 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevice-Directed Speech Detection for Follow-up Conversations Using Large Language Models
Nov 04, 2024Follow-up conversations with virtual assistants (VAs) enable a user to seamlessly interact with a VA without the need to repeatedly invoke it using a keyword (after the first query). Therefore, accurate Device-directed Speech Detection (DDSD) from the follow-up queries is critical for enabling naturalistic user experience. To this end, we explore the notion of Large Language Models (LLMs) and model the first query when making inference about the follow-ups (based on the ASR-decoded text), via prompting of a pretrained LLM, or by adapting a binary classifier on top of the LLM. In doing so, we also exploit the ASR uncertainty when designing the LLM prompts. We show on the real-world dataset of follow-up conversations that this approach yields large gains (20-40% reduction in false alarms at 10% fixed false rejects) due to the joint modeling of the previous speech context and ASR uncertainty, compared to when follow-ups are modeled alone.
Comparative Analysis of Personalized Voice Activity Detection Systems: Assessing Real-World Effectiveness
Jun 12, 2024



Voice activity detection (VAD) is a critical component in various applications such as speech recognition, speech enhancement, and hands-free communication systems. With the increasing demand for personalized and context-aware technologies, the need for effective personalized VAD systems has become paramount. In this paper, we present a comparative analysis of Personalized Voice Activity Detection (PVAD) systems to assess their real-world effectiveness. We introduce a comprehensive approach to assess PVAD systems, incorporating various performance metrics such as frame-level and utterance-level error rates, detection latency and accuracy, alongside user-level analysis. Through extensive experimentation and evaluation, we provide a thorough understanding of the strengths and limitations of various PVAD variants. This paper advances the understanding of PVAD technology by offering insights into its efficacy and viability in practical applications using a comprehensive set of metrics.
Streaming Anchor Loss: Augmenting Supervision with Temporal Significance
Oct 09, 2023Streaming neural network models for fast frame-wise responses to various speech and sensory signals are widely adopted on resource-constrained platforms. Hence, increasing the learning capacity of such streaming models (i.e., by adding more parameters) to improve the predictive power may not be viable for real-world tasks. In this work, we propose a new loss, Streaming Anchor Loss (SAL), to better utilize the given learning capacity by encouraging the model to learn more from essential frames. More specifically, our SAL and its focal variations dynamically modulate the frame-wise cross entropy loss based on the importance of the corresponding frames so that a higher loss penalty is assigned for frames within the temporal proximity of semantically critical events. Therefore, our loss ensures that the model training focuses on predicting the relatively rare but task-relevant frames. Experimental results with standard lightweight convolutional and recurrent streaming networks on three different speech based detection tasks demonstrate that SAL enables the model to learn the overall task more effectively with improved accuracy and latency, without any additional data, model parameters, or architectural changes.
Does Single-channel Speech Enhancement Improve Keyword Spotting Accuracy? A Case Study
Sep 27, 2023



Noise robustness is a key aspect of successful speech applications. Speech enhancement (SE) has been investigated to improve automatic speech recognition accuracy; however, its effectiveness for keyword spotting (KWS) is still under-investigated. In this paper, we conduct a comprehensive study on single-channel speech enhancement for keyword spotting on the Google Speech Command (GSC) dataset. To investigate robustness to noise, the GSC dataset is augmented with noise signals from the WSJ0 Hipster Ambient Mixtures (WHAM!) noise dataset. Our investigation includes not only applying SE before KWS but also performing joint training of the SE frontend and KWS backend models. Moreover, we explore audio injection, a common approach to reduce distortions by using a weighted average of the enhanced and original signals. Audio injection is then further optimized by using another model that predicts the weight for each utterance. Our investigation reveals that SE can improve KWS accuracy on noisy speech when the backend model is trained on clean speech; however, despite our extensive exploration, it is difficult to improve the KWS accuracy with SE when the backend is trained on noisy speech.
