 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat and Where: Learn to Plug Adapters via NAS for Multi-Domain Learning
Jul 24, 2020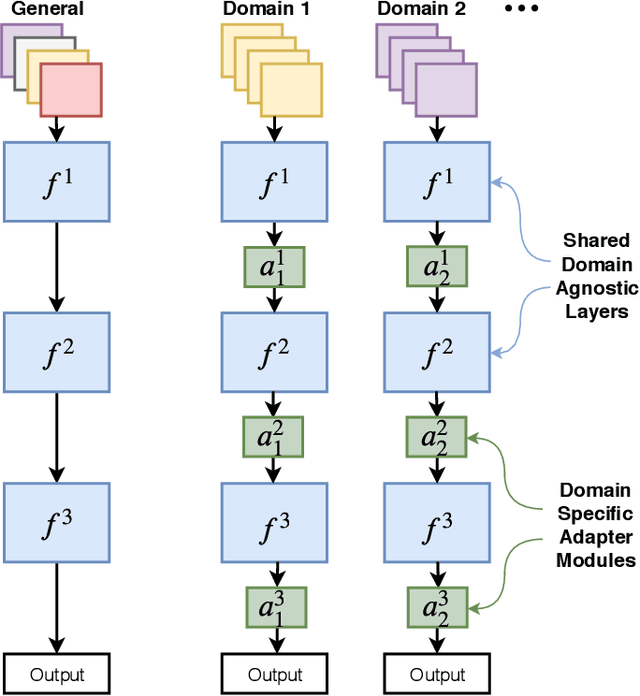
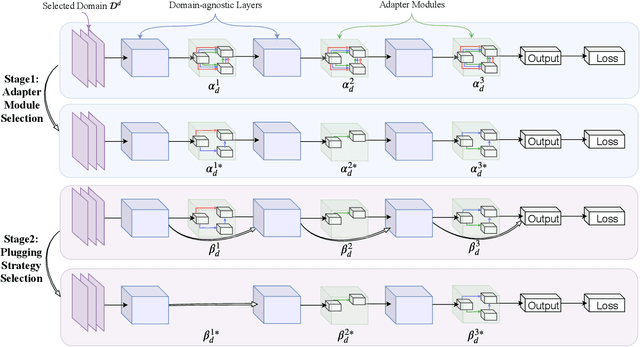
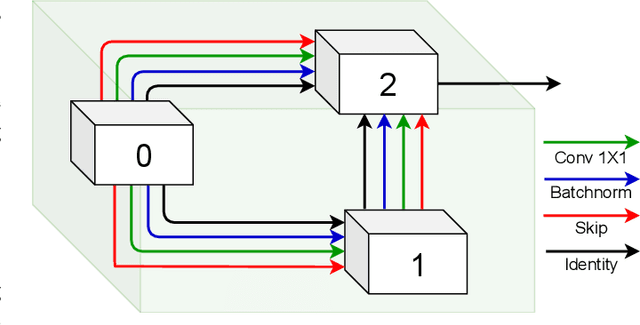
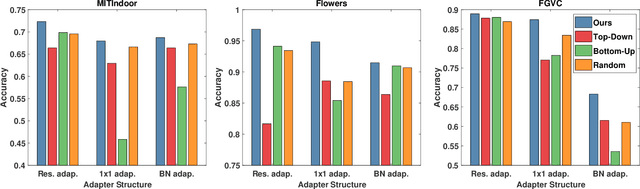
As an important and challenging problem, multi-domain learning (MDL) typically seeks for a set of effective lightweight domain-specific adapter modules plugged into a common domain-agnostic network. Usually, existing ways of adapter plugging and structure design are handcrafted and fixed for all domains before model learning, resulting in the learning inflexibility and computational intensiveness. With this motivation, we propose to learn a data-driven adapter plugging strategy with Neural Architecture Search (NAS), which automatically determines where to plug for those adapter modules. Furthermore, we propose a NAS-adapter module for adapter structure design in a NAS-driven learning scheme, which automatically discovers effective adapter module structures for different domains. Experimental results demonstrate the effectiveness of our MDL model against existing approaches under the conditions of comparable performance. We will release the code, baselines, and training statistics for all models to facilitate future research.
