 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Level Serialized Output Training for Joint Streaming ASR and ST Leveraging Textual Alignments
Jul 07, 2023



In real-world applications, users often require both translations and transcriptions of speech to enhance their comprehension, particularly in streaming scenarios where incremental generation is necessary. This paper introduces a streaming Transformer-Transducer that jointly generates automatic speech recognition (ASR) and speech translation (ST) outputs using a single decoder. To produce ASR and ST content effectively with minimal latency, we propose a joint token-level serialized output training method that interleaves source and target words by leveraging an off-the-shelf textual aligner. Experiments in monolingual (it-en) and multilingual (\{de,es,it\}-en) settings demonstrate that our approach achieves the best quality-latency balance. With an average ASR latency of 1s and ST latency of 1.3s, our model shows no degradation or even improves output quality compared to separate ASR and ST models, yielding an average improvement of 1.1 WER and 0.4 BLEU in the multilingual case.
VioLA: Unified Codec Language Models for Speech Recognition, Synthesis, and Translation
May 25, 2023



Recent research shows a big convergence in model architecture, training objectives, and inference methods across various tasks for different modalities. In this paper, we propose VioLA, a single auto-regressive Transformer decoder-only network that unifies various cross-modal tasks involving speech and text, such as speech-to-text, text-to-text, text-to-speech, and speech-to-speech tasks, as a conditional codec language model task via multi-task learning framework. To accomplish this, we first convert all the speech utterances to discrete tokens (similar to the textual data) using an offline neural codec encoder. In such a way, all these tasks are converted to token-based sequence conversion problems, which can be naturally handled with one conditional language model. We further integrate task IDs (TID) and language IDs (LID) into the proposed model to enhance the modeling capability of handling different languages and tasks. Experimental results demonstrate that the proposed VioLA model can support both single-modal and cross-modal tasks well, and the decoder-only model achieves a comparable and even better performance than the strong baselines.
Streaming, fast and accurate on-device Inverse Text Normalization for Automatic Speech Recognition
Nov 07, 2022



Automatic Speech Recognition (ASR) systems typically yield output in lexical form. However, humans prefer a written form output. To bridge this gap, ASR systems usually employ Inverse Text Normalization (ITN). In previous works, Weighted Finite State Transducers (WFST) have been employed to do ITN. WFSTs are nicely suited to this task but their size and run-time costs can make deployment on embedded applications challenging. In this paper, we describe the development of an on-device ITN system that is streaming, lightweight & accurate. At the core of our system is a streaming transformer tagger, that tags lexical tokens from ASR. The tag informs which ITN category might be applied, if at all. Following that, we apply an ITN-category-specific WFST, only on the tagged text, to reliably perform the ITN conversion. We show that the proposed ITN solution performs equivalent to strong baselines, while being significantly smaller in size and retaining customization capabilities.
LAMASSU: Streaming Language-Agnostic Multilingual Speech Recognition and Translation Using Neural Transducers
Nov 05, 2022



End-to-end formulation of automatic speech recognition (ASR) and speech translation (ST) makes it easy to use a single model for both multilingual ASR and many-to-many ST. In this paper, we propose streaming language-agnostic multilingual speech recognition and translation using neural transducers (LAMASSU). To enable multilingual text generation in LAMASSU, we conduct a systematic comparison between specified and unified prediction and joint networks. We leverage a language-agnostic multilingual encoder that substantially outperforms shared encoders. To enhance LAMASSU, we propose to feed target LID to encoders. We also apply connectionist temporal classification regularization to transducer training. Experimental results show that LAMASSU not only drastically reduces the model size but also outperforms monolingual ASR and bilingual ST models.
Acoustic-aware Non-autoregressive Spell Correction with Mask Sample Decoding
Oct 16, 2022
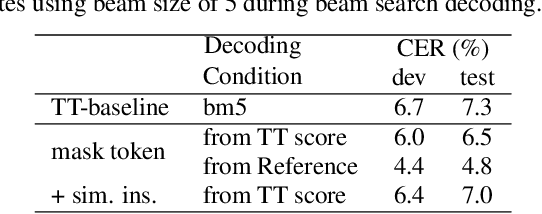