Leveraging Large Language Models for Exploiting ASR Uncertainty
Sep 12, 2023



While large language models excel in a variety of natural language processing (NLP) tasks, to perform well on spoken language understanding (SLU) tasks, they must either rely on off-the-shelf automatic speech recognition (ASR) systems for transcription, or be equipped with an in-built speech modality. This work focuses on the former scenario, where LLM's accuracy on SLU tasks is constrained by the accuracy of a fixed ASR system on the spoken input. Specifically, we tackle speech-intent classification task, where a high word-error-rate can limit the LLM's ability to understand the spoken intent. Instead of chasing a high accuracy by designing complex or specialized architectures regardless of deployment costs, we seek to answer how far we can go without substantially changing the underlying ASR and LLM, which can potentially be shared by multiple unrelated tasks. To this end, we propose prompting the LLM with an n-best list of ASR hypotheses instead of only the error-prone 1-best hypothesis. We explore prompt-engineering to explain the concept of n-best lists to the LLM; followed by the finetuning of Low-Rank Adapters on the downstream tasks. Our approach using n-best lists proves to be effective on a device-directed speech detection task as well as on a keyword spotting task, where systems using n-best list prompts outperform those using 1-best ASR hypothesis; thus paving the way for an efficient method to exploit ASR uncertainty via LLMs for speech-based applications.
Device-Directed Speech Detection: Regularization via Distillation for Weakly-Supervised Models
Mar 30, 2022
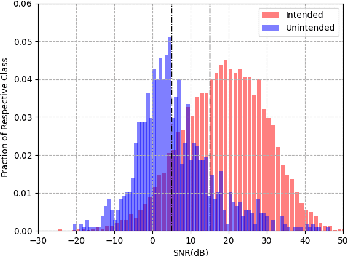
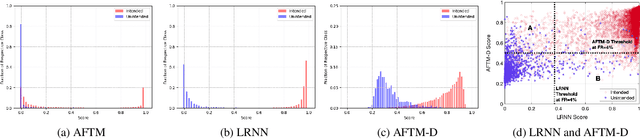
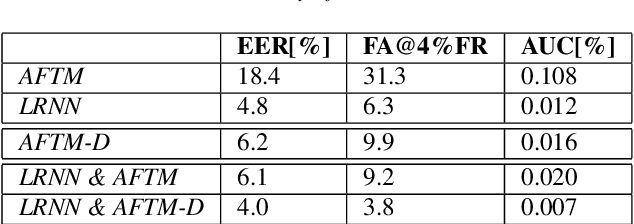
We address the problem of detecting speech directed to a device that does not contain a specific wake-word. Specifically, we focus on audio coming from a touch-based invocation. Mitigating virtual assistants (VAs) activation due to accidental button presses is critical for user experience. While the majority of approaches to false trigger mitigation (FTM) are designed to detect the presence of a target keyword, inferring user intent in absence of keyword is difficult. This also poses a challenge when creating the training/evaluation data for such systems due to inherent ambiguity in the user's data. To this end, we propose a novel FTM approach that uses weakly-labeled training data obtained with a newly introduced data sampling strategy. While this sampling strategy reduces data annotation efforts, the data labels are noisy as the data are not annotated manually. We use these data to train an acoustics-only model for the FTM task by regularizing its loss function via knowledge distillation from an ASR-based (LatticeRNN) model. This improves the model decisions, resulting in 66% gain in accuracy, as measured by equal-error-rate (EER), over the base acoustics-only model. We also show that the ensemble of the LatticeRNN and acoustic-distilled models brings further accuracy improvement of 20%.
