 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevice-Directed Speech Detection for Follow-up Conversations Using Large Language Models
Nov 04, 2024Follow-up conversations with virtual assistants (VAs) enable a user to seamlessly interact with a VA without the need to repeatedly invoke it using a keyword (after the first query). Therefore, accurate Device-directed Speech Detection (DDSD) from the follow-up queries is critical for enabling naturalistic user experience. To this end, we explore the notion of Large Language Models (LLMs) and model the first query when making inference about the follow-ups (based on the ASR-decoded text), via prompting of a pretrained LLM, or by adapting a binary classifier on top of the LLM. In doing so, we also exploit the ASR uncertainty when designing the LLM prompts. We show on the real-world dataset of follow-up conversations that this approach yields large gains (20-40% reduction in false alarms at 10% fixed false rejects) due to the joint modeling of the previous speech context and ASR uncertainty, compared to when follow-ups are modeled alone.
Comparative Analysis of Personalized Voice Activity Detection Systems: Assessing Real-World Effectiveness
Jun 12, 2024



Voice activity detection (VAD) is a critical component in various applications such as speech recognition, speech enhancement, and hands-free communication systems. With the increasing demand for personalized and context-aware technologies, the need for effective personalized VAD systems has become paramount. In this paper, we present a comparative analysis of Personalized Voice Activity Detection (PVAD) systems to assess their real-world effectiveness. We introduce a comprehensive approach to assess PVAD systems, incorporating various performance metrics such as frame-level and utterance-level error rates, detection latency and accuracy, alongside user-level analysis. Through extensive experimentation and evaluation, we provide a thorough understanding of the strengths and limitations of various PVAD variants. This paper advances the understanding of PVAD technology by offering insights into its efficacy and viability in practical applications using a comprehensive set of metrics.
DeepFN: Towards Generalizable Facial Action Unit Recognition with Deep Face Normalization
Mar 03, 2021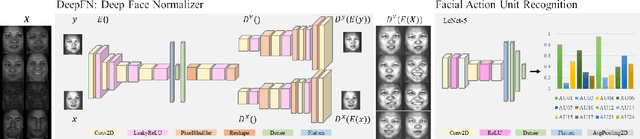
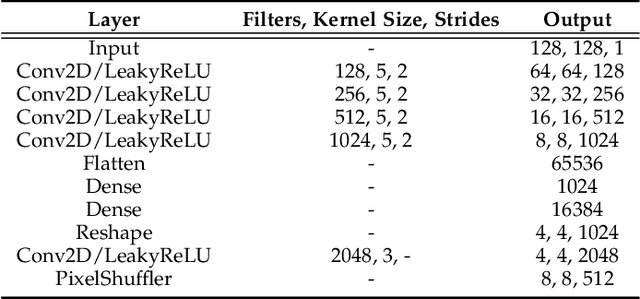
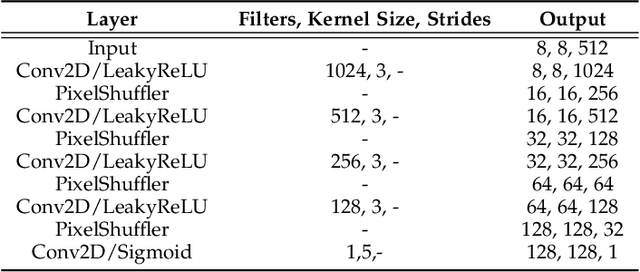
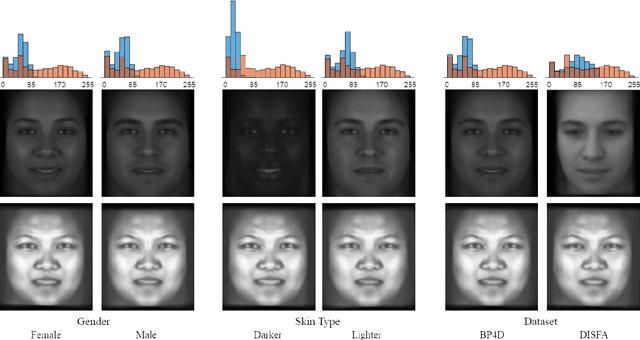
Facial action unit recognition has many applications from market research to psychotherapy and from image captioning to entertainment. Despite its recent progress, deployment of these models has been impeded due to their limited generalization to unseen people and demographics. This work conducts an in-depth analysis of performance across several dimensions: individuals(40 subjects), genders (male and female), skin types (darker and lighter), and databases (BP4D and DISFA). To help suppress the variance in data, we use the notion of self-supervised denoising autoencoders to design a method for deep face normalization(DeepFN) that transfers facial expressions of different people onto a common facial template which is then used to train and evaluate facial action recognition models. We show that person-independent models yield significantly lower performance (55% average F1 and accuracy across 40 subjects) than person-dependent models (60.3%), leading to a generalization gap of 5.3%. However, normalizing the data with the newly introduced DeepFN significantly increased the performance of person-independent models (59.6%), effectively reducing the gap. Similarly, we observed generalization gaps when considering gender (2.4%), skin type (5.3%), and dataset (9.4%), which were significantly reduced with the use of DeepFN. These findings represent an important step towards the creation of more generalizable facial action unit recognition systems.