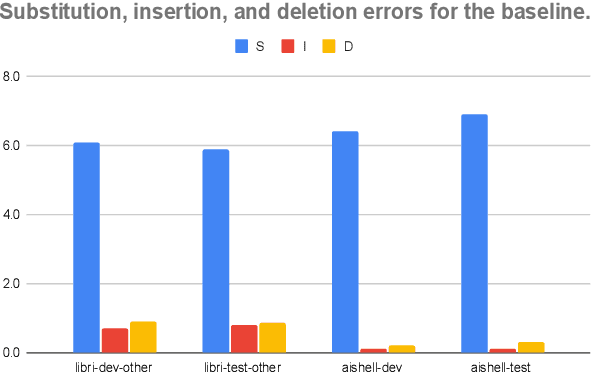
Masked language model (MLM) has been widely used for understanding tasks, e.g. BERT. Recently, MLM has also been used for generation tasks. The most popular one in speech is using Mask-CTC for non-autoregressive speech recognition. In this paper, we take one step further, and explore the possibility of using MLM as a non-autoregressive spell correction (SC) model for transformer-transducer (TT), denoted as MLM-SC. Our initial experiments show that MLM-SC provides no improvements on Librispeech data. The problem might be the choice of modeling units (word pieces) and the inaccuracy of the TT confidence scores for English data. To solve the problem, we propose a mask sample decoding (MS-decode) method where the masked tokens can have the choice of being masked or not to compensate for the inaccuracy. As a result, we reduce the WER of a streaming TT from 7.6% to 6.5% on the Librispeech test-other data and the CER from 7.3% to 6.1% on the Aishell test data, respectively.
CTCBERT: Advancing Hidden-unit BERT with CTC Objectives
Oct 16, 2022
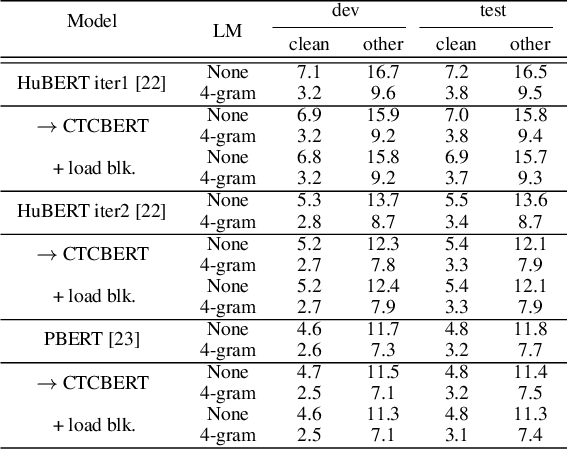
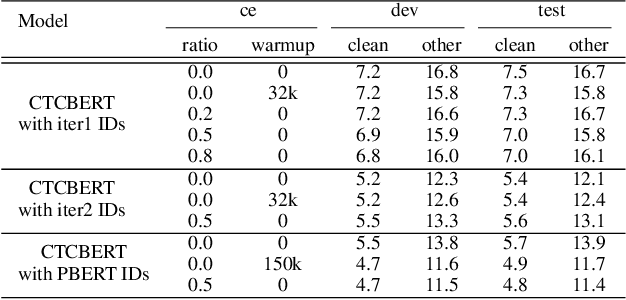
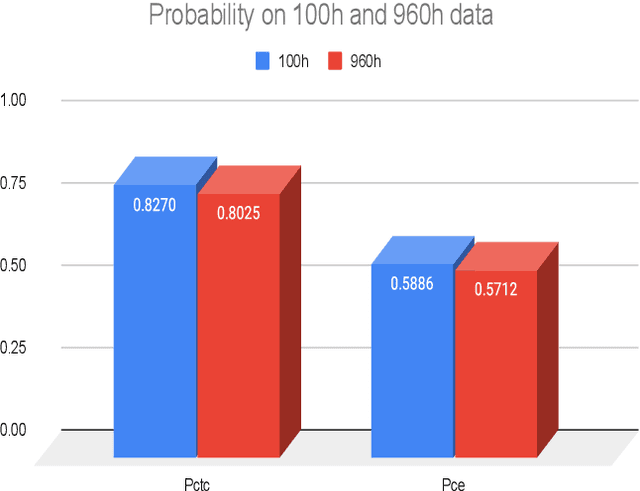
In this work, we present a simple but effective method, CTCBERT, for advancing hidden-unit BERT (HuBERT). HuBERT applies a frame-level cross-entropy (CE) loss, which is similar to most acoustic model training. However, CTCBERT performs the model training with the Connectionist Temporal Classification (CTC) objective after removing duplicated IDs in each masked region. The idea stems from the observation that there can be significant errors in alignments when using clustered or aligned IDs. CTC learns