 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEyeBench: A Call for More Rigorous Evaluation of Retinal Image Enhancement
Feb 20, 2025



Over the past decade, generative models have achieved significant success in enhancement fundus images.However, the evaluation of these models still presents a considerable challenge. A comprehensive evaluation benchmark for fundus image enhancement is indispensable for three main reasons: 1) The existing denoising metrics (e.g., PSNR, SSIM) are hardly to extend to downstream real-world clinical research (e.g., Vessel morphology consistency). 2) There is a lack of comprehensive evaluation for both paired and unpaired enhancement methods, along with the need for expert protocols to accurately assess clinical value. 3) An ideal evaluation system should provide insights to inform future developments of fundus image enhancement. To this end, we propose a novel comprehensive benchmark, EyeBench, to provide insights that align enhancement models with clinical needs, offering a foundation for future work to improve the clinical relevance and applicability of generative models for fundus image enhancement. EyeBench has three appealing properties: 1) multi-dimensional clinical alignment downstream evaluation: In addition to evaluating the enhancement task, we provide several clinically significant downstream tasks for fundus images, including vessel segmentation, DR grading, denoising generalization, and lesion segmentation. 2) Medical expert-guided evaluation design: We introduce a novel dataset that promote comprehensive and fair comparisons between paired and unpaired methods and includes a manual evaluation protocol by medical experts. 3) Valuable insights: Our benchmark study provides a comprehensive and rigorous evaluation of existing methods across different downstream tasks, assisting medical experts in making informed choices. Additionally, we offer further analysis of the challenges faced by existing methods. The code is available at \url{https://github.com/Retinal-Research/EyeBench}
Audio-Language Models for Audio-Centric Tasks: A survey
Jan 25, 2025



