UPL and POUF, directly leverage pseudo-labels as supervisory information to fine-tune additional adaptation modules on unlabeled data. However, inaccurate pseudo labels easily misguide the tuning process and result in poor representation capabilities. In light of this, we propose Training-Free Unsupervised Prompts (TFUP), which maximally preserves the inherent representation capabilities and enhances them with a residual connection to similarity-based prediction probabilities in a training-free and labeling-free manner. Specifically, we integrate both instance confidence and prototype scores to select representative samples, which are used to customize a reliable Feature Cache Model (FCM) for training-free inference. Then, we design a Multi-level Similarity Measure (MSM) that considers both feature-level and semantic-level similarities to calculate the distance between each test image and the cached sample as the weight of the corresponding cached label to generate similarity-based prediction probabilities. In this way, TFUP achieves surprising performance, even surpassing the training-base method on multiple classification datasets. Based on our TFUP, we propose a training-based approach (TFUP-T) to further boost the adaptation performance. In addition to the standard cross-entropy loss, TFUP-T adopts an additional marginal distribution entropy loss to constrain the model from a global perspective. Our TFUP-T achieves new state-of-the-art classification performance compared to unsupervised and few-shot adaptation approaches on multiple benchmarks. In particular, TFUP-T improves the classification accuracy of POUF by 3.3% on the most challenging Domain-Net dataset.
Progressive Target-Styled Feature Augmentation for Unsupervised Domain Adaptation on Point Clouds
Nov 27, 2023Unsupervised domain adaptation is a critical challenge in the field of point cloud analysis, as models trained on one set of data often struggle to perform well in new scenarios due to domain shifts. Previous works tackle the problem by using adversarial training or self-supervised learning for feature extractor adaptation, but ensuring that features extracted from the target domain can be distinguished by the source-supervised classifier remains challenging. In this work, we propose a novel approach called progressive target-styled feature augmentation (PTSFA). Unlike previous works that focus on feature extractor adaptation, our PTSFA approach focuses on classifier adaptation. It aims to empower the classifier to recognize target-styled source features and progressively adapt to the target domain. To enhance the reliability of predictions within the PTSFA framework and encourage discriminative feature extraction, we further introduce a new intermediate domain approaching (IDA) strategy. We validate our method on the benchmark datasets, where our method achieves new state-of-the-art performance. Our code is available at https://github.com/xiaoyao3302/PTSFA.
Self-Supervised Disentanglement of Harmonic and Rhythmic Features in Music Audio Signals
Sep 06, 2023The aim of latent variable disentanglement is to infer the multiple informative latent representations that lie behind a data generation process and is a key factor in controllable data generation. In this paper, we propose a deep neural network-based self-supervised learning method to infer the disentangled rhythmic and harmonic representations behind music audio generation. We train a variational autoencoder that generates an audio mel-spectrogram from two latent features representing the rhythmic and harmonic content. In the training phase, the variational autoencoder is trained to reconstruct the input mel-spectrogram given its pitch-shifted version. At each forward computation in the training phase, a vector rotation operation is applied to one of the latent features, assuming that the dimensions of the feature vectors are related to pitch intervals. Therefore, in the trained variational autoencoder, the rotated latent feature represents the pitch-related information of the mel-spectrogram, and the unrotated latent feature represents the pitch-invariant information, i.e., the rhythmic content. The proposed method was evaluated using a predictor-based disentanglement metric on the learned features. Furthermore, we demonstrate its application to the automatic generation of music remixes.
Panoptic Scene Graph Generation with Semantics-prototype Learning
Jul 28, 2023Panoptic Scene Graph Generation (PSG) parses objects and predicts their relationships (predicate) to connect human language and visual scenes. However, different language preferences of annotators and semantic overlaps between predicates lead to biased predicate annotations in the dataset, i.e. different predicates for same object pairs. Biased predicate annotations make PSG models struggle in constructing a clear decision plane among predicates, which greatly hinders the real application of PSG models. To address the intrinsic bias above, we propose a novel framework named ADTrans to adaptively transfer biased predicate annotations to informative and unified ones. To promise consistency and accuracy during the transfer process, we propose to measure the invariance of representations in each predicate class, and learn unbiased prototypes of predicates with different intensities. Meanwhile, we continuously measure the distribution changes between each presentation and its prototype, and constantly screen potential biased data. Finally, with the unbiased predicate-prototype representation embedding space, biased annotations are easily identified. Experiments show that ADTrans significantly improves the performance of benchmark models, achieving a new state-of-the-art performance, and shows great generalization and effectiveness on multiple datasets.
