 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbsolute Value Constraint: The Reason for Invalid Performance Evaluation Results of Neural Network Models for Stock Price Prediction
Jan 10, 2021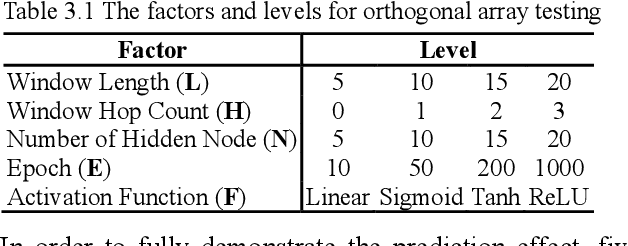
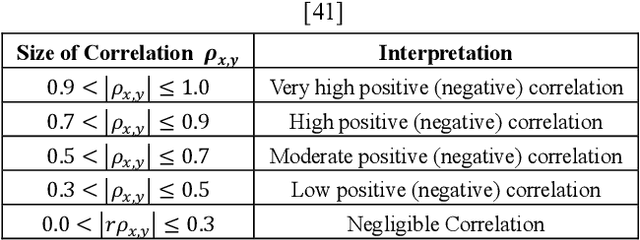
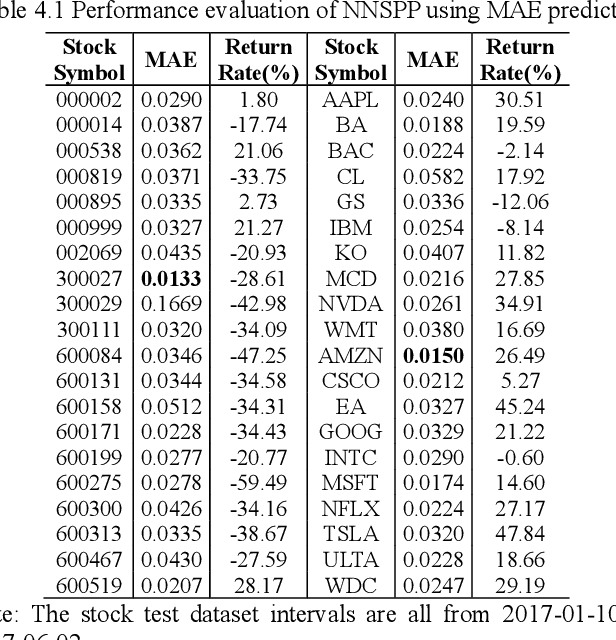
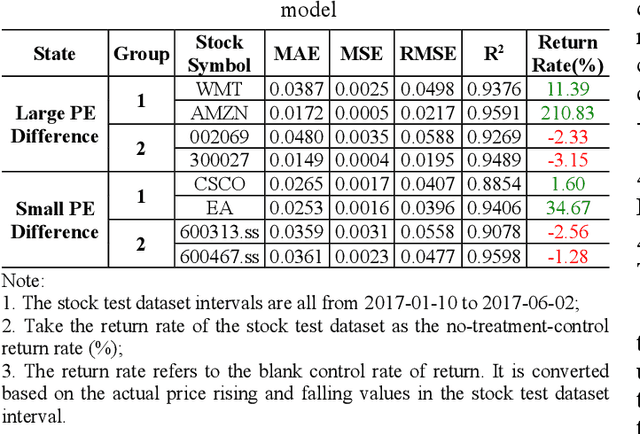
Neural networks for stock price prediction(NNSPP) have been popular for decades. However, most of its study results remain in the research paper and cannot truly play a role in the securities market. One of the main reasons leading to this situation is that the prediction error(PE) based evaluation results have statistical flaws. Its prediction results cannot represent the most critical financial direction attributes. So it cannot provide investors with convincing, interpretable, and consistent model performance evaluation results for practical applications in the securities market. To illustrate, we have used data selected from 20 stock datasets over six years from the Shanghai and Shenzhen stock market in China, and 20 stock datasets from NASDAQ and NYSE in the USA. We implement six shallow and deep neural networks to predict stock prices and use four prediction error measures for evaluation. The results show that the prediction error value only partially reflects the model accuracy of the stock price prediction, and cannot reflect the change in the direction of the model predicted stock price. This characteristic determines that PE is not suitable as an evaluation indicator of NNSPP. Otherwise, it will bring huge potential risks to investors. Therefore, this paper establishes an experiment platform to confirm that the PE method is not suitable for the NNSPP evaluation, and provides a theoretical basis for the necessity of creating a new NNSPP evaluation method in the future.