Streaming on-device detection of device directed speech from voice and touch-based invocation
Oct 09, 2021
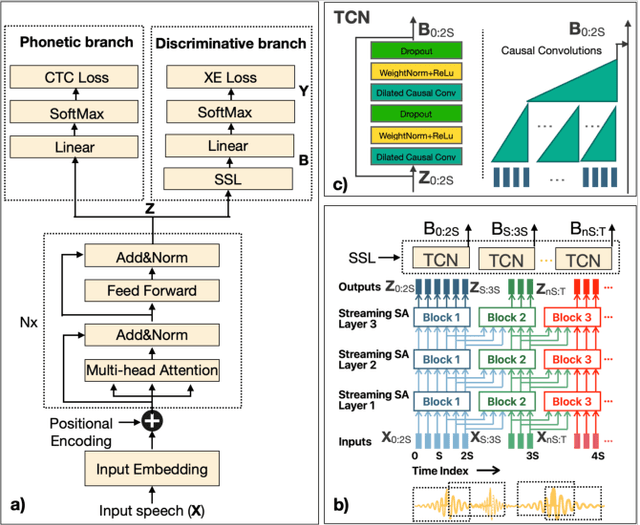
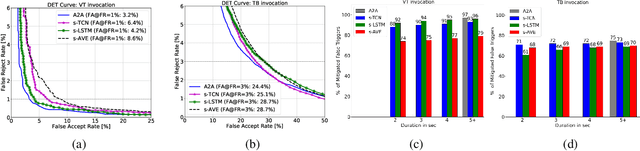
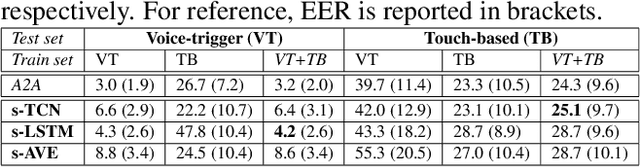
When interacting with smart devices such as mobile phones or wearables, the user typically invokes a virtual assistant (VA) by saying a keyword or by pressing a button on the device. However, in many cases, the VA can accidentally be invoked by the keyword-like speech or accidental button press, which may have implications on user experience and privacy. To this end, we propose an acoustic false-trigger-mitigation (FTM) approach for on-device device-directed speech detection that simultaneously handles the voice-trigger and touch-based invocation. To facilitate the model deployment on-device, we introduce a new streaming decision layer, derived using the notion of temporal convolutional networks (TCN) [1], known for their computational efficiency. To the best of our knowledge, this is the first approach that can detect device-directed speech from more than one invocation type in a streaming fashion. We compare this approach with streaming alternatives based on vanilla Average layer, and canonical LSTMs, and show: (i) that all the models show only a small degradation in accuracy compared with the invocation-specific models, and (ii) that the newly introduced streaming TCN consistently performs better or comparable with the alternatives, while mitigating device undirected speech faster in time, and with (relative) reduction in runtime peak-memory over the LSTM-based approach of 33% vs. 7%, when compared to a non-streaming counterpart.