Audio-Language Models (ALMs), which are trained on audio-text data, focus on the processing, understanding, and reasoning of sounds. Unlike traditional supervised learning approaches learning from predefined labels, ALMs utilize natural language as a supervision signal, which is more suitable for describing complex real-world audio recordings. ALMs demonstrate strong zero-shot capabilities and can be flexibly adapted to diverse downstream tasks. These strengths not only enhance the accuracy and generalization of audio processing tasks but also promote the development of models that more closely resemble human auditory perception and comprehension. Recent advances in ALMs have positioned them at the forefront of computer audition research, inspiring a surge of efforts to advance ALM technologies. Despite rapid progress in the field of ALMs, there is still a notable lack of systematic surveys that comprehensively organize and analyze developments. In this paper, we present a comprehensive review of ALMs with a focus on general audio tasks, aiming to fill this gap by providing a structured and holistic overview of ALMs. Specifically, we cover: (1) the background of computer audition and audio-language models; (2) the foundational aspects of ALMs, including prevalent network architectures, training objectives, and evaluation methods; (3) foundational pre-training and audio-language pre-training approaches; (4) task-specific fine-tuning, multi-task tuning and agent systems for downstream applications; (5) datasets and benchmarks; and (6) current challenges and future directions. Our review provides a clear technical roadmap for researchers to understand the development and future trends of existing technologies, offering valuable references for implementation in real-world scenarios.
Plasma-CycleGAN: Plasma Biomarker-Guided MRI to PET Cross-modality Translation Using Conditional CycleGAN
Jan 04, 2025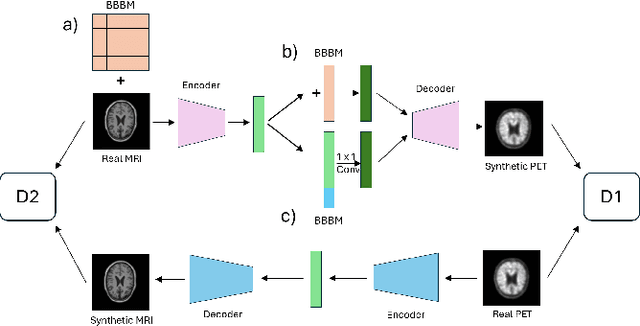
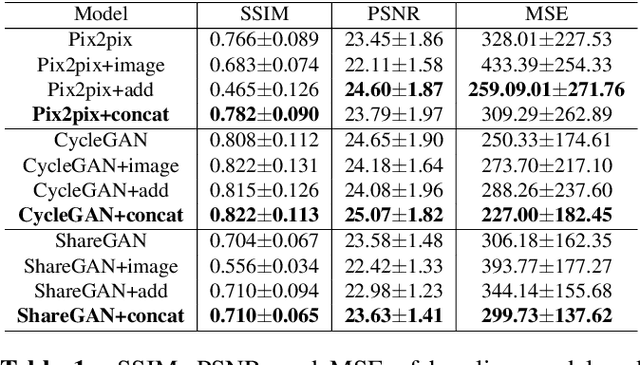
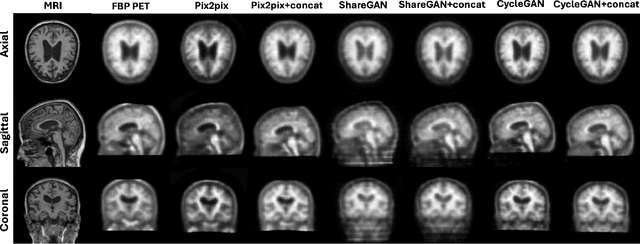
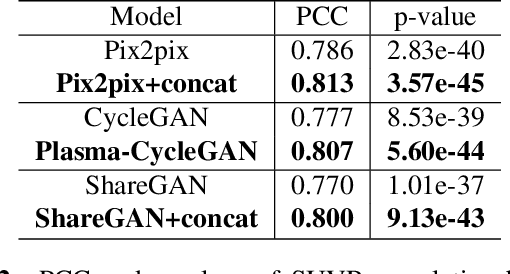
Cross-modality translation between MRI and PET imaging is challenging due to the distinct mechanisms underlying these modalities. Blood-based biomarkers (BBBMs) are revolutionizing Alzheimer's disease (AD) detection by identifying patients and quantifying brain amyloid levels. However, the potential of BBBMs to enhance PET image synthesis remains unexplored. In this paper, we performed a thorough study on the effect of incorporating BBBM into deep generative models. By evaluating three widely used cross-modality translation models, we found that BBBMs integration consistently enhances the generative quality across all models. By visual inspection of the generated results, we observed that PET images generated by CycleGAN exhibit the best visual fidelity. Based on these findings, we propose Plasma-CycleGAN, a novel generative model based on CycleGAN, to synthesize PET images from MRI using BBBMs as conditions. This is the first approach to integrate BBBMs in conditional cross-modality translation between MRI and PET.
Compressed Domain Prior-Guided Video Super-Resolution for Cloud Gaming Content
Jan 03, 2025Cloud gaming is an advanced form of Internet service that necessitates local terminals to decode within limited resources and time latency. Super-Resolution (SR) techniques are often employed on these terminals as an efficient way to reduce the required bit-rate bandwidth for cloud gaming. However, insufficient attention has been paid to SR of compressed game video content. Most SR networks amplify block artifacts and ringing effects in decoded frames while ignoring edge details of game content, leading to unsatisfactory reconstruction results. In this paper, we propose a novel lightweight network called Coding Prior-Guided Super-Resolution (CPGSR) to address the SR challenges in compressed game video content. First, we design a Compressed Domain Guided Block (CDGB) to extract features of different depths from coding priors, which are subsequently integrated with features from the U-net backbone. Then, a series of re-parameterization blocks are utilized for reconstruction. Ultimately, inspired by the quantization in video coding, we propose a partitioned focal frequency loss to effectively guide the model's focus on preserving high-frequency information. Extensive experiments demonstrate the advancement of our approach.
AudioCIL: A Python Toolbox for Audio Class-Incremental Learning with Multiple Scenes
Dec 16, 2024Deep learning, with its robust aotomatic feature extraction capabilities, has demonstrated significant success in audio signal processing. Typically, these methods rely on static, pre-collected large-scale datasets for training, performing well on a fixed number of classes. However, the real world is characterized by constant change, with new audio classes emerging from streaming or temporary availability due to privacy. This dynamic nature of audio environments necessitates models that can incrementally learn new knowledge for new classes without discarding existing information. Introducing incremental learning to the field of audio signal processing, i.e., Audio Class-Incremental Learning (AuCIL), is a meaningful endeavor. We propose such a toolbox named AudioCIL to align audio signal processing algorithms with real-world scenarios and strengthen research in audio class-incremental learning.
Device-Directed Speech Detection for Follow-up Conversations Using Large Language Models
Nov 04, 2024Follow-up conversations with virtual assistants (VAs) enable a user to seamlessly interact with a VA without the need to repeatedly invoke it using a keyword (after the first query). Therefore, accurate Device-directed Speech Detection (DDSD) from the follow-up queries is critical for enabling naturalistic user experience. To this end, we explore the notion of Large Language Models (LLMs) and model the first query when making inference about the follow-ups (based on the ASR-decoded text), via prompting of a pretrained LLM, or by adapting a binary classifier on top of the LLM. In doing so, we also exploit the ASR uncertainty when designing the LLM prompts. We show on the real-world dataset of follow-up conversations that this approach yields large gains (20-40% reduction in false alarms at 10% fixed false rejects) due to the joint modeling of the previous speech context and ASR uncertainty, compared to when follow-ups are modeled alone.
TPOT: Topology Preserving Optimal Transport in Retinal Fundus Image Enhancement
Nov 03, 2024