Channel Estimation for IRS-aided Multiuser Communications with Reduced Error Propagation
Jan 09, 2021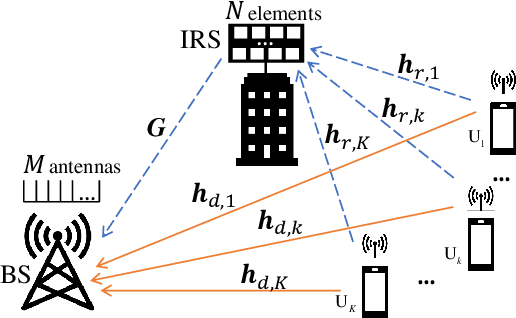

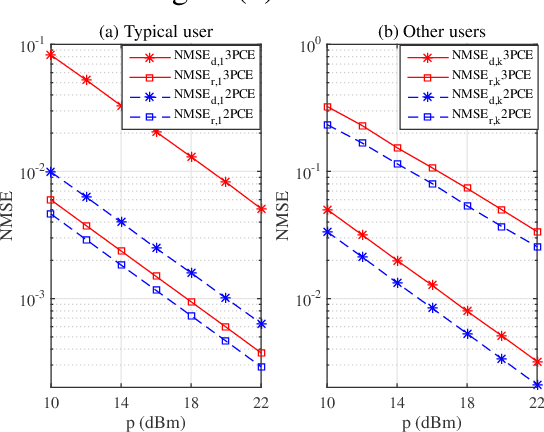
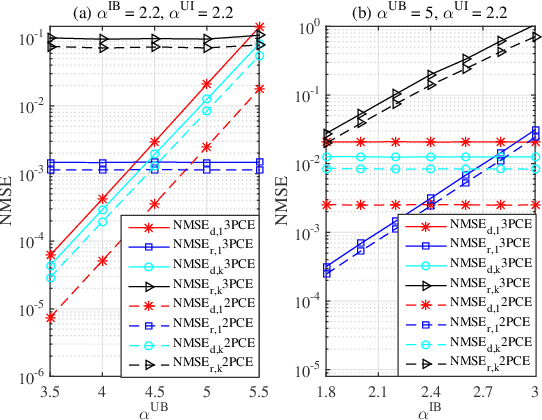
Intelligent reflecting surface (IRS) has emerged as a promising paradigm to improve the capacity and reliability of a wireless communication system by smartly reconfiguring the wireless propagation environment. To achieve the promising gains of IRS, the acquisition of the channel state information (CSI) is essential, which however is practically difficult since the IRS does not employ any transmit/receive radio frequency (RF) chains in general and it has limited signal processing capability. In this paper, we study the uplink channel estimation problem for an IRS-aided multiuser single-input multi-output (SIMO) system, and propose a novel two-phase channel estimation (2PCE) strategy which can alleviate the negative effects caused by error propagation in the existing three-phase channel estimation approach, i.e., the channel estimation errors in previous phases will deteriorate the estimation performance in later phases, and enhance the channel estimation performance with the same amount of channel training overhead as in the existing approach. Moreover, the asymptotic mean squared error (MSE) of the 2PCE strategy is analyzed when the least-square (LS) channel estimation method is employed, and we show that the 2PCE strategy can outperform the existing approach. Finally, extensive simulation results are presented to validate the effectiveness of the 2PCE strategy.