HeightFormer: Explicit Height Modeling without Extra Data for Camera-only 3D Object Detection in Bird's Eye View
Jul 25, 2023Vision-based Bird's Eye View (BEV) representation is an emerging perception formulation for autonomous driving. The core challenge is to construct BEV space with multi-camera features, which is a one-to-many ill-posed problem. Diving into all previous BEV representation generation methods, we found that most of them fall into two types: modeling depths in image views or modeling heights in the BEV space, mostly in an implicit way. In this work, we propose to explicitly model heights in the BEV space, which needs no extra data like LiDAR and can fit arbitrary camera rigs and types compared to modeling depths. Theoretically, we give proof of the equivalence between height-based methods and depth-based methods. Considering the equivalence and some advantages of modeling heights, we propose HeightFormer, which models heights and uncertainties in a self-recursive way. Without any extra data, the proposed HeightFormer could estimate heights in BEV accurately. Benchmark results show that the performance of HeightFormer achieves SOTA compared with those camera-only methods.
MRTNet: Multi-Resolution Temporal Network for Video Sentence Grounding
Dec 27, 2022



Given an untrimmed video and natural language query, video sentence grounding aims to localize the target temporal moment in the video. Existing methods mainly tackle this task by matching and aligning semantics of the descriptive sentence and video segments on a single temporal resolution, while neglecting the temporal consistency of video content in different resolutions. In this work, we propose a novel multi-resolution temporal video sentence grounding network: MRTNet, which consists of a multi-modal feature encoder, a Multi-Resolution Temporal (MRT) module, and a predictor module. MRT module is an encoder-decoder network, and output features in the decoder part are in conjunction with Transformers to predict the final start and end timestamps. Particularly, our MRT module is hot-pluggable, which means it can be seamlessly incorporated into any anchor-free models. Besides, we utilize a hybrid loss to supervise cross-modal features in MRT module for more accurate grounding in three scales: frame-level, clip-level and sequence-level. Extensive experiments on three prevalent datasets have shown the effectiveness of MRTNet.
Improving Long Tailed Document-Level Relation Extraction via Easy Relation Augmentation and Contrastive Learning
May 21, 2022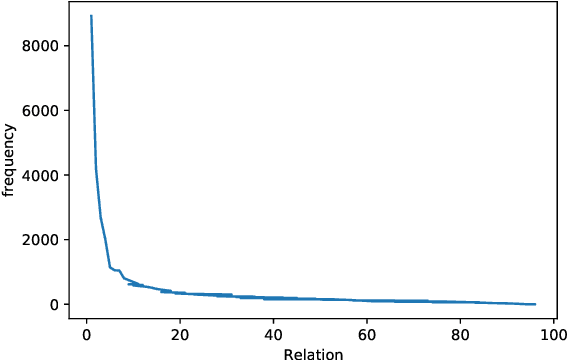