Retinal fundus photography enhancement is important for diagnosing and monitoring retinal diseases. However, early approaches to retinal image enhancement, such as those based on Generative Adversarial Networks (GANs), often struggle to preserve the complex topological information of blood vessels, resulting in spurious or missing vessel structures. The persistence diagram, which captures topological features based on the persistence of topological structures under different filtrations, provides a promising way to represent the structure information. In this work, we propose a topology-preserving training paradigm that regularizes blood vessel structures by minimizing the differences of persistence diagrams. We call the resulting framework Topology Preserving Optimal Transport (TPOT). Experimental results on a large-scale dataset demonstrate the superiority of the proposed method compared to several state-of-the-art supervised and unsupervised techniques, both in terms of image quality and performance in the downstream blood vessel segmentation task. The code is available at https://github.com/Retinal-Research/TPOT.
EVOLvE: Evaluating and Optimizing LLMs For Exploration
Oct 08, 2024



Despite their success in many domains, large language models (LLMs) remain under-studied in scenarios requiring optimal decision-making under uncertainty. This is crucial as many real-world applications, ranging from personalized recommendations to healthcare interventions, demand that LLMs not only predict but also actively learn to make optimal decisions through exploration. In this work, we measure LLMs' (in)ability to make optimal decisions in bandits, a state-less reinforcement learning setting relevant to many applications. We develop a comprehensive suite of environments, including both context-free and contextual bandits with varying task difficulties, to benchmark LLMs' performance. Motivated by the existence of optimal exploration algorithms, we propose efficient ways to integrate this algorithmic knowledge into LLMs: by providing explicit algorithm-guided support during inference; and through algorithm distillation via in-context demonstrations and fine-tuning, using synthetic data generated from these algorithms. Impressively, these techniques allow us to achieve superior exploration performance with smaller models, surpassing larger models on various tasks. We conducted an extensive ablation study to shed light on various factors, such as task difficulty and data representation, that influence the efficiency of LLM exploration. Additionally, we conduct a rigorous analysis of the LLM's exploration efficiency using the concept of regret, linking its ability to explore to the model size and underlying algorithm.
Supervised Multi-Modal Fission Learning
Sep 30, 2024



Learning from multimodal datasets can leverage complementary information and improve performance in prediction tasks. A commonly used strategy to account for feature correlations in high-dimensional datasets is the latent variable approach. Several latent variable methods have been proposed for multimodal datasets. However, these methods either focus on extracting the shared component across all modalities or on extracting both a shared component and individual components specific to each modality. To address this gap, we propose a Multi-Modal Fission Learning (MMFL) model that simultaneously identifies globally joint, partially joint, and individual components underlying the features of multimodal datasets. Unlike existing latent variable methods, MMFL uses supervision from the response variable to identify predictive latent components and has a natural extension for incorporating incomplete multimodal data. Through simulation studies, we demonstrate that MMFL outperforms various existing multimodal algorithms in both complete and incomplete modality settings. We applied MMFL to a real-world case study for early prediction of Alzheimers Disease using multimodal neuroimaging and genomics data from the Alzheimers Disease Neuroimaging Initiative (ADNI) dataset. MMFL provided more accurate predictions and better insights into within- and across-modality correlations compared to existing methods.
CUNSB-RFIE: Context-aware Unpaired Neural Schrödinger Bridge in Retinal Fundus Image Enhancement
Sep 17, 2024



Retinal fundus photography is significant in diagnosing and monitoring retinal diseases. However, systemic imperfections and operator/patient-related factors can hinder the acquisition of high-quality retinal images. Previous efforts in retinal image enhancement primarily relied on GANs, which are limited by the trade-off between training stability and output diversity. In contrast, the Schr\"odinger Bridge (SB), offers a more stable solution by utilizing Optimal Transport (OT) theory to model a stochastic differential equation (SDE) between two arbitrary distributions. This allows SB to effectively transform low-quality retinal images into their high-quality counterparts. In this work, we leverage the SB framework to propose an image-to-image translation pipeline for retinal image enhancement. Additionally, previous methods often fail to capture fine structural details, such as blood vessels. To address this, we enhance our pipeline by introducing Dynamic Snake Convolution, whose tortuous receptive field can better preserve tubular structures. We name the resulting retinal fundus image enhancement framework the Context-aware Unpaired Neural Schr\"{o}dinger Bridge (CUNSB-RFIE). To the best of our knowledge, this is the first endeavor to use the SB approach for retinal image enhancement. Experimental results on a large-scale dataset demonstrate the advantage of the proposed method compared to several state-of-the-art supervised and unsupervised methods in terms of image quality and performance on downstream tasks.The code is available at https://github.com/Retinal-Research/CUNSB-RFIE .