SegGroup: Seg-Level Supervision for 3D Instance and Semantic Segmentation
Dec 18, 2020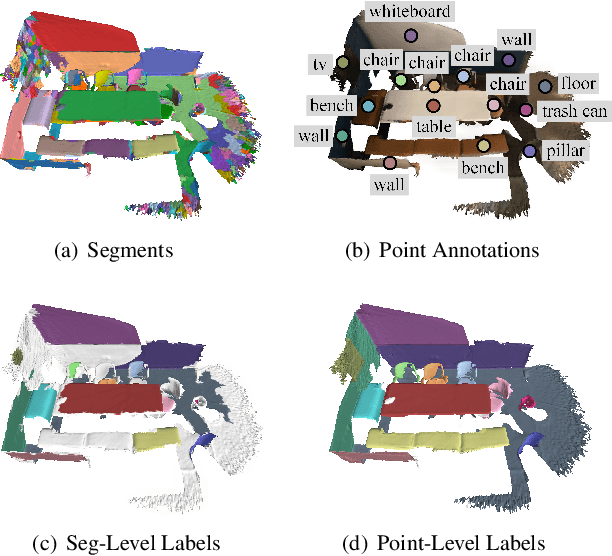

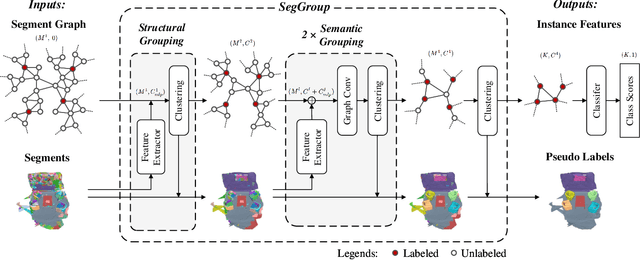
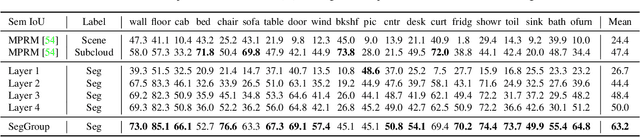
Most existing point cloud instance and semantic segmentation methods heavily rely on strong supervision signals, which require point-level labels for every point in the scene. However, strong supervision suffers from large annotation cost, arousing the need to study efficient annotating. In this paper, we propose a new form of weak supervision signal, namely seg-level labels, for point cloud instance and semantic segmentation. Based on the widely-used over-segmentation as pre-processor, we only annotate one point for each instance to obtain seg-level labels. We further design a segment grouping network (SegGroup) to generate pseudo point-level labels by hierarchically grouping the unlabeled segments into the relevant nearby labeled segments, so that existing methods can directly consume the pseudo labels for training. Experimental results show that our SegGroup achieves comparable results with the fully annotated point-level supervised methods on both point cloud instance and semantic segmentation tasks and outperforms the recent scene-level and subcloud-level supervised methods significantly.
