 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmerging Synergies Between Large Language Models and Machine Learning in Ecommerce Recommendations
Mar 12, 2024



With the boom of e-commerce and web applications, recommender systems have become an important part of our daily lives, providing personalized recommendations based on the user's preferences. Although deep neural networks (DNNs) have made significant progress in improving recommendation systems by simulating the interaction between users and items and incorporating their textual information, these DNN-based approaches still have some limitations, such as the difficulty of effectively understanding users' interests and capturing textual information. It is not possible to generalize to different seen/unseen recommendation scenarios and reason about their predictions. At the same time, the emergence of large language models (LLMs), represented by ChatGPT and GPT-4, has revolutionized the fields of natural language processing (NLP) and artificial intelligence (AI) due to their superior capabilities in the basic tasks of language understanding and generation, and their impressive generalization and reasoning capabilities. As a result, recent research has sought to harness the power of LLM to improve recommendation systems. Given the rapid development of this research direction in the field of recommendation systems, there is an urgent need for a systematic review of existing LLM-driven recommendation systems for researchers and practitioners in related fields to gain insight into. More specifically, we first introduced a representative approach to learning user and item representations using LLM as a feature encoder. We then reviewed the latest advances in LLMs techniques for collaborative filtering enhanced recommendation systems from the three paradigms of pre-training, fine-tuning, and prompting. Finally, we had a comprehensive discussion on the future direction of this emerging field.
LoRA-SP: Streamlined Partial Parameter Adaptation for Resource-Efficient Fine-Tuning of Large Language Models
Feb 28, 2024In addressing the computational and memory demands of fine-tuning Large Language Models(LLMs), we propose LoRA-SP(Streamlined Partial Parameter Adaptation), a novel approach utilizing randomized half-selective parameter freezing within the Low-Rank Adaptation(LoRA)framework. This method efficiently balances pre-trained knowledge retention and adaptability for task-specific optimizations. Through a randomized mechanism, LoRA-SP determines which parameters to update or freeze, significantly reducing computational and memory requirements without compromising model performance. We evaluated LoRA-SP across several benchmark NLP tasks, demonstrating its ability to achieve competitive performance with substantially lower resource consumption compared to traditional full-parameter fine-tuning and other parameter-efficient techniques. LoRA-SP innovative approach not only facilitates the deployment of advanced NLP models in resource-limited settings but also opens new research avenues into effective and efficient model adaptation strategies.
Isolation and Induction: Training Robust Deep Neural Networks against Model Stealing Attacks
Aug 03, 2023Despite the broad application of Machine Learning models as a Service (MLaaS), they are vulnerable to model stealing attacks. These attacks can replicate the model functionality by using the black-box query process without any prior knowledge of the target victim model. Existing stealing defenses add deceptive perturbations to the victim's posterior probabilities to mislead the attackers. However, these defenses are now suffering problems of high inference computational overheads and unfavorable trade-offs between benign accuracy and stealing robustness, which challenges the feasibility of deployed models in practice. To address the problems, this paper proposes Isolation and Induction (InI), a novel and effective training framework for model stealing defenses. Instead of deploying auxiliary defense modules that introduce redundant inference time, InI directly trains a defensive model by isolating the adversary's training gradient from the expected gradient, which can effectively reduce the inference computational cost. In contrast to adding perturbations over model predictions that harm the benign accuracy, we train models to produce uninformative outputs against stealing queries, which can induce the adversary to extract little useful knowledge from victim models with minimal impact on the benign performance. Extensive experiments on several visual classification datasets (e.g., MNIST and CIFAR10) demonstrate the superior robustness (up to 48% reduction on stealing accuracy) and speed (up to 25.4x faster) of our InI over other state-of-the-art methods. Our codes can be found in https://github.com/DIG-Beihang/InI-Model-Stealing-Defense.
