 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
Apr 08, 2026Building world models with spatial consistency and real-time interactivity remains a fundamental challenge in computer vision. Current video generation paradigms often struggle with a lack of spatial persistence and insufficient visual realism, making it difficult to support seamless navigation in complex environments. To address these challenges, we propose INSPATIO-WORLD, a novel real-time framework capable of recovering and generating high-fidelity, dynamic interactive scenes from a single reference video. At the core of our approach is a Spatiotemporal Autoregressive (STAR) architecture, which enables consistent and controllable scene evolution through two tightly coupled components: Implicit Spatiotemporal Cache aggregates reference and historical observations into a latent world representation, ensuring global consistency during long-horizon navigation; Explicit Spatial Constraint Module enforces geometric structure and translates user interactions into precise and physically plausible camera trajectories. Furthermore, we introduce Joint Distribution Matching Distillation (JDMD). By using real-world data distributions as a regularizing guide, JDMD effectively overcomes the fidelity degradation typically caused by over-reliance on synthetic data. Extensive experiments demonstrate that INSPATIO-WORLD significantly outperforms existing state-of-the-art (SOTA) models in spatial consistency and interaction precision, ranking first among real-time interactive methods on the WorldScore-Dynamic benchmark, and establishing a practical pipeline for navigating 4D environments reconstructed from monocular videos.
SparseCam4D: Spatio-Temporally Consistent 4D Reconstruction from Sparse Cameras
Mar 27, 2026High-quality 4D reconstruction enables photorealistic and immersive rendering of the dynamic real world. However, unlike static scenes that can be fully captured with a single camera, high-quality dynamic scenes typically require dense arrays of tens or even hundreds of synchronized cameras. Dependence on such costly lab setups severely limits practical scalability. The reliance on such costly lab setups severely limits practical scalability. To this end, we propose a sparse-camera dynamic reconstruction framework that exploits abundant yet inconsistent generative observations. Our key innovation is the Spatio-Temporal Distortion Field, which provides a unified mechanism for modeling inconsistencies in generative observations across both spatial and temporal dimensions. Building on this, we develop a complete pipeline that enables 4D reconstruction from sparse and uncalibrated camera inputs. We evaluate our method on multi-camera dynamic scene benchmarks, achieving spatio-temporally consistent high-fidelity renderings and significantly outperforming existing approaches.
InSpatio-WorldFM: An Open-Source Real-Time Generative Frame Model
Mar 12, 2026We present InSpatio-WorldFM, an open-source real-time frame model for spatial intelligence. Unlike video-based world models that rely on sequential frame generation and incur substantial latency due to window-level processing, InSpatio-WorldFM adopts a frame-based paradigm that generates each frame independently, enabling low-latency real-time spatial inference. By enforcing multi-view spatial consistency through explicit 3D anchors and implicit spatial memory, the model preserves global scene geometry while maintaining fine-grained visual details across viewpoint changes. We further introduce a progressive three-stage training pipeline that transforms a pretrained image diffusion model into a controllable frame model and finally into a real-time generator through few-step distillation. Experimental results show that InSpatio-WorldFM achieves strong multi-view consistency while supporting interactive exploration on consumer-grade GPUs, providing an efficient alternative to traditional video-based world models for real-time world simulation.
StarGen: A Spatiotemporal Autoregression Framework with Video Diffusion Model for Scalable and Controllable Scene Generation
Jan 10, 2025



Recent advances in large reconstruction and generative models have significantly improved scene reconstruction and novel view generation. However, due to compute limitations, each inference with these large models is confined to a small area, making long-range consistent scene generation challenging. To address this, we propose StarGen, a novel framework that employs a pre-trained video diffusion model in an autoregressive manner for long-range scene generation. The generation of each video clip is conditioned on the 3D warping of spatially adjacent images and the temporally overlapping image from previously generated clips, improving spatiotemporal consistency in long-range scene generation with precise pose control. The spatiotemporal condition is compatible with various input conditions, facilitating diverse tasks, including sparse view interpolation, perpetual view generation, and layout-conditioned city generation. Quantitative and qualitative evaluations demonstrate StarGen's superior scalability, fidelity, and pose accuracy compared to state-of-the-art methods.
EC-SfM: Efficient Covisibility-based Structure-from-Motion for Both Sequential and Unordered Images
Feb 21, 2023



Structure-from-Motion is a technology used to obtain scene structure through image collection, which is a fundamental problem in computer vision. For unordered Internet images, SfM is very slow due to the lack of prior knowledge about image overlap. For sequential images, knowing the large overlap between adjacent frames, SfM can adopt a variety of acceleration strategies, which are only applicable to sequential data. To further improve the reconstruction efficiency and break the gap of strategies between these two kinds of data, this paper presents an efficient covisibility-based incremental SfM. Different from previous methods, we exploit covisibility and registration dependency to describe the image connection which is suitable to any kind of data. Based on this general image connection, we propose a unified framework to efficiently reconstruct sequential images, unordered images, and the mixture of these two. Experiments on the unordered images and mixed data verify the effectiveness of the proposed method, which is three times faster than the state of the art on feature matching, and an order of magnitude faster on reconstruction without sacrificing the accuracy. The source code is publicly available at https://github.com/openxrlab/xrsfm
Generative Category-Level Shape and Pose Estimation with Semantic Primitives
Oct 03, 2022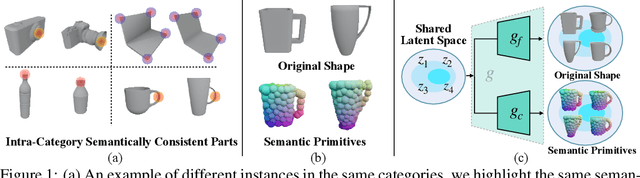
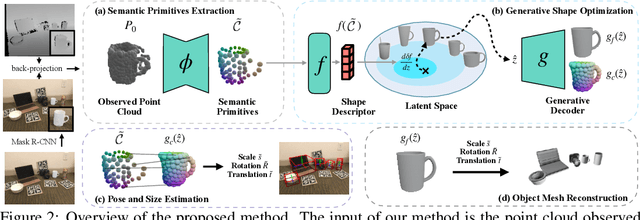
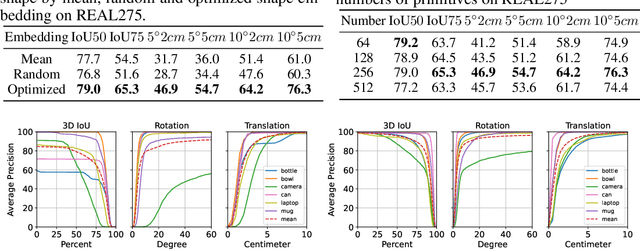

Empowering autonomous agents with 3D understanding for daily objects is a grand challenge in robotics applications. When exploring in an unknown environment, existing methods for object pose estimation are still not satisfactory due to the diversity of object shapes. In this paper, we propose a novel framework for category-level object shape and pose estimation from a single RGB-D image. To handle the intra-category variation, we adopt a semantic primitive representation that encodes diverse shapes into a unified latent space, which is the key to establish reliable correspondences between observed point clouds and estimated shapes. Then, by using a SIM(3)-invariant shape descriptor, we gracefully decouple the shape and pose of an object, thus supporting latent shape optimization of target objects in arbitrary poses. Extensive experiments show that the proposed method achieves SOTA pose estimation performance and better generalization in the real-world dataset. Code and video are available at https://zju3dv.github.io/gCasp