PV-RAFT: Point-Voxel Correlation Fields for Scene Flow Estimation of Point Clouds
Dec 02, 2020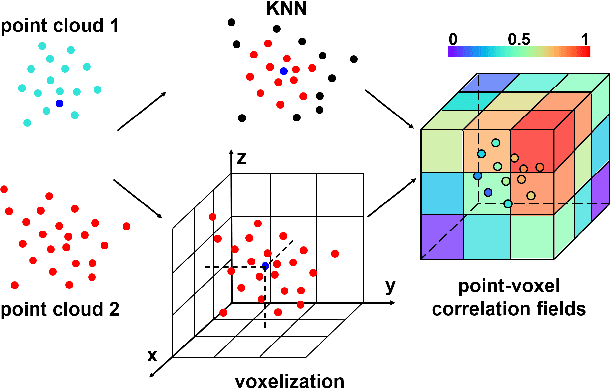
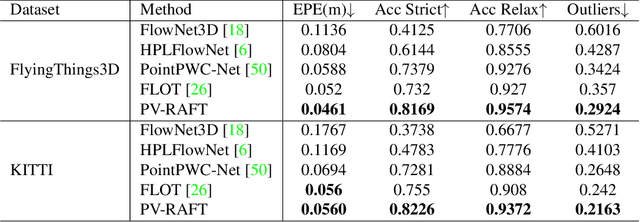
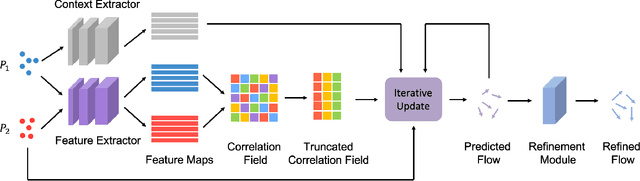

In this paper, we propose Point-Voxel Recurrent All-Pairs Field Transforms (PV-RAFT) to estimate scene flow from point clouds. All-pairs correlations play important roles in scene flow estimation task. However, since point clouds are irregular and unordered, it is challenging to efficiently extract features from all-pairs fields in 3D space. To tackle this problem, we present point-voxel correlation fields, which captures both local and long-range dependencies of point pairs. To capture point-based correlations, we adopt K-Nearest Neighbors search that preserves fine-grained information in the local region. By voxelizing point clouds in a multi-scale manner, a pyramid correlation voxels are constructed to model long-range correspondences. Integrating two types of correlations, our PV-RAFT makes use of all-pairs relations to handle both small and large displacements. We evaluate the proposed method on both synthetic dataset FlyingThings3D and real scenes dataset KITTI. Experimental results show that PV-RAFT surpasses state-of-the-art methods by remarkable margins.
MagGAN: High-Resolution Face Attribute Editing with Mask-Guided Generative Adversarial Network
Oct 03, 2020
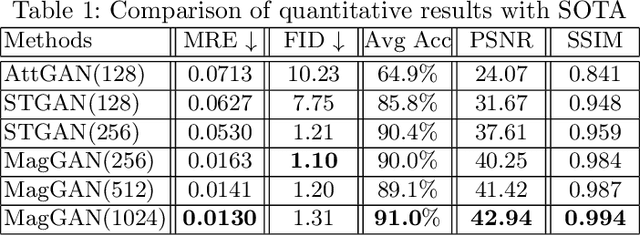

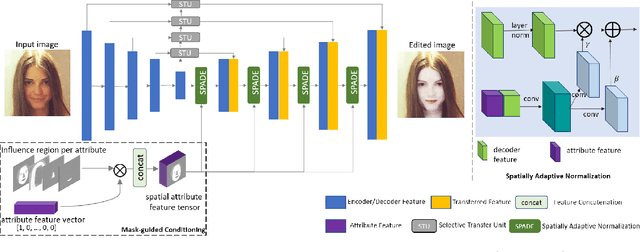
We present Mask-guided Generative Adversarial Network (MagGAN) for high-resolution face attribute editing, in which semantic facial masks from a pre-trained face parser are used to guide the fine-grained image editing process. With the introduction of a mask-guided reconstruction loss, MagGAN learns to only edit the facial parts that are relevant to the desired attribute changes, while preserving the attribute-irrelevant regions (e.g., hat, scarf for modification `To Bald'). Further, a novel mask-guided conditioning strategy is introduced to incorporate the influence region of each attribute change into the generator. In addition, a multi-level patch-wise discriminator structure is proposed to scale our model for high-resolution ($1024 \times 1024$) face editing. Experiments on the CelebA benchmark show that the proposed method significantly outperforms prior state-of-the-art approaches in terms of both image quality and editing performance.