Latent Distribution Adjusting for Face Anti-Spoofing
May 16, 2023



With the development of deep learning, the field of face anti-spoofing (FAS) has witnessed great progress. FAS is usually considered a classification problem, where each class is assumed to contain a single cluster optimized by softmax loss. In practical deployment, one class can contain several local clusters, and a single-center is insufficient to capture the inherent structure of the FAS data. However, few approaches consider large distribution discrepancies in the field of FAS. In this work, we propose a unified framework called Latent Distribution Adjusting (LDA) with properties of latent, discriminative, adaptive, generic to improve the robustness of the FAS model by adjusting complex data distribution with multiple prototypes. 1) Latent. LDA attempts to model the data of each class as a Gaussian mixture distribution, and acquire a flexible number of centers for each class in the last fully connected layer implicitly. 2) Discriminative. To enhance the intra-class compactness and inter-class discrepancy, we propose a margin-based loss for providing distribution constrains for prototype learning. 3) Adaptive. To make LDA more efficient and decrease redundant parameters, we propose Adaptive Prototype Selection (APS) by selecting the appropriate number of centers adaptively according to different distributions. 4) Generic. Furthermore, LDA can adapt to unseen distribution by utilizing very few training data without re-training. Extensive experiments demonstrate that our framework can 1) make the final representation space both intra-class compact and inter-class separable, 2) outperform the state-of-the-art methods on multiple standard FAS benchmarks.
Towards Prompt-robust Face Privacy Protection via Adversarial Decoupling Augmentation Framework
May 06, 2023



Denoising diffusion models have shown remarkable potential in various generation tasks. The open-source large-scale text-to-image model, Stable Diffusion, becomes prevalent as it can generate realistic artistic or facial images with personalization through fine-tuning on a limited number of new samples. However, this has raised privacy concerns as adversaries can acquire facial images online and fine-tune text-to-image models for malicious editing, leading to baseless scandals, defamation, and disruption to victims' lives. Prior research efforts have focused on deriving adversarial loss from conventional training processes for facial privacy protection through adversarial perturbations. However, existing algorithms face two issues: 1) they neglect the image-text fusion module, which is the vital module of text-to-image diffusion models, and 2) their defensive performance is unstable against different attacker prompts. In this paper, we propose the Adversarial Decoupling Augmentation Framework (ADAF), addressing these issues by targeting the image-text fusion module to enhance the defensive performance of facial privacy protection algorithms. ADAF introduces multi-level text-related augmentations for defense stability against various attacker prompts. Concretely, considering the vision, text, and common unit space, we propose Vision-Adversarial Loss, Prompt-Robust Augmentation, and Attention-Decoupling Loss. Extensive experiments on CelebA-HQ and VGGFace2 demonstrate ADAF's promising performance, surpassing existing algorithms.
