 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeoMeBench: Towards Robust Benchmarking of LLMs in Organic Mechanism Elucidation and Reasoning
Oct 09, 2025Organic reaction mechanisms are the stepwise elementary reactions by which reactants form intermediates and products, and are fundamental to understanding chemical reactivity and designing new molecules and reactions. Although large language models (LLMs) have shown promise in understanding chemical tasks such as synthesis design, it is unclear to what extent this reflects genuine chemical reasoning capabilities, i.e., the ability to generate valid intermediates, maintain chemical consistency, and follow logically coherent multi-step pathways. We address this by introducing oMeBench, the first large-scale, expert-curated benchmark for organic mechanism reasoning in organic chemistry. It comprises over 10,000 annotated mechanistic steps with intermediates, type labels, and difficulty ratings. Furthermore, to evaluate LLM capability more precisely and enable fine-grained scoring, we propose oMeS, a dynamic evaluation framework that combines step-level logic and chemical similarity. We analyze the performance of state-of-the-art LLMs, and our results show that although current models display promising chemical intuition, they struggle with correct and consistent multi-step reasoning. Notably, we find that using prompting strategy and fine-tuning a specialist model on our proposed dataset increases performance by 50% over the leading closed-source model. We hope that oMeBench will serve as a rigorous foundation for advancing AI systems toward genuine chemical reasoning.
Exploring Polyglot Harmony: On Multilingual Data Allocation for Large Language Models Pretraining
Sep 19, 2025Large language models (LLMs) have become integral to a wide range of applications worldwide, driving an unprecedented global demand for effective multilingual capabilities. Central to achieving robust multilingual performance is the strategic allocation of language proportions within training corpora. However, determining optimal language ratios is highly challenging due to intricate cross-lingual interactions and sensitivity to dataset scale. This paper introduces Climb (Cross-Lingual Interaction-aware Multilingual Balancing), a novel framework designed to systematically optimize multilingual data allocation. At its core, Climb introduces a cross-lingual interaction-aware language ratio, explicitly quantifying each language's effective allocation by capturing inter-language dependencies. Leveraging this ratio, Climb proposes a principled two-step optimization procedure--first equalizing marginal benefits across languages, then maximizing the magnitude of the resulting language allocation vectors--significantly simplifying the inherently complex multilingual optimization problem. Extensive experiments confirm that Climb can accurately measure cross-lingual interactions across various multilingual settings. LLMs trained with Climb-derived proportions consistently achieve state-of-the-art multilingual performance, even achieving competitive performance with open-sourced LLMs trained with more tokens.
HyP-ASO: A Hybrid Policy-based Adaptive Search Optimization Framework for Large-Scale Integer Linear Programs
Sep 19, 2025



Directly solving large-scale Integer Linear Programs (ILPs) using traditional solvers is slow due to their NP-hard nature. While recent frameworks based on Large Neighborhood Search (LNS) can accelerate the solving process, their performance is often constrained by the difficulty in generating sufficiently effective neighborhoods. To address this challenge, we propose HyP-ASO, a hybrid policy-based adaptive search optimization framework that combines a customized formula with deep Reinforcement Learning (RL). The formula leverages feasible solutions to calculate the selection probabilities for each variable in the neighborhood generation process, and the RL policy network predicts the neighborhood size. Extensive experiments demonstrate that HyP-ASO significantly outperforms existing LNS-based approaches for large-scale ILPs. Additional experiments show it is lightweight and highly scalable, making it well-suited for solving large-scale ILPs.
Gradient-Attention Guided Dual-Masking Synergetic Framework for Robust Text-based Person Retrieval
Sep 11, 2025Although Contrastive Language-Image Pre-training (CLIP) exhibits strong performance across diverse vision tasks, its application to person representation learning faces two critical challenges: (i) the scarcity of large-scale annotated vision-language data focused on person-centric images, and (ii) the inherent limitations of global contrastive learning, which struggles to maintain discriminative local features crucial for fine-grained matching while remaining vulnerable to noisy text tokens. This work advances CLIP for person representation learning through synergistic improvements in data curation and model architecture. First, we develop a noise-resistant data construction pipeline that leverages the in-context learning capabilities of MLLMs to automatically filter and caption web-sourced images. This yields WebPerson, a large-scale dataset of 5M high-quality person-centric image-text pairs. Second, we introduce the GA-DMS (Gradient-Attention Guided Dual-Masking Synergetic) framework, which improves cross-modal alignment by adaptively masking noisy textual tokens based on the gradient-attention similarity score. Additionally, we incorporate masked token prediction objectives that compel the model to predict informative text tokens, enhancing fine-grained semantic representation learning. Extensive experiments show that GA-DMS achieves state-of-the-art performance across multiple benchmarks.