Streaming Transformer for Hardware Efficient Voice Trigger Detection and False Trigger Mitigation
May 14, 2021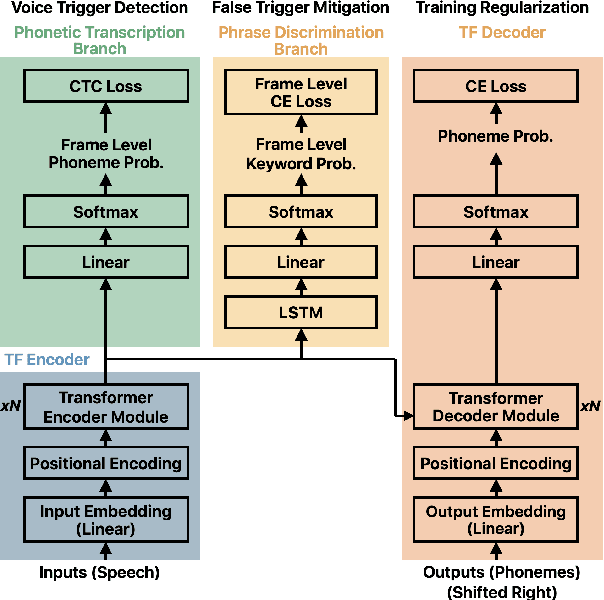
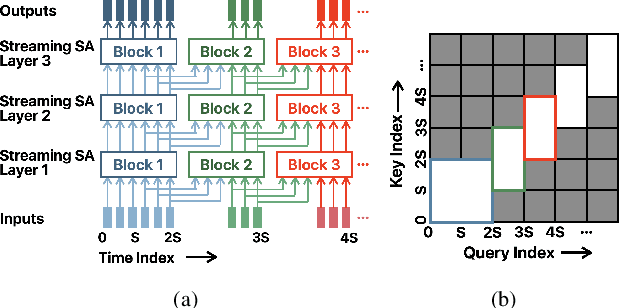

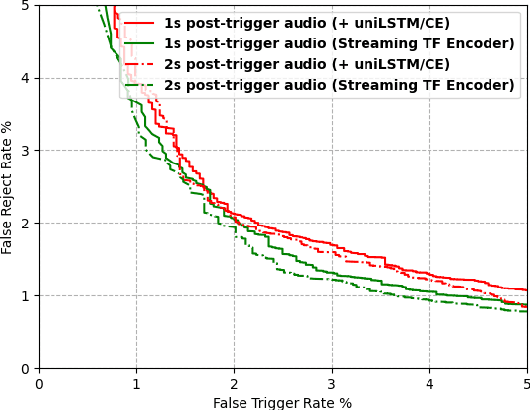
We present a unified and hardware efficient architecture for two stage voice trigger detection (VTD) and false trigger mitigation (FTM) tasks. Two stage VTD systems of voice assistants can get falsely activated to audio segments acoustically similar to the trigger phrase of interest. FTM systems cancel such activations by using post trigger audio context. Traditional FTM systems rely on automatic speech recognition lattices which are computationally expensive to obtain on device. We propose a streaming transformer (TF) encoder architecture, which progressively processes incoming audio chunks and maintains audio context to perform both VTD and FTM tasks using only acoustic features. The proposed joint model yields an average 18% relative reduction in false reject rate (FRR) for the VTD task at a given false alarm rate. Moreover, our model suppresses 95% of the false triggers with an additional one second of post-trigger audio. Finally, on-device measurements show 32% reduction in runtime memory and 56% reduction in inference time compared to non-streaming version of the model.
