 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Polyglot Harmony: On Multilingual Data Allocation for Large Language Models Pretraining
Sep 19, 2025Large language models (LLMs) have become integral to a wide range of applications worldwide, driving an unprecedented global demand for effective multilingual capabilities. Central to achieving robust multilingual performance is the strategic allocation of language proportions within training corpora. However, determining optimal language ratios is highly challenging due to intricate cross-lingual interactions and sensitivity to dataset scale. This paper introduces Climb (Cross-Lingual Interaction-aware Multilingual Balancing), a novel framework designed to systematically optimize multilingual data allocation. At its core, Climb introduces a cross-lingual interaction-aware language ratio, explicitly quantifying each language's effective allocation by capturing inter-language dependencies. Leveraging this ratio, Climb proposes a principled two-step optimization procedure--first equalizing marginal benefits across languages, then maximizing the magnitude of the resulting language allocation vectors--significantly simplifying the inherently complex multilingual optimization problem. Extensive experiments confirm that Climb can accurately measure cross-lingual interactions across various multilingual settings. LLMs trained with Climb-derived proportions consistently achieve state-of-the-art multilingual performance, even achieving competitive performance with open-sourced LLMs trained with more tokens.
MuRating: A High Quality Data Selecting Approach to Multilingual Large Language Model Pretraining
Jul 02, 2025Data quality is a critical driver of large language model performance, yet existing model-based selection methods focus almost exclusively on English. We introduce MuRating, a scalable framework that transfers high-quality English data-quality signals into a single rater for 17 target languages. MuRating aggregates multiple English "raters" via pairwise comparisons to learn unified document-quality scores,then projects these judgments through translation to train a multilingual evaluator on monolingual, cross-lingual, and parallel text pairs. Applied to web data, MuRating selects balanced subsets of English and multilingual content to pretrain a 1.2 B-parameter LLaMA model. Compared to strong baselines, including QuRater, AskLLM, DCLM and so on, our approach boosts average accuracy on both English benchmarks and multilingual evaluations, with especially large gains on knowledge-intensive tasks. We further analyze translation fidelity, selection biases, and underrepresentation of narrative material, outlining directions for future work.
MuBench: Assessment of Multilingual Capabilities of Large Language Models Across 61 Languages
Jun 24, 2025Multilingual large language models (LLMs) are advancing rapidly, with new models frequently claiming support for an increasing number of languages. However, existing evaluation datasets are limited and lack cross-lingual alignment, leaving assessments of multilingual capabilities fragmented in both language and skill coverage. To address this, we introduce MuBench, a benchmark covering 61 languages and evaluating a broad range of capabilities. We evaluate several state-of-the-art multilingual LLMs and find notable gaps between claimed and actual language coverage, particularly a persistent performance disparity between English and low-resource languages. Leveraging MuBench's alignment, we propose Multilingual Consistency (MLC) as a complementary metric to accuracy for analyzing performance bottlenecks and guiding model improvement. Finally, we pretrain a suite of 1.2B-parameter models on English and Chinese with 500B tokens, varying language ratios and parallel data proportions to investigate cross-lingual transfer dynamics.
QuaDMix: Quality-Diversity Balanced Data Selection for Efficient LLM Pretraining
Apr 23, 2025



Quality and diversity are two critical metrics for the training data of large language models (LLMs), positively impacting performance. Existing studies often optimize these metrics separately, typically by first applying quality filtering and then adjusting data proportions. However, these approaches overlook the inherent trade-off between quality and diversity, necessitating their joint consideration. Given a fixed training quota, it is essential to evaluate both the quality of each data point and its complementary effect on the overall dataset. In this paper, we introduce a unified data selection framework called QuaDMix, which automatically optimizes the data distribution for LLM pretraining while balancing both quality and diversity. Specifically, we first propose multiple criteria to measure data quality and employ domain classification to distinguish data points, thereby measuring overall diversity. QuaDMix then employs a unified parameterized data sampling function that determines the sampling probability of each data point based on these quality and diversity related labels. To accelerate the search for the optimal parameters involved in the QuaDMix framework, we conduct simulated experiments on smaller models and use LightGBM for parameters searching, inspired by the RegMix method. Our experiments across diverse models and datasets demonstrate that QuaDMix achieves an average performance improvement of 7.2% across multiple benchmarks. These results outperform the independent strategies for quality and diversity, highlighting the necessity and ability to balance data quality and diversity.