A PDD Decoder for Binary Linear Codes With Neural Check Polytope Projection
Jun 11, 2020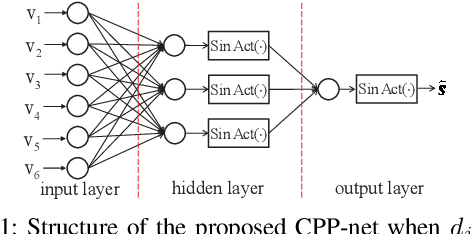
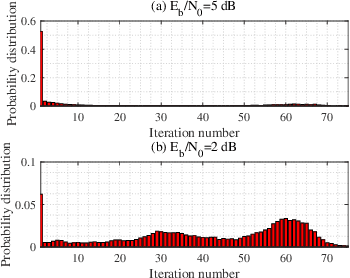
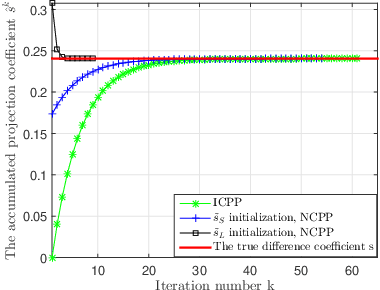
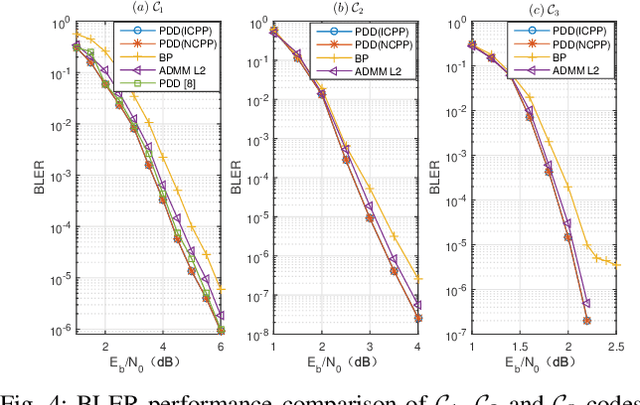
Linear Programming (LP) is an important decoding technique for binary linear codes. However, the advantages of LP decoding, such as low error floor and strong theoretical guarantee, etc., come at the cost of high computational complexity and poor performance at the low signal-to-noise ratio (SNR) region. In this letter, we adopt the penalty dual decomposition (PDD) framework and propose a PDD algorithm to address the fundamental polytope based maximum likelihood (ML) decoding problem. Furthermore, we propose to integrate machine learning techniques into the most time-consuming part of the PDD decoding algorithm, i.e., check polytope projection (CPP). Inspired by the fact that a multi-layer perception (MLP) can theoretically approximate any nonlinear mapping function, we present a specially designed neural CPP (NCPP) algorithm to decrease the decoding latency. Simulation results demonstrate the effectiveness of the proposed algorithms.