Few-Shot Class-Incremental Learning via Feature Space Composition
Jun 28, 2020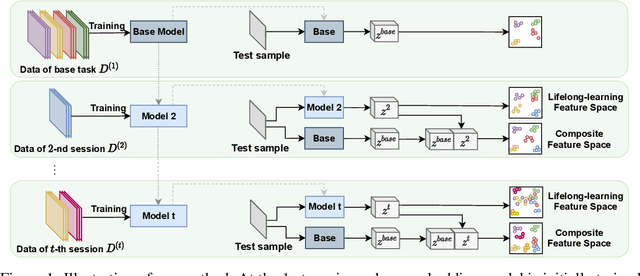
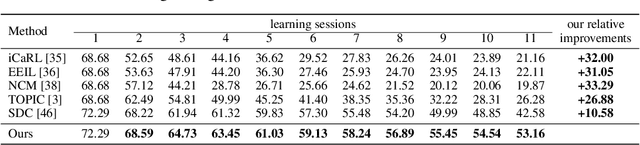
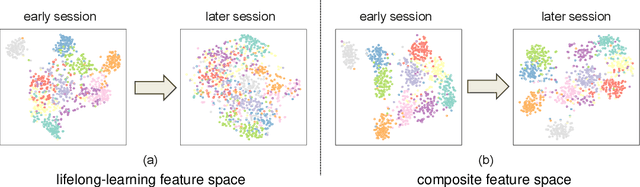

As a challenging problem in machine learning, few-shot class-incremental learning asynchronously learns a sequence of tasks, acquiring the new knowledge from new tasks (with limited new samples) while keeping the learned knowledge from previous tasks (with old samples discarded). In general, existing approaches resort to one unified feature space for balancing old-knowledge preserving and new-knowledge adaptation. With a limited embedding capacity of feature representation, the unified feature space often makes the learner suffer from semantic drift or overfitting as the number of tasks increases. With this motivation, we propose a novel few-shot class-incremental learning pipeline based on a composite representation space, which makes old-knowledge preserving and new-knowledge adaptation mutually compatible by feature space composition (enlarging the embedding capacity). The composite representation space is generated by integrating two space components (i.e. stable base knowledge space and dynamic lifelong-learning knowledge space) in terms of distance metric construction. With the composite feature space, our method performs remarkably well on the CUB200 and CIFAR100 datasets, outperforming the state-of-the-art algorithms by 10.58% and 14.65% respectively.
Epoch-evolving Gaussian Process Guided Learning
Jun 25, 2020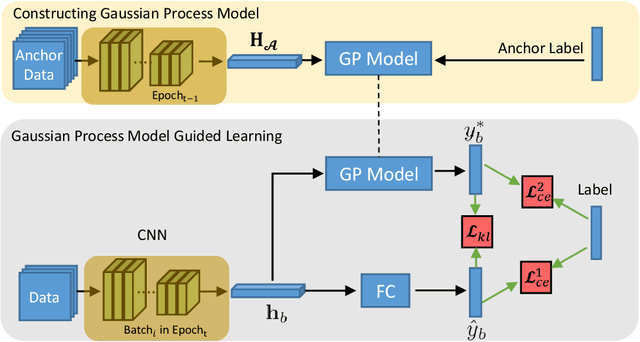
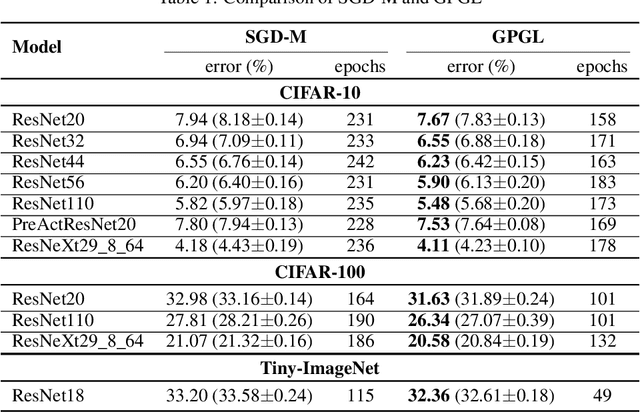
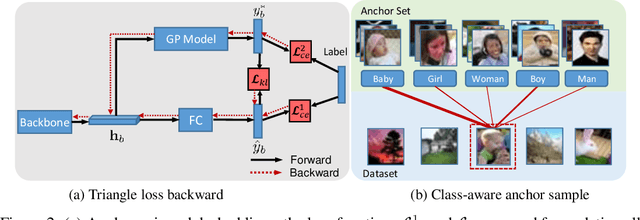