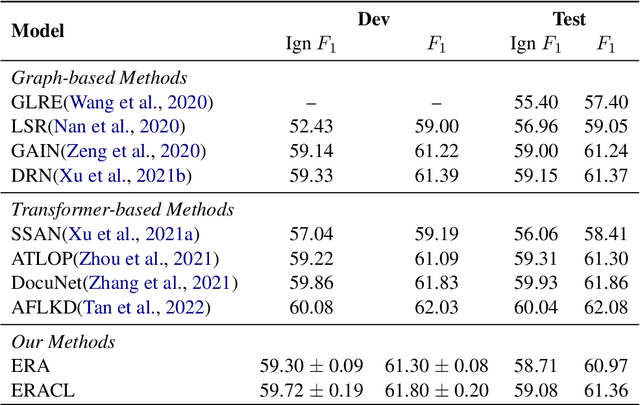
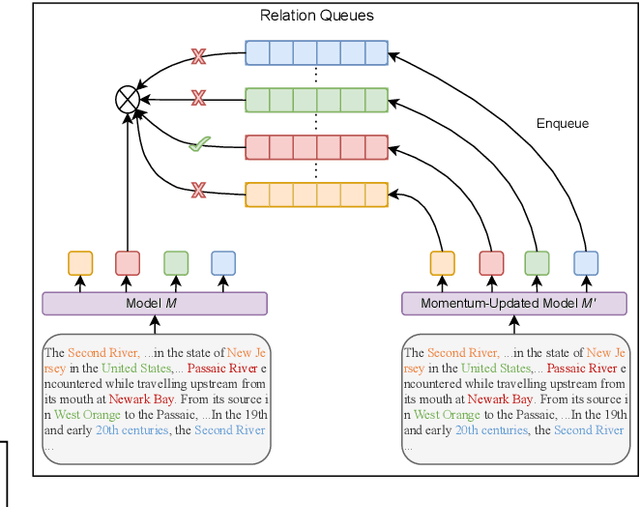
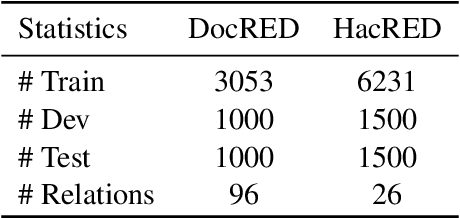
Towards real-world information extraction scenario, research of relation extraction is advancing to document-level relation extraction(DocRE). Existing approaches for DocRE aim to extract relation by encoding various information sources in the long context by novel model architectures. However, the inherent long-tailed distribution problem of DocRE is overlooked by prior work. We argue that mitigating the long-tailed distribution problem is crucial for DocRE in the real-world scenario. Motivated by the long-tailed distribution problem, we propose an Easy Relation Augmentation(ERA) method for improving DocRE by enhancing the performance of tailed relations. In addition, we further propose a novel contrastive learning framework based on our ERA, i.e., ERACL, which can further improve the model performance on tailed relations and achieve competitive overall DocRE performance compared to the state-of-arts.
F3A-GAN: Facial Flow for Face Animation with Generative Adversarial Networks
May 13, 2022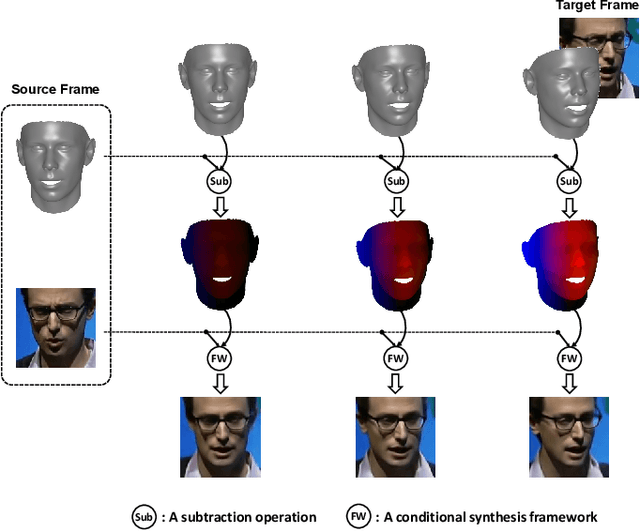



Formulated as a conditional generation problem, face animation aims at synthesizing continuous face images from a single source image driven by a set of conditional face motion. Previous works mainly model the face motion as conditions with 1D or 2D representation (e.g., action units, emotion codes, landmark), which often leads to low-quality results in some complicated scenarios such as continuous generation and largepose transformation. To tackle this problem, the conditions are supposed to meet two requirements, i.e., motion information preserving and geometric continuity. To this end, we propose a novel representation based on a 3D geometric flow, termed facial flow, to represent the natural motion of the human face at any pose. Compared with other previous conditions, the proposed facial flow well controls the continuous changes to the face. After that, in order to utilize the facial flow for face editing, we build a synthesis framework generating continuous images with conditional facial flows. To fully take advantage of the motion information of facial flows, a hierarchical conditional framework is designed to combine the extracted multi-scale appearance features from images and motion features from flows in a hierarchical manner. The framework then decodes multiple fused features back to images progressively. Experimental results demonstrate the effectiveness of our method compared to other state-of-the-art methods.