Adapt in the Wild: Test-Time Entropy Minimization with Sharpness and Feature Regularization
Sep 05, 2025Test-time adaptation (TTA) may fail to improve or even harm the model performance when test data have: 1) mixed distribution shifts, 2) small batch sizes, 3) online imbalanced label distribution shifts. This is often a key obstacle preventing existing TTA methods from being deployed in the real world. In this paper, we investigate the unstable reasons and find that the batch norm layer is a crucial factor hindering TTA stability. Conversely, TTA can perform more stably with batch-agnostic norm layers, i.e., group or layer norm. However, we observe that TTA with group and layer norms does not always succeed and still suffers many failure cases, i.e., the model collapses into trivial solutions by assigning the same class label for all samples. By digging into this, we find that, during the collapse process: 1) the model gradients often undergo an initial explosion followed by rapid degradation, suggesting that certain noisy test samples with large gradients may disrupt adaptation; and 2) the model representations tend to exhibit high correlations and classification bias. To address this, we first propose a sharpness-aware and reliable entropy minimization method, called SAR, for stabilizing TTA from two aspects: 1) remove partial noisy samples with large gradients, 2) encourage model weights to go to a flat minimum so that the model is robust to the remaining noisy samples. Based on SAR, we further introduce SAR^2 to prevent representation collapse with two regularizers: 1) a redundancy regularizer to reduce inter-dimensional correlations among centroid-invariant features; and 2) an inequity regularizer to maximize the prediction entropy of a prototype centroid, thereby penalizing biased representations toward any specific class. Promising results demonstrate that our methods perform more stably over prior methods and are computationally efficient under the above wild test scenarios.
Single Agent Robust Deep Reinforcement Learning for Bus Fleet Control
Aug 28, 2025



Bus bunching remains a challenge for urban transit due to stochastic traffic and passenger demand. Traditional solutions rely on multi-agent reinforcement learning (MARL) in loop-line settings, which overlook realistic operations characterized by heterogeneous routes, timetables, fluctuating demand, and varying fleet sizes. We propose a novel single-agent reinforcement learning (RL) framework for bus holding control that avoids the data imbalance and convergence issues of MARL under near-realistic simulation. A bidirectional timetabled network with dynamic passenger demand is constructed. The key innovation is reformulating the multi-agent problem into a single-agent one by augmenting the state space with categorical identifiers (vehicle ID, station ID, time period) in addition to numerical features (headway, occupancy, velocity). This high-dimensional encoding enables single-agent policies to capture inter-agent dependencies, analogous to projecting non-separable inputs into a higher-dimensional space. We further design a structured reward function aligned with operational goals: instead of exponential penalties on headway deviations, a ridge-shaped reward balances uniform headways and schedule adherence. Experiments show that our modified soft actor-critic (SAC) achieves more stable and superior performance than benchmarks, including MADDPG (e.g., -430k vs. -530k under stochastic conditions). These results demonstrate that single-agent deep RL, when enhanced with categorical structuring and schedule-aware rewards, can effectively manage bus holding in non-loop, real-world contexts. This paradigm offers a robust, scalable alternative to MARL frameworks, particularly where agent-specific experiences are imbalanced.