Progressive Voice Trigger Detection: Accuracy vs Latency
Oct 29, 2020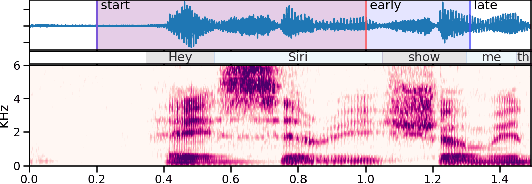
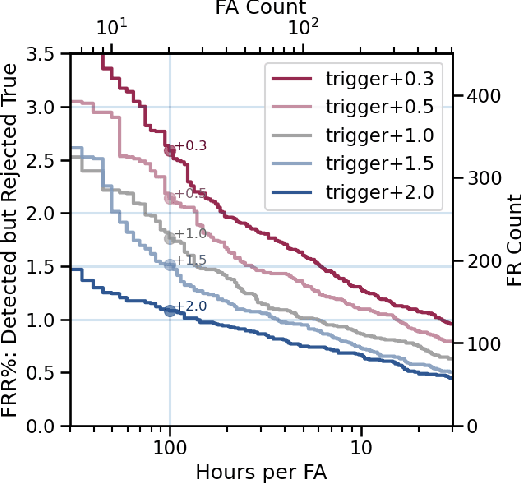
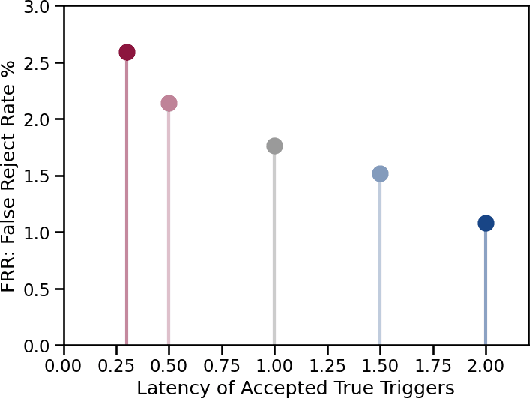
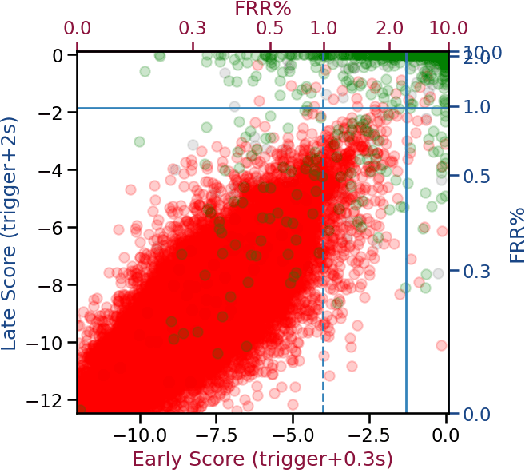
We present an architecture for voice trigger detection for virtual assistants. The main idea in this work is to exploit information in words that immediately follow the trigger phrase. We first demonstrate that by including more audio context after a detected trigger phrase, we can indeed get a more accurate decision. However, waiting to listen to more audio each time incurs a latency increase. Progressive Voice Trigger Detection allows us to trade-off latency and accuracy by accepting clear trigger candidates quickly, but waiting for more context to decide whether to accept more marginal examples. Using a two-stage architecture, we show that by delaying the decision for just 3% of detected true triggers in the test set, we are able to obtain a relative improvement of 66% in false rejection rate, while incurring only a negligible increase in latency.
Hybrid Transformer/CTC Networks for Hardware Efficient Voice Triggering
Aug 05, 2020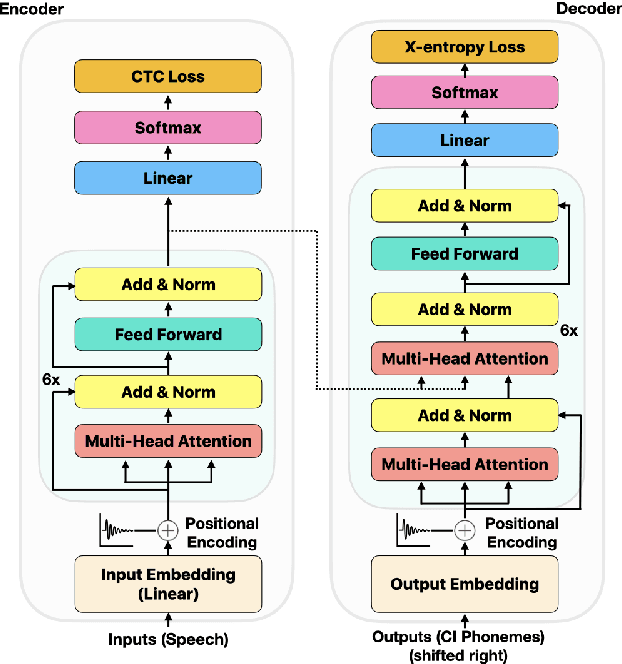
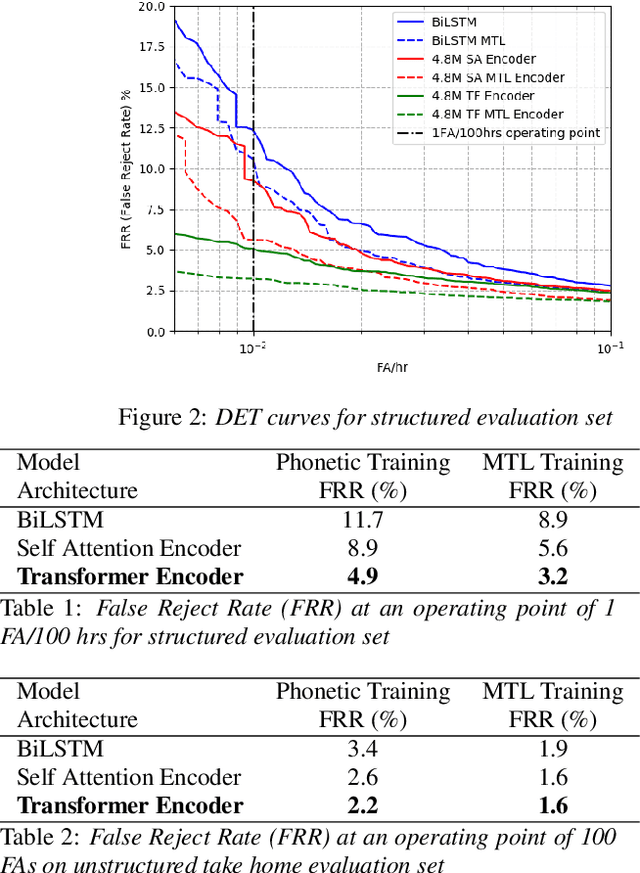
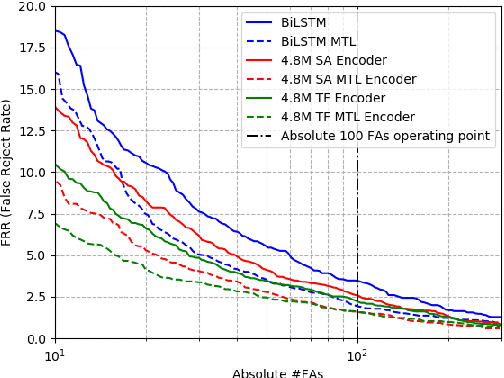
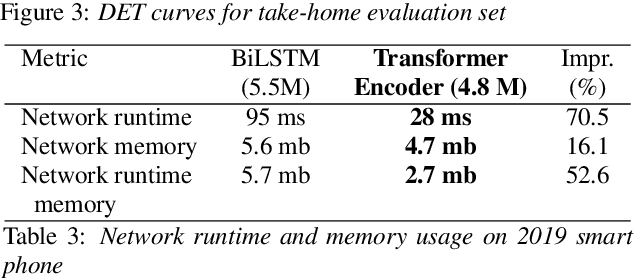
We consider the design of two-pass voice trigger detection systems. We focus on the networks in the second pass that are used to re-score candidate segments obtained from the first-pass. Our baseline is an acoustic model(AM), with BiLSTM layers, trained by minimizing the CTC loss. We replace the BiLSTM layers with self-attention layers. Results on internal evaluation sets show that self-attention networks yield better accuracy while requiring fewer parameters. We add an auto-regressive decoder network on top of the self-attention layers and jointly minimize the CTC loss on the encoder and the cross-entropy loss on the decoder. This design yields further improvements over the baseline. We retrain all the models above in a multi-task learning(MTL) setting, where one branch of a shared network is trained as an AM, while the second branch classifies the whole sequence to be true-trigger or not. Results demonstrate that networks with self-attention layers yield $\sim$60% relative reduction in false reject rates for a given false-alarm rate, while requiring 10% fewer parameters. When trained in the MTL setup, self-attention networks yield further accuracy improvements. On-device measurements show that we observe 70% relative reduction in inference time. Additionally, the proposed network architectures are $\sim$5X faster to train.