Fast and Effective Adaptation of Facial Action Unit Detection Deep Model
Sep 26, 2019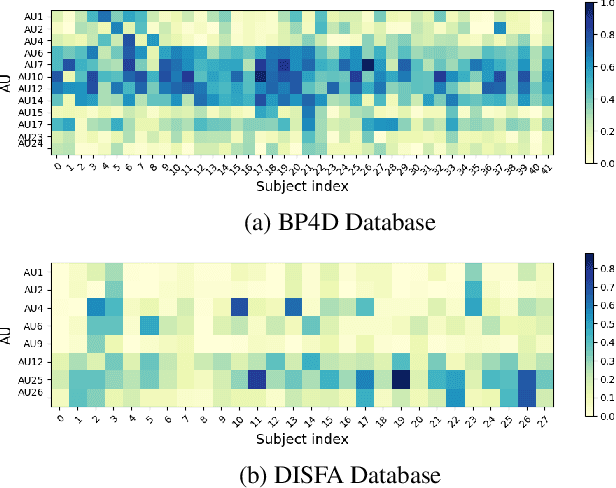
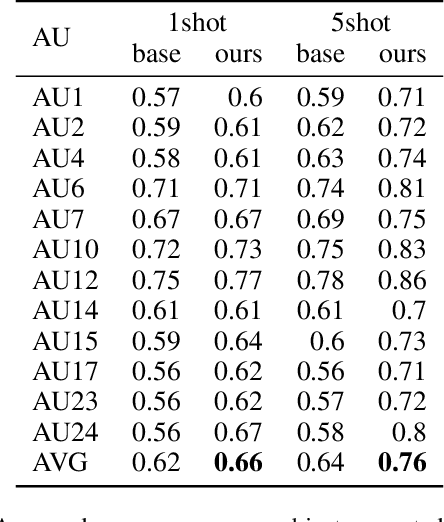
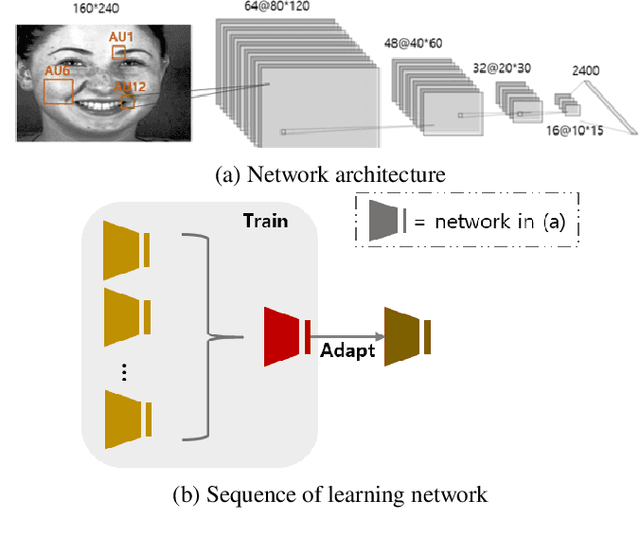
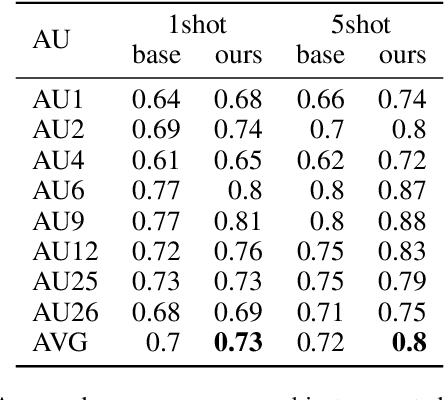
Detecting facial action units (AU) is one of the fundamental steps in automatic recognition of facial expression of emotions and cognitive states. Though there have been a variety of approaches proposed for this task, most of these models are trained only for the specific target AUs, and as such they fail to easily adapt to the task of recognition of new AUs (i.e., those not initially used to train the target models). In this paper, we propose a deep learning approach for facial AU detection that can easily and in a fast manner adapt to a new AU or target subject by leveraging only a few labeled samples from the new task (either an AU or subject). To this end, we propose a modeling approach based on the notion of the model-agnostic meta-learning [C. Finn and Levine, 2017], originally proposed for the general image recognition/detection tasks (e.g., the character recognition from the Omniglot dataset). Specifically, each