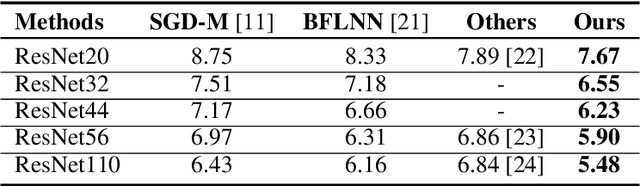
In this paper, we propose a novel learning scheme called epoch-evolving Gaussian Process Guided Learning (GPGL), which aims at characterizing the correlation information between the batch-level distribution and the global data distribution. Such correlation information is encoded as context labels and needs renewal every epoch. With the guidance of the context label and ground truth label, GPGL scheme provides a more efficient optimization through updating the model parameters with a triangle consistency loss. Furthermore, our GPGL scheme can be further generalized and naturally applied to the current deep models, outperforming the existing batch-based state-of-the-art models on mainstream datasets (CIFAR-10, CIFAR-100, and Tiny-ImageNet) remarkably.
ResKD: Residual-Guided Knowledge Distillation
Jun 09, 2020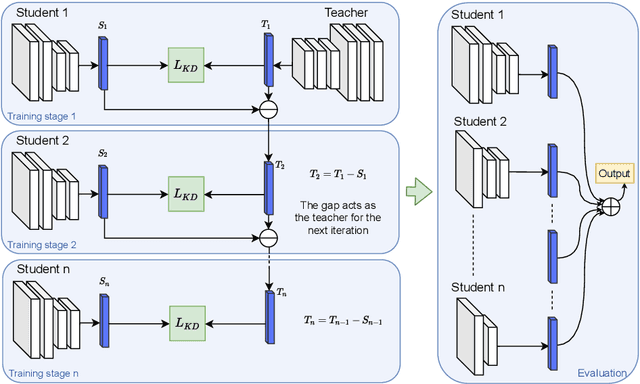
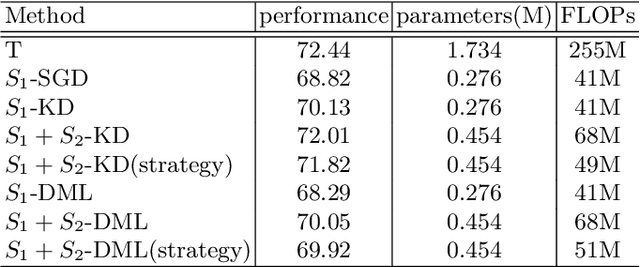
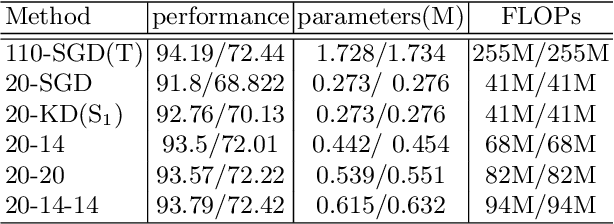
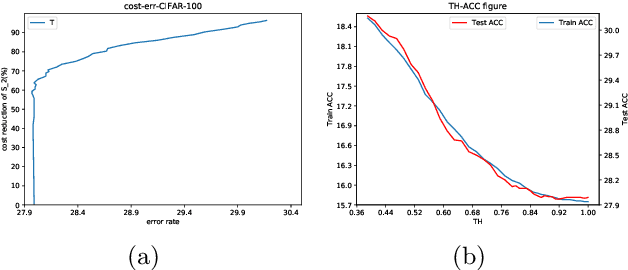
Knowledge distillation has emerged as a promising technique for compressing neural networks. Due to the capacity gap between a heavy teacher and a lightweight student, there exists a significant performance gap between them. In this paper, we see knowledge distillation in a fresh light, using the knowledge gap between a teacher and a student as guidance to train a lighter-weight student called res-student. The combination of a normal student and a res-student becomes a new student. Such a residual-guided process can be repeated. Experimental results show that we achieve competitive results on the CIFAR10/100, Tiny-ImageNet, and ImageNet datasets.