FashionBERT: Text and Image Matching with Adaptive Loss for Cross-modal Retrieval
May 29, 2020
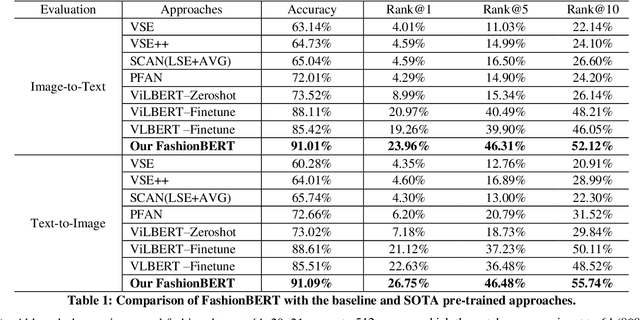
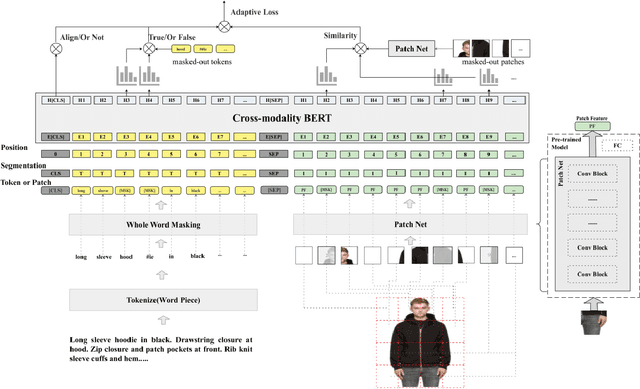
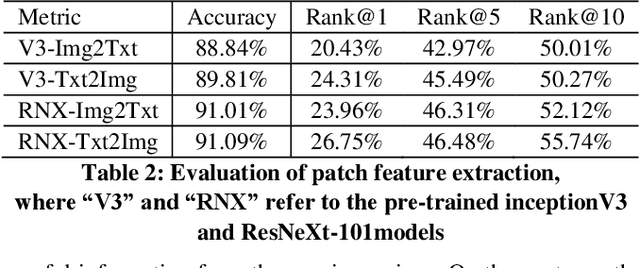
In this paper, we address the text and image matching in cross-modal retrieval of the fashion industry. Different from the matching in the general domain, the fashion matching is required to pay much more attention to the fine-grained information in the fashion images and texts. Pioneer approaches detect the region of interests (i.e., RoIs) from images and use the RoI embeddings as image representations. In general, RoIs tend to represent the "object-level" information in the fashion images, while fashion texts are prone to describe more detailed information, e.g. styles, attributes. RoIs are thus not fine-grained enough for fashion text and image matching. To this end, we propose FashionBERT, which leverages patches as image features. With the pre-trained BERT model as the backbone network, FashionBERT learns high level representations of texts and images. Meanwhile, we propose an adaptive loss to trade off multitask learning in the FashionBERT modeling. Two tasks (i.e., text and image matching and cross-modal retrieval) are incorporated to evaluate FashionBERT. On the public dataset, experiments demonstrate FashionBERT achieves significant improvements in performances than the baseline and state-of-the-art approaches. In practice, FashionBERT is applied in a concrete cross-modal retrieval application. We provide the detailed matching performance and inference efficiency analysis.
Deep Hierarchical Classification for Category Prediction in E-commerce System
May 14, 2020
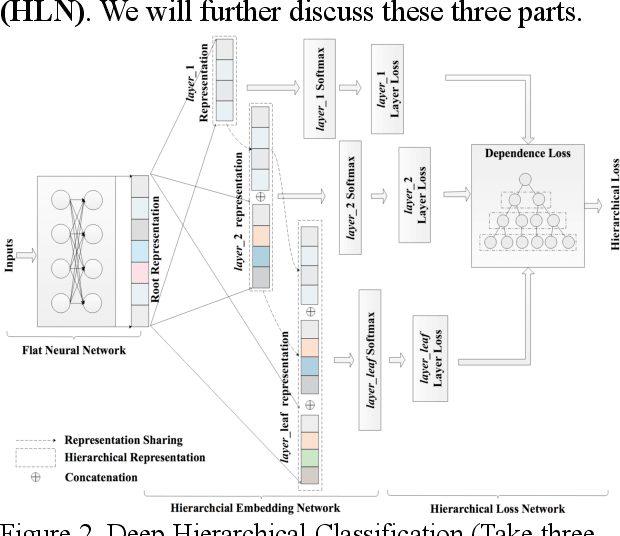
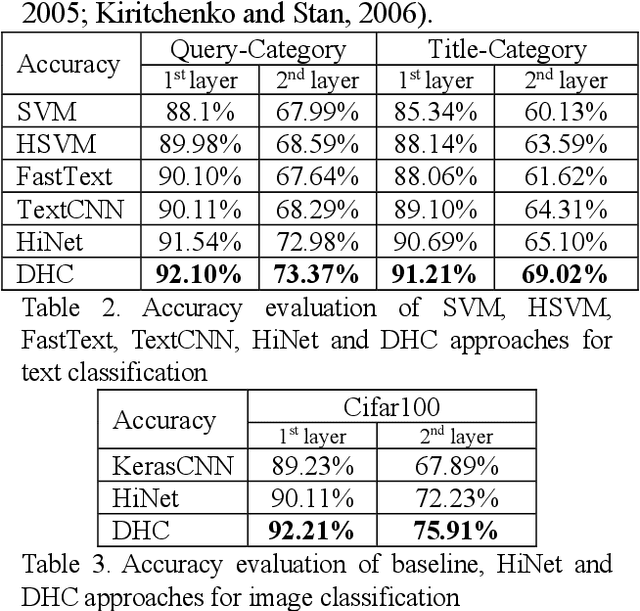