Improving Robust Fairness via Balance Adversarial Training
Sep 15, 2022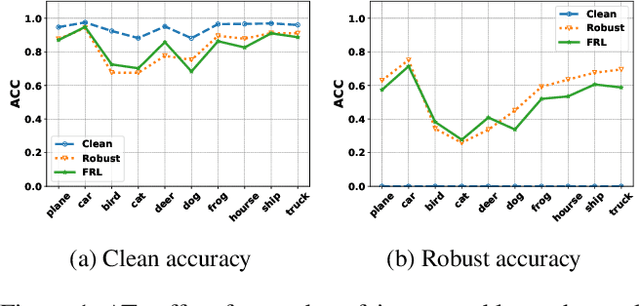
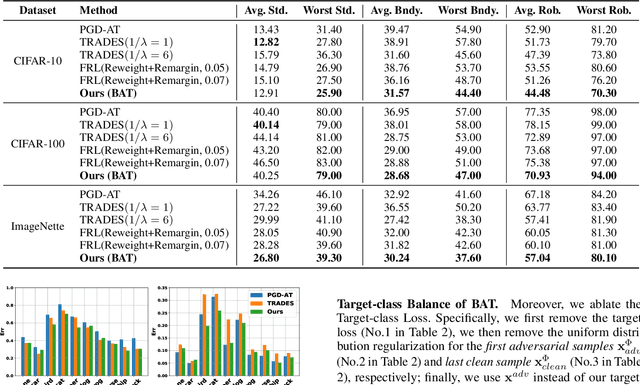
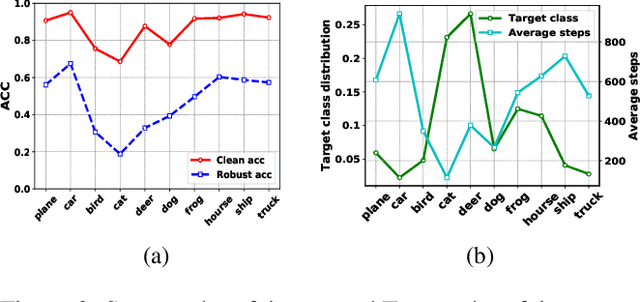

Adversarial training (AT) methods are effective against adversarial attacks, yet they introduce severe disparity of accuracy and robustness between different classes, known as the robust fairness problem. Previously proposed Fair Robust Learning (FRL) adaptively reweights different classes to improve fairness. However, the performance of the better-performed classes decreases, leading to a strong performance drop. In this paper, we observed two unfair phenomena during adversarial training: different difficulties in generating adversarial examples from each class (source-class fairness) and disparate target class tendencies when generating adversarial examples (target-class fairness). From the observations, we propose Balance Adversarial Training (BAT) to address the robust fairness problem. Regarding source-class fairness, we adjust the attack strength and difficulties of each class to generate samples near the decision boundary for easier and fairer model learning; considering target-class fairness, by introducing a uniform distribution constraint, we encourage the adversarial example generation process for each class with a fair tendency. Extensive experiments conducted on multiple datasets (CIFAR-10, CIFAR-100, and ImageNette) demonstrate that our method can significantly outperform other baselines in mitigating the robust fairness problem (+5-10\% on the worst class accuracy)
Adaptive Perturbation Generation for Multiple Backdoors Detection
Sep 13, 2022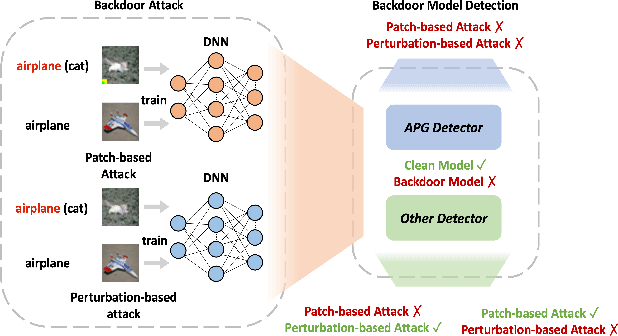
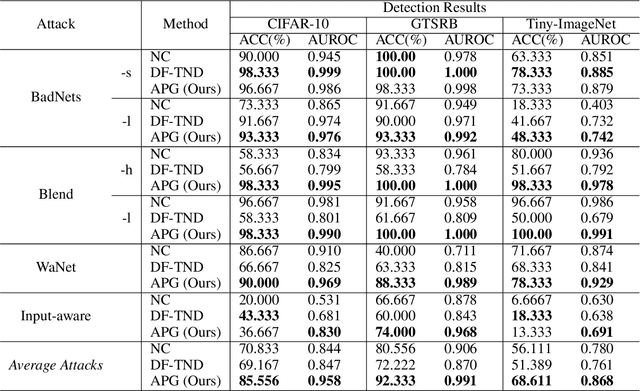
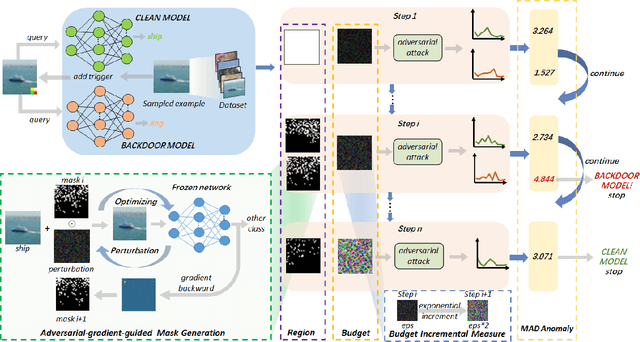
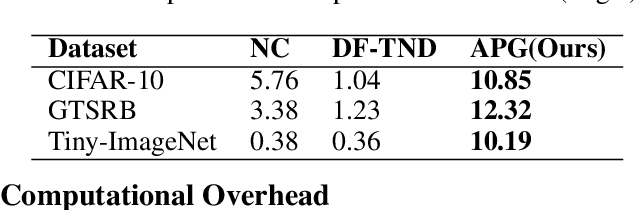
Extensive evidence has demonstrated that deep neural networks (DNNs) are vulnerable to backdoor attacks, which motivates the development of backdoor detection methods. Existing backdoor detection methods are typically tailored for backdoor attacks with individual specific types (e.g., patch-based or perturbation-based). However, adversaries are likely to generate multiple types of backdoor attacks in practice, which challenges the current detection strategies. Based on the fact that adversarial perturbations are highly correlated with trigger patterns, this paper proposes the Adaptive Perturbation Generation (APG) framework to detect multiple types of backdoor attacks by adaptively injecting adversarial perturbations. Since different trigger patterns turn out to show highly diverse behaviors under the same adversarial perturbations, we first design the global-to-local strategy to fit the multiple types of backdoor triggers via adjusting the region and budget of attacks. To further increase the efficiency of perturbation injection, we introduce a gradient-guided mask generation strategy to search for the optimal regions for adversarial attacks. Extensive experiments conducted on multiple datasets (CIFAR-10, GTSRB, Tiny-ImageNet) demonstrate that our method outperforms state-of-the-art baselines by large margins(+12%).