A Survey on Generative Adversarial Networks: Variants, Applications, and Training
Jun 09, 2020

The Generative Models have gained considerable attention in the field of unsupervised learning via a new and practical framework called Generative Adversarial Networks (GAN) due to its outstanding data generation capability. Many models of GAN have proposed, and several practical applications emerged in various domains of computer vision and machine learning. Despite GAN's excellent success, there are still obstacles to stable training. The problems are due to Nash-equilibrium, internal covariate shift, mode collapse, vanishing gradient, and lack of proper evaluation metrics. Therefore, stable training is a crucial issue in different applications for the success of GAN. Herein, we survey several training solutions proposed by different researchers to stabilize GAN training. We survey, (I) the original GAN model and its modified classical versions, (II) detail analysis of various GAN applications in different domains, (III) detail study about the various GAN training obstacles as well as training solutions. Finally, we discuss several new issues as well as research outlines to the topic.
BANet: Bidirectional Aggregation Network with Occlusion Handling for Panoptic Segmentation
Mar 31, 2020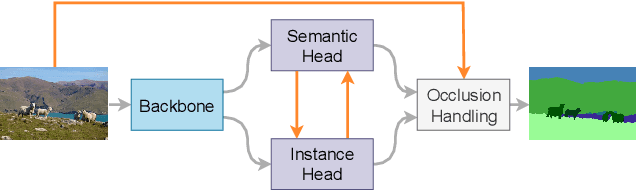
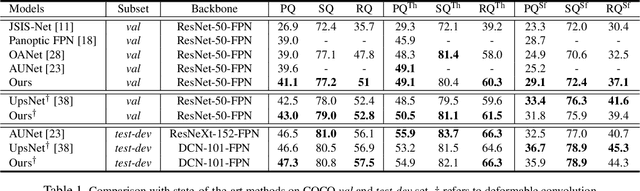
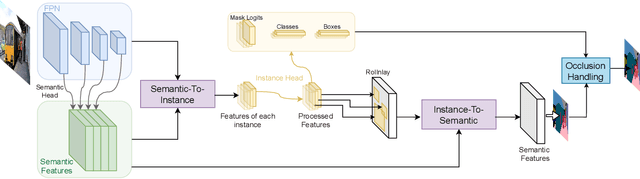

Panoptic segmentation aims to perform instance segmentation for foreground instances and semantic segmentation for background stuff simultaneously. The typical top-down pipeline concentrates on two key issues: 1) how to effectively model the intrinsic interaction between semantic segmentation and instance segmentation, and 2) how to properly handle occlusion for panoptic segmentation. Intuitively, the complementarity between semantic segmentation and instance segmentation can be leveraged to improve the performance. Besides, we notice that using detection/mask scores is insufficient for resolving the occlusion problem. Motivated by these observations, we propose a novel deep panoptic segmentation scheme based on a bidirectional learning pipeline. Moreover, we introduce a plug-and-play occlusion handling algorithm to deal with the occlusion between different object instances. The experimental results on COCO panoptic benchmark validate the effectiveness of our proposed method. Codes will be released soon at https://github.com/Mooonside/BANet.