Optimizing Multi-Modal Trackers via Sensitivity-aware Regularized Tuning
Aug 24, 2025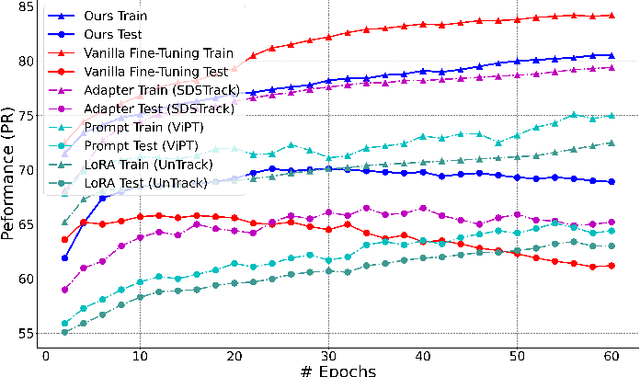

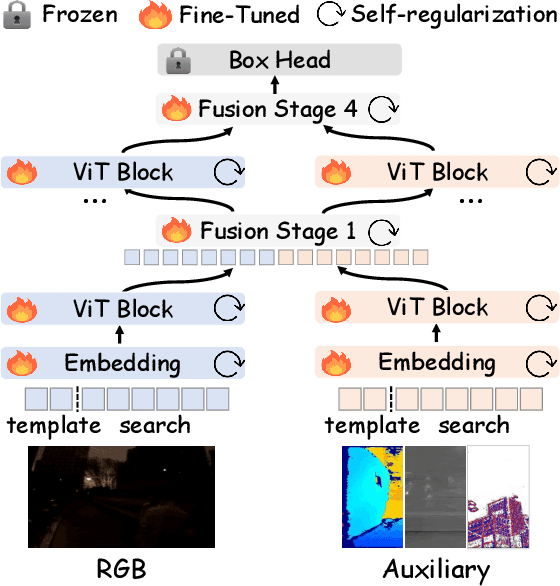
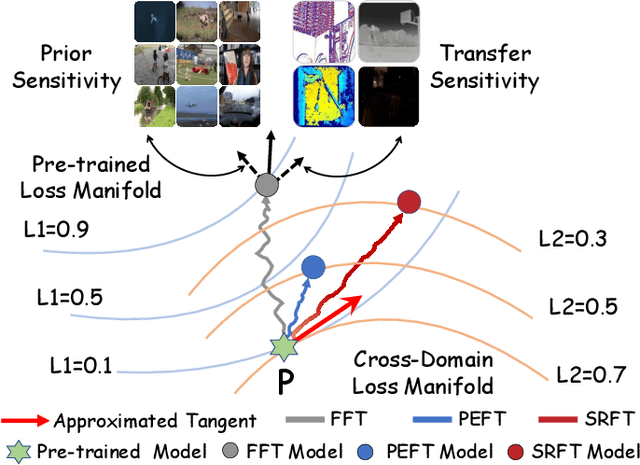
This paper tackles the critical challenge of optimizing multi-modal trackers by effectively adapting the pre-trained models for RGB data. Existing fine-tuning paradigms oscillate between excessive freedom and over-restriction, both leading to a suboptimal plasticity-stability trade-off. To mitigate this dilemma, we propose a novel sensitivity-aware regularized tuning framework, which delicately refines the learning process by incorporating intrinsic parameter sensitivities. Through a comprehensive investigation from pre-trained to multi-modal contexts, we identify that parameters sensitive to pivotal foundational patterns and cross-domain shifts are primary drivers of this issue. Specifically, we first analyze the tangent space of pre-trained weights to measure and orient prior sensitivities, dedicated to preserving generalization. Then, we further explore transfer sensitivities during the tuning phase, emphasizing adaptability and stability. By incorporating these sensitivities as regularization terms, our method significantly enhances the transferability across modalities. Extensive experiments showcase the superior performance of the proposed method, surpassing current state-of-the-art techniques across various multi-modal tracking. The source code and models will be publicly available at https://github.com/zhiwen-xdu/SRTrack.
Tactile-Guided Robotic Ultrasound: Mapping Preplanned Scan Paths for Intercostal Imaging
Jul 27, 2025



Medical ultrasound (US) imaging is widely used in clinical examinations due to its portability, real-time capability, and radiation-free nature. To address inter- and intra-operator variability, robotic ultrasound systems have gained increasing attention. However, their application in challenging intercostal imaging remains limited due to the lack of an effective scan path generation method within the constrained acoustic window. To overcome this challenge, we explore the potential of tactile cues for characterizing subcutaneous rib structures as an alternative signal for ultrasound segmentation-free bone surface point cloud extraction. Compared to 2D US images, 1D tactile-related signals offer higher processing efficiency and are less susceptible to acoustic noise and artifacts. By leveraging robotic tracking data, a sparse tactile point cloud is generated through a few scans along the rib, mimicking human palpation. To robustly map the scanning trajectory into the intercostal space, the sparse tactile bone location point cloud is first interpolated to form a denser representation. This refined point cloud is then registered to an image-based dense bone surface point cloud, enabling accurate scan path mapping for individual patients. Additionally, to ensure full coverage of the object of interest, we introduce an automated tilt angle adjustment method to visualize structures beneath the bone. To validate the proposed method, we conducted comprehensive experiments on four distinct phantoms. The final scanning waypoint mapping achieved Mean Nearest Neighbor Distance (MNND) and Hausdorff distance (HD) errors of 3.41 mm and 3.65 mm, respectively, while the reconstructed object beneath the bone had errors of 0.69 mm and 2.2 mm compared to the CT ground truth.