DTG-SSOD: Dense Teacher Guidance for Semi-Supervised Object Detection
Jul 12, 2022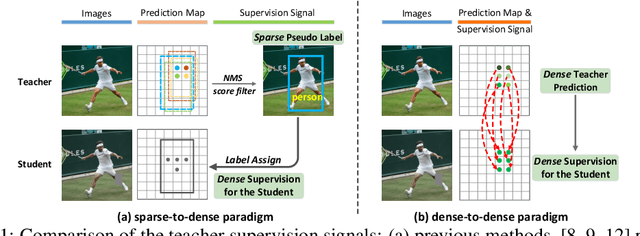
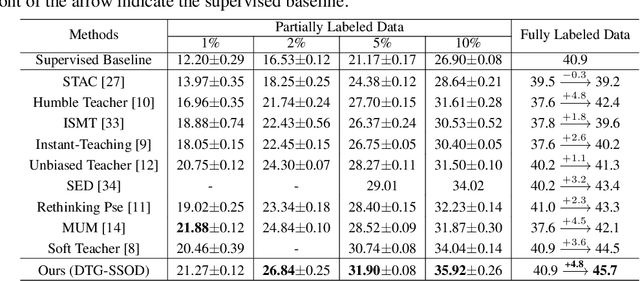
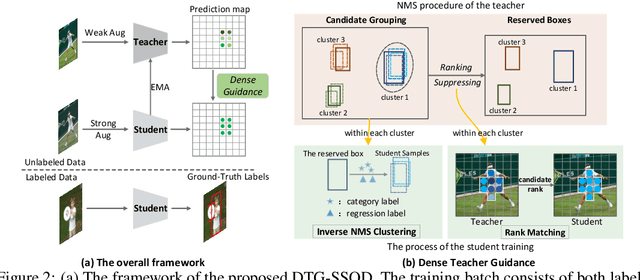
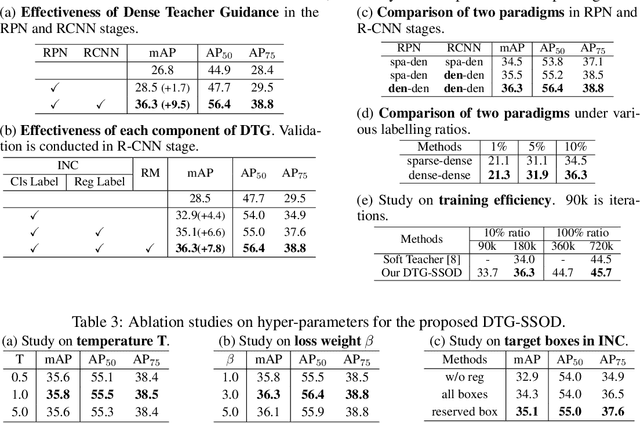
The Mean-Teacher (MT) scheme is widely adopted in semi-supervised object detection (SSOD). In MT, the sparse pseudo labels, offered by the final predictions of the teacher (e.g., after Non Maximum Suppression (NMS) post-processing), are adopted for the dense supervision for the student via hand-crafted label assignment. However, the sparse-to-dense paradigm complicates the pipeline of SSOD, and simultaneously neglects the powerful direct, dense teacher supervision. In this paper, we attempt to directly leverage the dense guidance of teacher to supervise student training, i.e., the dense-to-dense paradigm. Specifically, we propose the Inverse NMS Clustering (INC) and Rank Matching (RM) to instantiate the dense supervision, without the widely used, conventional sparse pseudo labels. INC leads the student to group candidate boxes into clusters in NMS as the teacher does, which is implemented by learning grouping information revealed in NMS procedure of the teacher. After obtaining the same grouping scheme as the teacher via INC, the student further imitates the rank distribution of the teacher over clustered candidates through Rank Matching. With the proposed INC and RM, we integrate Dense Teacher Guidance into Semi-Supervised Object Detection (termed DTG-SSOD), successfully abandoning sparse pseudo labels and enabling more informative learning on unlabeled data. On COCO benchmark, our DTG-SSOD achieves state-of-the-art performance under various labelling ratios. For example, under 10% labelling ratio, DTG-SSOD improves the supervised baseline from 26.9 to 35.9 mAP, outperforming the previous best method Soft Teacher by 1.9 points.
