 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing 3D Fidelity of Text-to-3D using Cross-View Correspondences
Apr 16, 2024

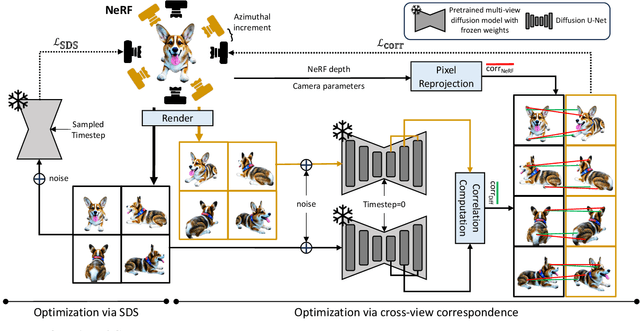

Leveraging multi-view diffusion models as priors for 3D optimization have alleviated the problem of 3D consistency, e.g., the Janus face problem or the content drift problem, in zero-shot text-to-3D models. However, the 3D geometric fidelity of the output remains an unresolved issue; albeit the rendered 2D views are realistic, the underlying geometry may contain errors such as unreasonable concavities. In this work, we propose CorrespondentDream, an effective method to leverage annotation-free, cross-view correspondences yielded from the diffusion U-Net to provide additional 3D prior to the NeRF optimization process. We find that these correspondences are strongly consistent with human perception, and by adopting it in our loss design, we are able to produce NeRF models with geometries that are more coherent with common sense, e.g., more smoothed object surface, yielding higher 3D fidelity. We demonstrate the efficacy of our approach through various comparative qualitative results and a solid user study.
HQ-Edit: A High-Quality Dataset for Instruction-based Image Editing
Apr 15, 2024



This study introduces HQ-Edit, a high-quality instruction-based image editing dataset with around 200,000 edits. Unlike prior approaches relying on attribute guidance or human feedback on building datasets, we devise a scalable data collection pipeline leveraging advanced foundation models, namely GPT-4V and DALL-E 3. To ensure its high quality, diverse examples are first collected online, expanded, and then used to create high-quality diptychs featuring input and output images with detailed text prompts, followed by precise alignment ensured through post-processing. In addition, we propose two evaluation metrics, Alignment and Coherence, to quantitatively assess the quality of image edit pairs using GPT-4V. HQ-Edits high-resolution images, rich in detail and accompanied by comprehensive editing prompts, substantially enhance the capabilities of existing image editing models. For example, an HQ-Edit finetuned InstructPix2Pix can attain state-of-the-art image editing performance, even surpassing those models fine-tuned with human-annotated data. The project page is https://thefllood.github.io/HQEdit_web.
Magic-Boost: Boost 3D Generation with Mutli-View Conditioned Diffusion
Apr 09, 2024Benefiting from the rapid development of 2D diffusion models, 3D content creation has made significant progress recently. One promising solution involves the fine-tuning of pre-trained 2D diffusion models to harness their capacity for producing multi-view images, which are then lifted into accurate 3D models via methods like fast-NeRFs or large reconstruction models. However, as inconsistency still exists and limited generated resolution, the generation results of such methods still lack intricate textures and complex geometries. To solve this problem, we propose Magic-Boost, a multi-view conditioned diffusion model that significantly refines coarse generative results through a brief period of SDS optimization ($\sim15$min). Compared to the previous text or single image based diffusion models, Magic-Boost exhibits a robust capability to generate images with high consistency from pseudo synthesized multi-view images. It provides precise SDS guidance that well aligns with the identity of the input images, enriching the local detail in both geometry and texture of the initial generative results. Extensive experiments show Magic-Boost greatly enhances the coarse inputs and generates high-quality 3D assets with rich geometric and textural details. (Project Page: https://magic-research.github.io/magic-boost/)
X-Portrait: Expressive Portrait Animation with Hierarchical Motion Attention
Mar 27, 2024We propose X-Portrait, an innovative conditional diffusion model tailored for generating expressive and temporally coherent portrait animation. Specifically, given a single portrait as appearance reference, we aim to animate it with motion derived from a driving video, capturing both highly dynamic and subtle facial expressions along with wide-range head movements. As its core, we leverage the generative prior of a pre-trained diffusion model as the rendering backbone, while achieve fine-grained head pose and expression control with novel controlling signals within the framework of ControlNet. In contrast to conventional coarse explicit controls such as facial landmarks, our motion control module is learned to interpret the dynamics directly from the original driving RGB inputs. The motion accuracy is further enhanced with a patch-based local control module that effectively enhance the motion attention to small-scale nuances like eyeball positions. Notably, to mitigate the identity leakage from the driving signals, we train our motion control modules with scaling-augmented cross-identity images, ensuring maximized disentanglement from the appearance reference modules. Experimental results demonstrate the universal effectiveness of X-Portrait across a diverse range of facial portraits and expressive driving sequences, and showcase its proficiency in generating captivating portrait animations with consistently maintained identity characteristics.
DiffPortrait3D: Controllable Diffusion for Zero-Shot Portrait View Synthesis
Dec 22, 2023