In e-commerce system, category prediction is to automatically predict categories of given texts. Different from traditional classification where there are no relations between classes, category prediction is reckoned as a standard hierarchical classification problem since categories are usually organized as a hierarchical tree. In this paper, we address hierarchical category prediction. We propose a Deep Hierarchical Classification framework, which incorporates the multi-scale hierarchical information in neural networks and introduces a representation sharing strategy according to the category tree. We also define a novel combined loss function to punish hierarchical prediction losses. The evaluation shows that the proposed approach outperforms existing approaches in accuracy.
Modeling Dynamic Heterogeneous Network for Link Prediction using Hierarchical Attention with Temporal RNN
Apr 01, 2020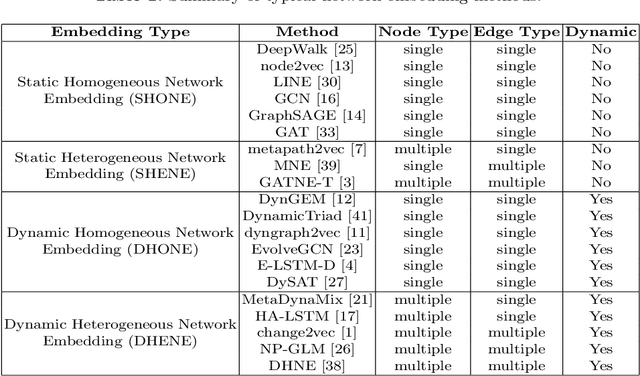
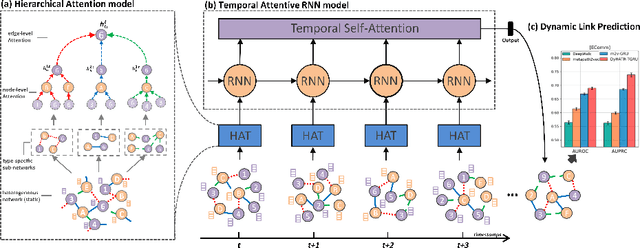
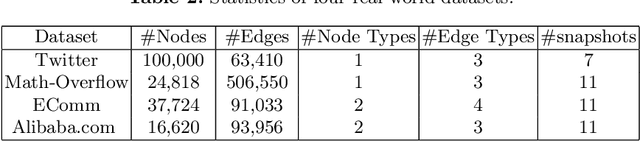
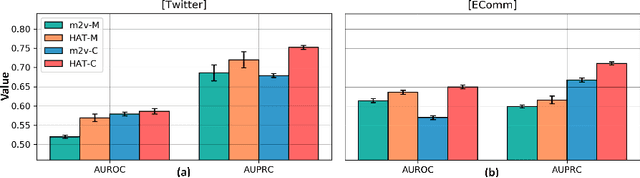
Network embedding aims to learn low-dimensional representations of nodes while capturing structure information of networks. It has achieved great success on many tasks of network analysis such as link prediction and node classification. Most of existing network embedding algorithms focus on how to learn static homogeneous networks effectively. However, networks in the real world are more complex, e.g., networks may consist of several types of nodes and edges (called heterogeneous information) and may vary over time in terms of dynamic nodes and edges (called evolutionary patterns). Limited work has been done for network embedding of dynamic heterogeneous networks as it is challenging to learn both evolutionary and heterogeneous information simultaneously. In this paper, we propose a novel dynamic heterogeneous network embedding method, termed as DyHATR, which uses hierarchical attention to learn heterogeneous information and incorporates recurrent neural networks with temporal attention to capture evolutionary patterns. We benchmark our method on four real-world datasets for the task of link prediction. Experimental results show that DyHATR significantly outperforms several state-of-the-art baselines.