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
Jul 08, 2025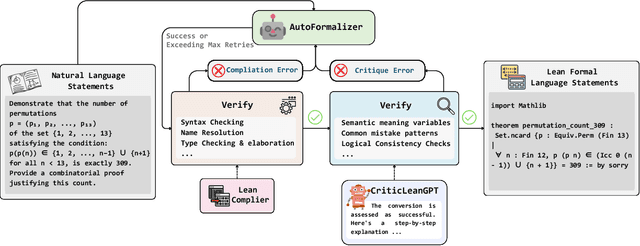

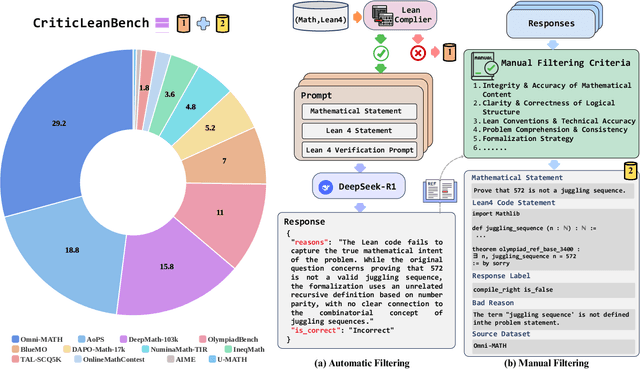
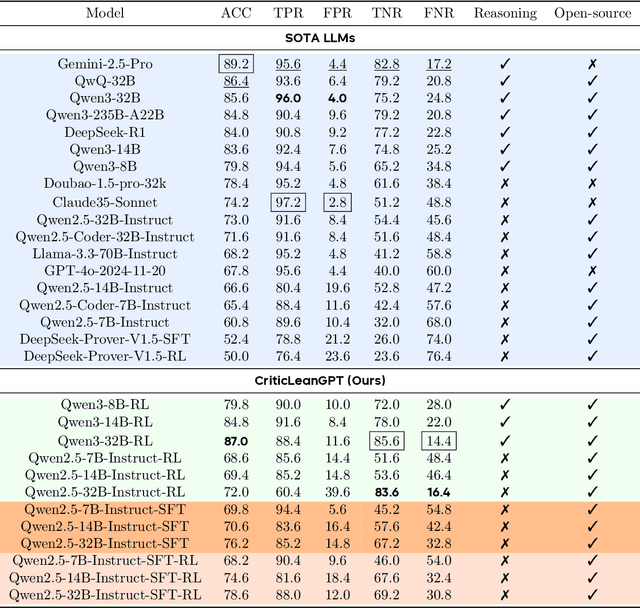
Translating natural language mathematical statements into formal, executable code is a fundamental challenge in automated theorem proving. While prior work has focused on generation and compilation success, little attention has been paid to the critic phase-the evaluation of whether generated formalizations truly capture the semantic intent of the original problem. In this paper, we introduce CriticLean, a novel critic-guided reinforcement learning framework that elevates the role of the critic from a passive validator to an active learning component. Specifically, first, we propose the CriticLeanGPT, trained via supervised fine-tuning and reinforcement learning, to rigorously assess the semantic fidelity of Lean 4 formalizations. Then, we introduce CriticLeanBench, a benchmark designed to measure models' ability to distinguish semantically correct from incorrect formalizations, and demonstrate that our trained CriticLeanGPT models can significantly outperform strong open- and closed-source baselines. Building on the CriticLean framework, we construct FineLeanCorpus, a dataset comprising over 285K problems that exhibits rich domain diversity, broad difficulty coverage, and high correctness based on human evaluation. Overall, our findings highlight that optimizing the critic phase is essential for producing reliable formalizations, and we hope our CriticLean will provide valuable insights for future advances in formal mathematical reasoning.
MuRating: A High Quality Data Selecting Approach to Multilingual Large Language Model Pretraining
Jul 02, 2025Data quality is a critical driver of large language model performance, yet existing model-based selection methods focus almost exclusively on English. We introduce MuRating, a scalable framework that transfers high-quality English data-quality signals into a single rater for 17 target languages. MuRating aggregates multiple English "raters" via pairwise comparisons to learn unified document-quality scores,then projects these judgments through translation to train a multilingual evaluator on monolingual, cross-lingual, and parallel text pairs. Applied to web data, MuRating selects balanced subsets of English and multilingual content to pretrain a 1.2 B-parameter LLaMA model. Compared to strong baselines, including QuRater, AskLLM, DCLM and so on, our approach boosts average accuracy on both English benchmarks and multilingual evaluations, with especially large gains on knowledge-intensive tasks. We further analyze translation fidelity, selection biases, and underrepresentation of narrative material, outlining directions for future work.