We present DiffPortrait3D, a conditional diffusion model that is capable of synthesizing 3D-consistent photo-realistic novel views from as few as a single in-the-wild portrait. Specifically, given a single RGB input, we aim to synthesize plausible but consistent facial details rendered from novel camera views with retained both identity and facial expression. In lieu of time-consuming optimization and fine-tuning, our zero-shot method generalizes well to arbitrary face portraits with unposed camera views, extreme facial expressions, and diverse artistic depictions. At its core, we leverage the generative prior of 2D diffusion models pre-trained on large-scale image datasets as our rendering backbone, while the denoising is guided with disentangled attentive control of appearance and camera pose. To achieve this, we first inject the appearance context from the reference image into the self-attention layers of the frozen UNets. The rendering view is then manipulated with a novel conditional control module that interprets the camera pose by watching a condition image of a crossed subject from the same view. Furthermore, we insert a trainable cross-view attention module to enhance view consistency, which is further strengthened with a novel 3D-aware noise generation process during inference. We demonstrate state-of-the-art results both qualitatively and quantitatively on our challenging in-the-wild and multi-view benchmarks.
ImageDream: Image-Prompt Multi-view Diffusion for 3D Generation
Dec 02, 2023



We introduce "ImageDream," an innovative image-prompt, multi-view diffusion model for 3D object generation. ImageDream stands out for its ability to produce 3D models of higher quality compared to existing state-of-the-art, image-conditioned methods. Our approach utilizes a canonical camera coordination for the objects in images, improving visual geometry accuracy. The model is designed with various levels of control at each block inside the diffusion model based on the input image, where global control shapes the overall object layout and local control fine-tunes the image details. The effectiveness of ImageDream is demonstrated through extensive evaluations using a standard prompt list. For more information, visit our project page at https://Image-Dream.github.io.
MagicDance: Realistic Human Dance Video Generation with Motions & Facial Expressions Transfer
Nov 18, 2023In this work, we propose MagicDance, a diffusion-based model for 2D human motion and facial expression transfer on challenging human dance videos. Specifically, we aim to generate human dance videos of any target identity driven by novel pose sequences while keeping the identity unchanged. To this end, we propose a two-stage training strategy to disentangle human motions and appearance (e.g., facial expressions, skin tone and dressing), consisting of the pretraining of an appearance-control block and fine-tuning of an appearance-pose-joint-control block over human dance poses of the same dataset. Our novel design enables robust appearance control with temporally consistent upper body, facial attributes, and even background. The model also generalizes well on unseen human identities and complex motion sequences without the need for any fine-tuning with additional data with diverse human attributes by leveraging the prior knowledge of image diffusion models. Moreover, the proposed model is easy to use and can be considered as a plug-in module/extension to Stable Diffusion. We also demonstrate the model's ability for zero-shot 2D animation generation, enabling not only the appearance transfer from one identity to another but also allowing for cartoon-like stylization given only pose inputs. Extensive experiments demonstrate our superior performance on the TikTok dataset.
Consistent-1-to-3: Consistent Image to 3D View Synthesis via Geometry-aware Diffusion Models
Oct 04, 2023



Zero-shot novel view synthesis (NVS) from a single image is an essential problem in 3D object understanding. While recent approaches that leverage pre-trained generative models can synthesize high-quality novel views from in-the-wild inputs, they still struggle to maintain 3D consistency across different views. In this paper, we present Consistent-1-to-3, which is a generative framework that significantly mitigate this issue. Specifically, we decompose the NVS task into two stages: (i) transforming observed regions to a novel view, and (ii) hallucinating unseen regions. We design a scene representation transformer and view-conditioned diffusion model for performing these two stages respectively. Inside the models, to enforce 3D consistency, we propose to employ epipolor-guided attention to incorporate geometry constraints, and multi-view attention to better aggregate multi-view information. Finally, we design a hierarchy generation paradigm to generate long sequences of consistent views, allowing a full 360 observation of the provided object image. Qualitative and quantitative evaluation over multiple datasets demonstrate the effectiveness of the proposed mechanisms against state-of-the-art approaches. Our project page is at https://jianglongye.com/consistent123/
MVDream: Multi-view Diffusion for 3D Generation
Aug 31, 2023



We propose MVDream, a multi-view diffusion model that is able to generate geometrically consistent multi-view images from a given text prompt. By leveraging image diffusion models pre-trained on large-scale web datasets and a multi-view dataset rendered from 3D assets, the resulting multi-view diffusion model can achieve both the generalizability of 2D diffusion and the consistency of 3D data. Such a model can thus be applied as a multi-view prior for 3D generation via Score Distillation Sampling, where it greatly improves the stability of existing 2D-lifting methods by solving the 3D consistency problem. Finally, we show that the multi-view diffusion model can also be fine-tuned under a few shot setting for personalized 3D generation, i.e. DreamBooth3D application, where the consistency can be maintained after learning the subject identity.
OmniAvatar: Geometry-Guided Controllable 3D Head Synthesis
Mar 27, 2023We present OmniAvatar, a novel geometry-guided 3D head synthesis model trained from in-the-wild unstructured images that is capable of synthesizing diverse identity-preserved 3D heads with compelling dynamic details under full disentangled control over camera poses, facial expressions, head shapes, articulated neck and jaw poses. To achieve such high level of disentangled control, we first explicitly define a novel semantic signed distance function (SDF) around a head geometry (FLAME) conditioned on the control parameters. This semantic SDF allows us to build a differentiable volumetric correspondence map from the observation space to a disentangled canonical space from all the control parameters. We then leverage the 3D-aware GAN framework (EG3D) to synthesize detailed shape and appearance of 3D full heads in the canonical space, followed by a volume rendering step guided by the volumetric correspondence map to output into the observation space. To ensure the control accuracy on the synthesized head shapes and expressions, we introduce a geometry prior loss to conform to head SDF and a control loss to conform to the expression code. Further, we enhance the temporal realism with dynamic details conditioned upon varying expressions and joint poses. Our model can synthesize more preferable identity-preserved 3D heads with compelling dynamic details compared to the state-of-the-art methods both qualitatively and quantitatively. We also provide an ablation study to justify many of our system design choices.