ADMM-based Decoder for Binary Linear Codes Aided by Deep Learning
Feb 14, 2020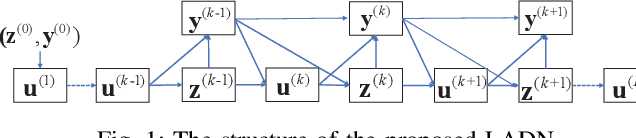
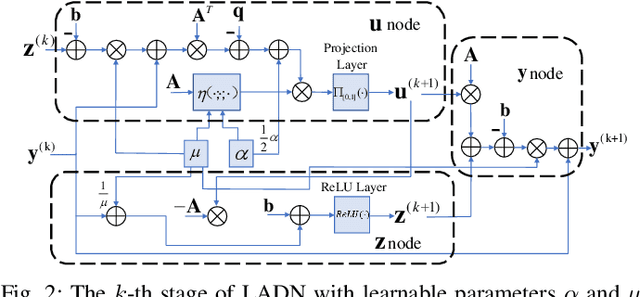
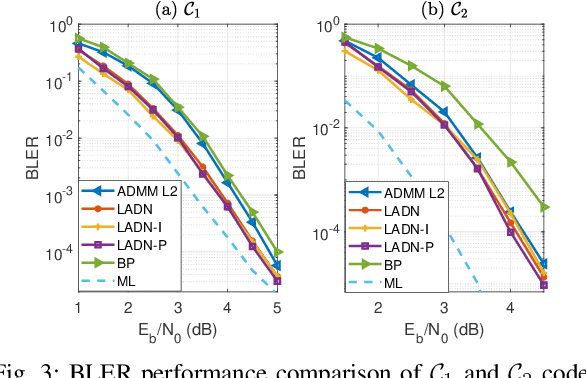
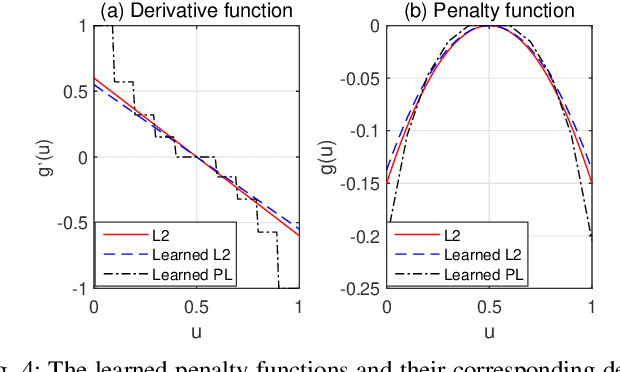
Inspired by the recent advances in deep learning (DL), this work presents a deep neural network aided decoding algorithm for binary linear codes. Based on the concept of deep unfolding, we design a decoding network by unfolding the alternating direction method of multipliers (ADMM)-penalized decoder. In addition, we propose two improved versions of the proposed network. The first one transforms the penalty parameter into a set of iteration-dependent ones, and the second one adopts a specially designed penalty function, which is based on a piecewise linear function with adjustable slopes. Numerical results show that the resulting DL-aided decoders outperform the original ADMM-penalized decoder for various low density parity check (LDPC) codes with similar computational complexity.