subject and/or AU is treated as a new learning task and the model learns to adapt based on the knowledge of the previous tasks (the AUs and subjects used to pre-train the target models). Thus, given a new subject or AU, this meta-knowledge (that is shared among training and test tasks) is used to adapt the model to the new task using the notion of deep learning and model-agnostic meta-learning. We show on two benchmark datasets (BP4D and DISFA) for facial AU detection that the proposed approach can be easily adapted to new tasks (AUs/subjects). Using only a few labeled examples from these tasks, the model achieves large improvements over the baselines (i.e., non-adapted models).
DeepFaceLIFT: Interpretable Personalized Models for Automatic Estimation of Self-Reported Pain
Aug 09, 2017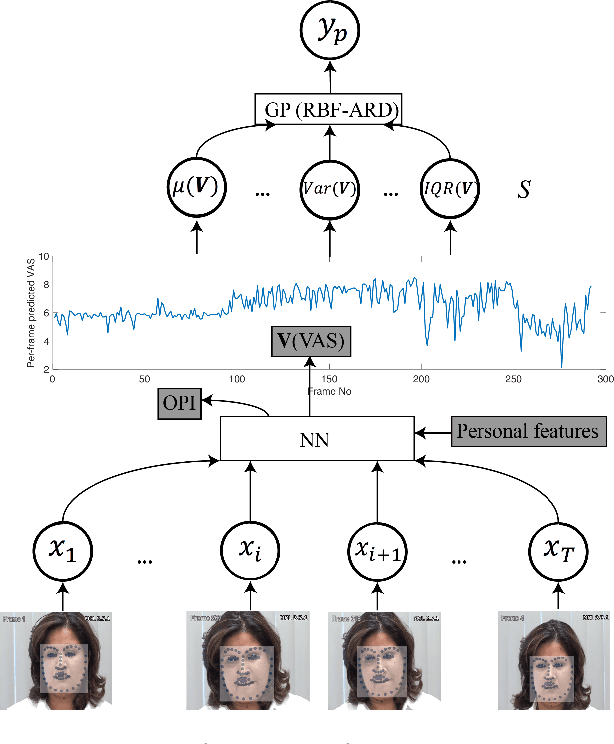
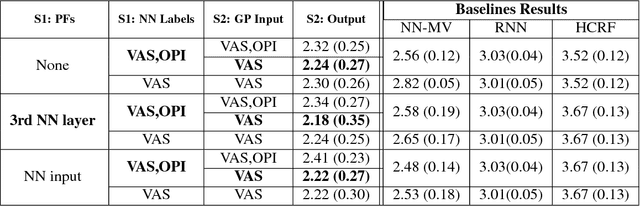
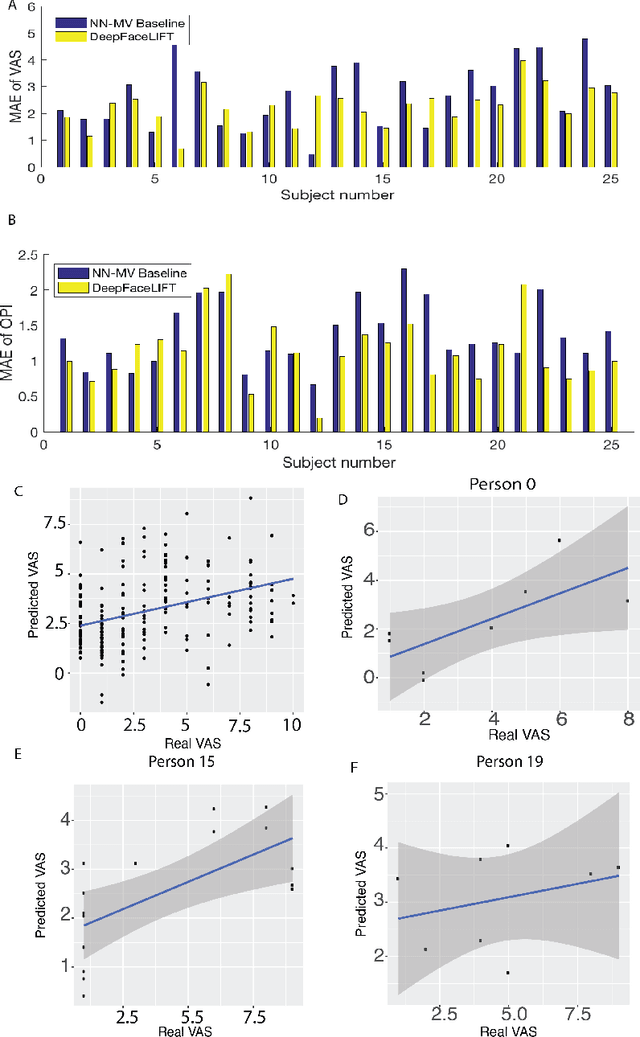
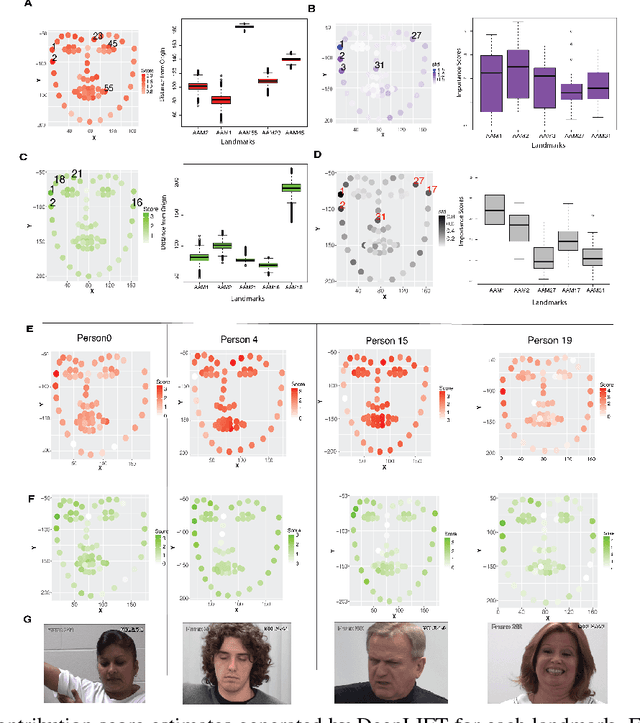
Previous research on automatic pain estimation from facial expressions has focused primarily on "one-size-fits-all" metrics (such as PSPI). In this work, we focus on directly estimating each individual's self-reported visual-analog scale (VAS) pain metric, as this is considered the gold standard for pain measurement. The VAS pain score is highly subjective and context-dependent, and its range can vary significantly among different persons. To tackle these issues, we propose a novel two-stage personalized model, named DeepFaceLIFT, for automatic estimation of VAS. This model is based on (1) Neural Network and (2) Gaussian process regression models, and is used to personalize the estimation of self-reported pain via a set of hand-crafted personal features and multi-task learning. We show on the benchmark dataset for pain analysis (The UNBC-McMaster Shoulder Pain Expression Archive) that the proposed personalized model largely outperforms the traditional, unpersonalized models: the intra-class correlation improves from a baseline performance of 19\% to a personalized performance of 35\% while also providing confidence in the model\textquotesingle s estimates -- in contrast to existing models for the target task. Additionally, DeepFaceLIFT automatically discovers the pain-relevant facial regions for each person, allowing for an easy interpretation of the pain-related facial cues.