D3T-GAN: Data-Dependent Domain Transfer GANs for Few-shot Image Generation
May 12, 2022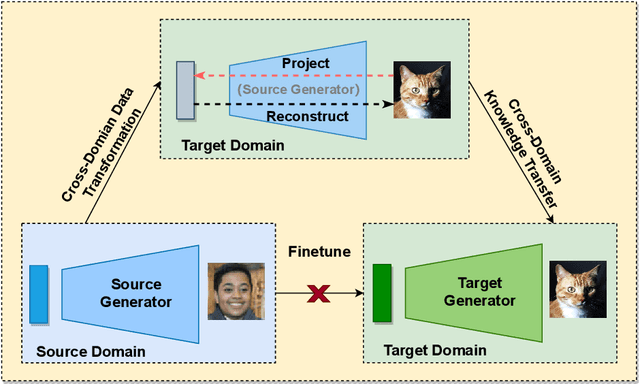
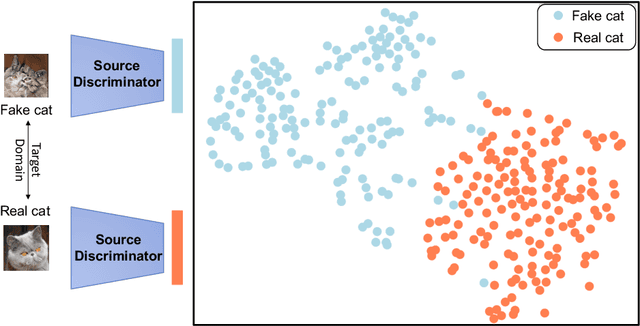
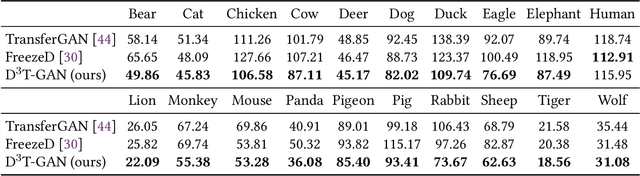
As an important and challenging problem, few-shot image generation aims at generating realistic images through training a GAN model given few samples. A typical solution for few-shot generation is to transfer a well-trained GAN model from a data-rich source domain to the data-deficient target domain. In this paper, we propose a novel self-supervised transfer scheme termed D3T-GAN, addressing the cross-domain GANs transfer in few-shot image generation. Specifically, we design two individual strategies to transfer knowledge between generators and discriminators, respectively. To transfer knowledge between generators, we conduct a data-dependent transformation, which projects and reconstructs the target samples into the source generator space. Then, we perform knowledge transfer from transformed samples to generated samples. To transfer knowledge between discriminators, we design a multi-level discriminant knowledge distillation from the source discriminator to the target discriminator on both the real and fake samples. Extensive experiments show that our method improve the quality of generated images and achieves the state-of-the-art FID scores on commonly used datasets.