Robust Face Anti-Spoofing with Dual Probabilistic Modeling
Apr 27, 2022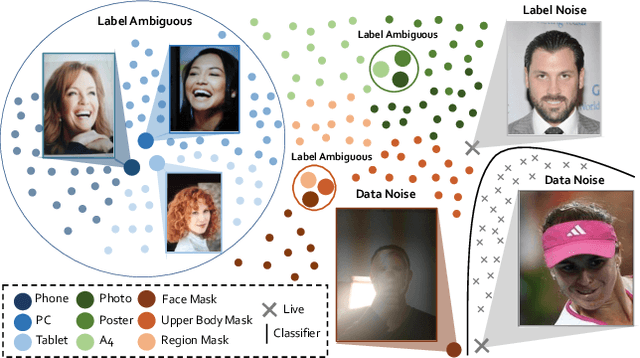
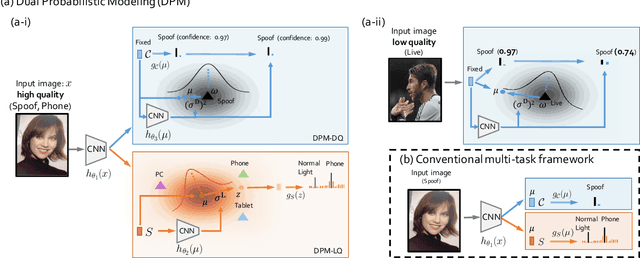
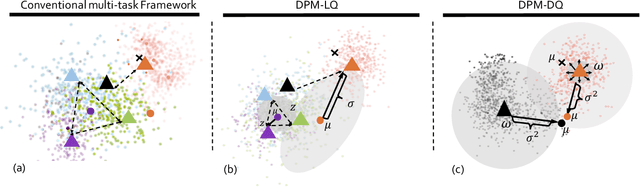

The field of face anti-spoofing (FAS) has witnessed great progress with the surge of deep learning. Due to its data-driven nature, existing FAS methods are sensitive to the noise in the dataset, which will hurdle the learning process. However, very few works consider noise modeling in FAS. In this work, we attempt to fill this gap by automatically addressing the noise problem from both label and data perspectives in a probabilistic manner. Specifically, we propose a unified framework called Dual Probabilistic Modeling (DPM), with two dedicated modules, DPM-LQ (Label Quality aware learning) and DPM-DQ (Data Quality aware learning). Both modules are designed based on the assumption that data and label should form coherent probabilistic distributions. DPM-LQ is able to produce robust feature representations without overfitting to the distribution of noisy semantic labels. DPM-DQ can eliminate data noise from `False Reject' and `False Accept' during inference by correcting the prediction confidence of noisy data based on its quality distribution. Both modules can be incorporated into existing deep networks seamlessly and efficiently. Furthermore, we propose the generalized DPM to address the noise problem in practical usage without the need of semantic annotations. Extensive experiments demonstrate that this probabilistic modeling can 1) significantly improve the accuracy, and 2) make the model robust to the noise in real-world datasets. Without bells and whistles, our proposed DPM achieves state-of-the-art performance on multiple standard FAS benchmarks.
CoupleFace: Relation Matters for Face Recognition Distillation
Apr 12, 2022Knowledge distillation is an effective method to improve the performance of a lightweight neural network (i.e., student model) by transferring the knowledge of a well-performed neural network (i.e., teacher model), which has been widely applied in many computer vision tasks, including face recognition. Nevertheless, the current face recognition distillation methods usually utilize the Feature Consistency Distillation (FCD) (e.g., L2 distance) on the learned embeddings extracted by the teacher and student models for each sample, which is not able to fully transfer the knowledge from the teacher to the student for face recognition. In this work, we observe that mutual relation knowledge between samples is also important to improve the discriminative ability of the learned representation of the student model, and propose an effective face recognition distillation method called CoupleFace by additionally introducing the Mutual Relation Distillation (MRD) into existing distillation framework. Specifically, in MRD, we first propose to mine the informative mutual relations, and then introduce the Relation-Aware Distillation (RAD) loss to transfer the mutual relation knowledge of the teacher model to the student model. Extensive experimental results on multiple benchmark datasets demonstrate the effectiveness of our proposed CoupleFace for face recognition. Moreover, based on our proposed CoupleFace, we have won the first place in the ICCV21 Masked Face Recognition Challenge (MS1M track).