POSO: Personalized Cold Start Modules for Large-scale Recommender Systems
Aug 24, 2021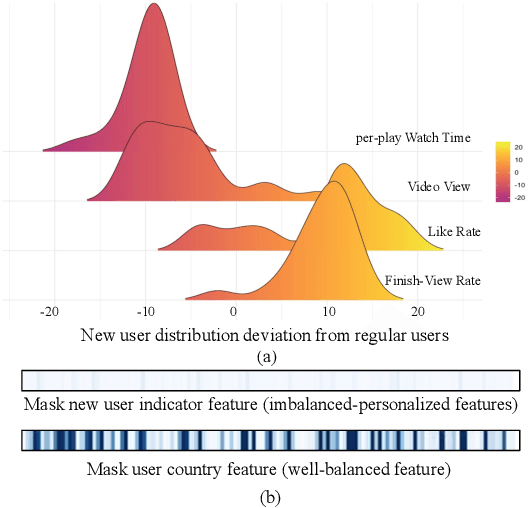
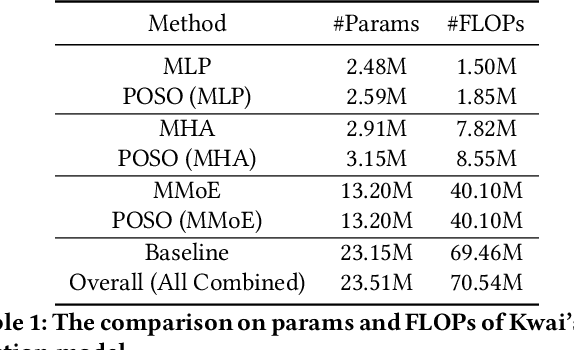
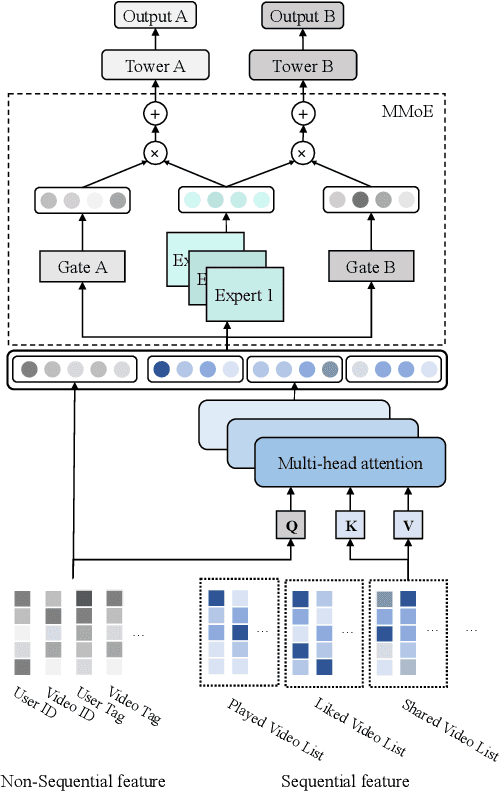
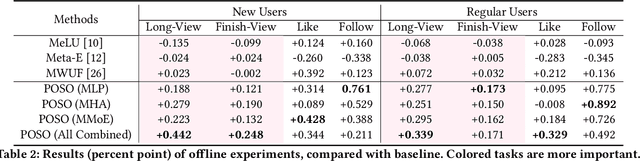
Recommendation for new users, also called user cold start, has been a well-recognized challenge for online recommender systems. Most existing methods view the crux as the lack of initial data. However, in this paper, we argue that there are neglected problems: 1) New users' behaviour follows much different distributions from regular users. 2) Although personalized features are involved, heavily imbalanced samples prevent the model from balancing new/regular user distributions, as if the personalized features are overwhelmed. We name the problem as the "submergence" of personalization. To tackle this problem, we propose a novel module: Personalized COld Start MOdules (POSO). Considering from a model architecture perspective, POSO personalizes existing modules by introducing multiple user-group-specialized sub-modules. Then, it fuses their outputs by personalized gates, resulting in comprehensive representations. In such way, POSO projects imbalanced features to even modules. POSO can be flexibly integrated into many existing modules and effectively improves their performance with negligible computational overheads. The proposed method shows remarkable advantage in industrial scenario. It has been deployed on the large-scale recommender system of Kwai, and improves new user Watch Time by a large margin (+7.75%). Moreover, POSO can be further generalized to regular users, inactive users and returning users (+2%-3% on Watch Time), as well as item cold start (+3.8% on Watch Time). Its effectiveness has also been verified on public dataset (MovieLens 20M). We believe such practical experience can be well generalized to other scenarios.