MGH: Metadata Guided Hypergraph Modeling for Unsupervised Person Re-identification
Oct 12, 2021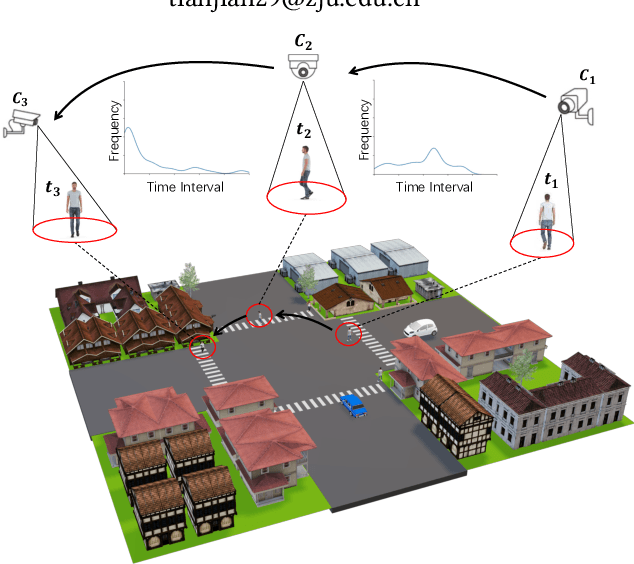

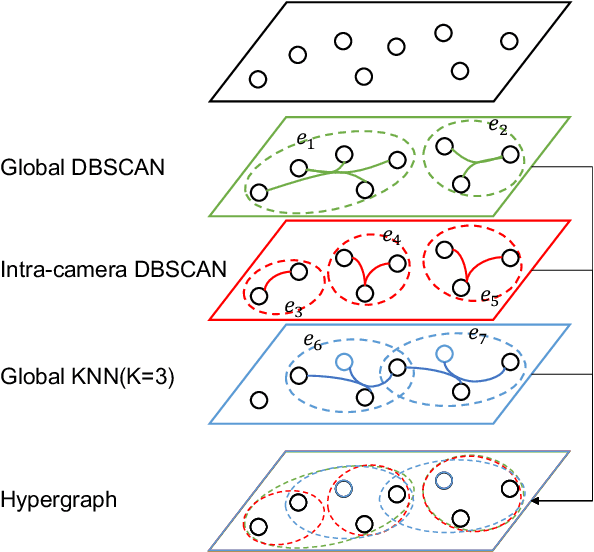
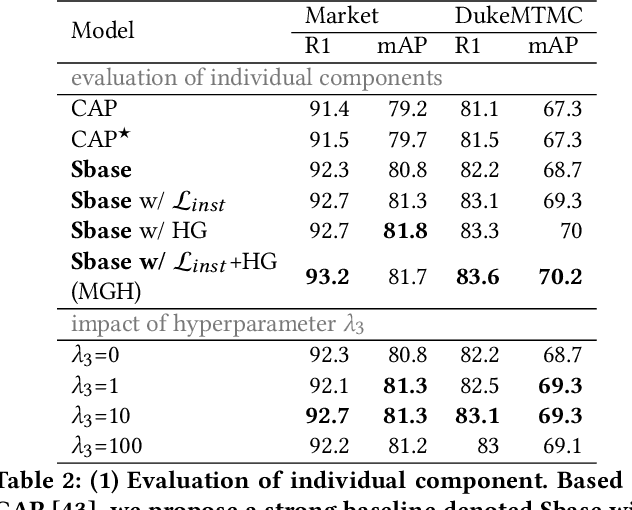
As a challenging task, unsupervised person ReID aims to match the same identity with query images which does not require any labeled information. In general, most existing approaches focus on the visual cues only, leaving potentially valuable auxiliary metadata information (e.g., spatio-temporal context) unexplored. In the real world, such metadata is normally available alongside captured images, and thus plays an important role in separating several hard ReID matches. With this motivation in mind, we propose~\textbf{MGH}, a novel unsupervised person ReID approach that uses meta information to construct a hypergraph for feature learning and label refinement. In principle, the hypergraph is composed of camera-topology-aware hyperedges, which can model the heterogeneous data correlations across cameras. Taking advantage of label propagation on the hypergraph, the proposed approach is able to effectively refine the ReID results, such as correcting the wrong labels or smoothing the noisy labels. Given the refined results, We further present a memory-based listwise loss to directly optimize the average precision in an approximate manner. Extensive experiments on three benchmarks demonstrate the effectiveness of the proposed approach against the state-of-the-art.