alignments implicitly, indicating that learning with CTC can be more flexible when misalignment exists. We examine CTCBERT on IDs from HuBERT Iter1, HuBERT Iter2, and PBERT. The CTC training brings consistent improvements compared to the CE training. Furthermore, when loading blank-related parameters during finetuning, slight improvements are observed. Evaluated on the Librispeech 960-100h setting, the relative WER improvements of CTCBERT are 2%-11% over HuBERT and PERT on test-other data.
Large-Scale Streaming End-to-End Speech Translation with Neural Transducers
Apr 11, 2022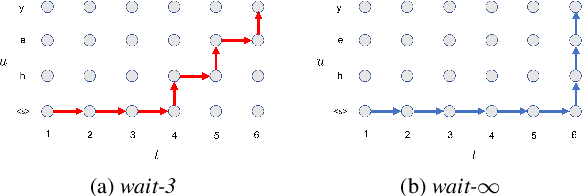
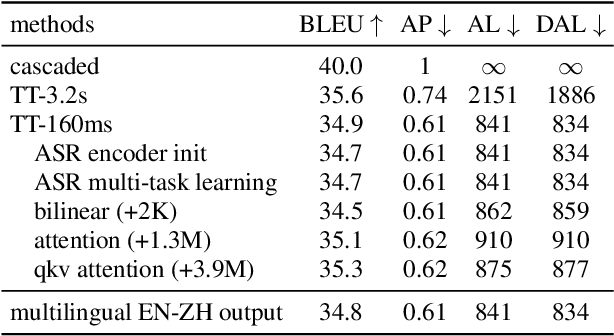
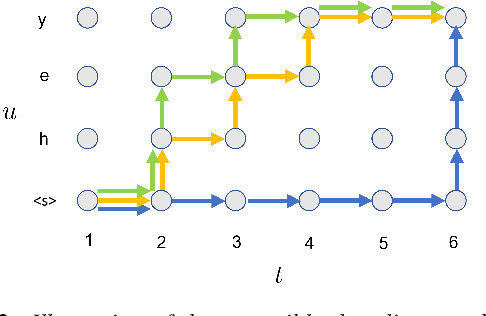
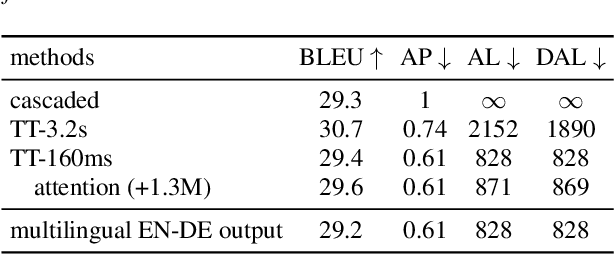
Neural transducers have been widely used in automatic speech recognition (ASR). In this paper, we introduce it to streaming end-to-end speech translation (ST), which aims to convert audio signals to texts in other languages directly. Compared with cascaded ST that performs ASR followed by text-based machine translation (MT), the proposed Transformer transducer (TT)-based ST model drastically reduces inference latency, exploits speech information, and avoids error propagation from ASR to MT. To improve the modeling capacity, we propose attention pooling for the joint network in TT. In addition, we extend TT-based ST to multilingual ST, which generates texts of multiple languages at the same time. Experimental results on a large-scale 50 thousand (K) hours pseudo-labeled training set show that TT-based ST not only significantly reduces inference time but also outperforms non-streaming cascaded ST for English-German translation.
Streaming Speaker-Attributed ASR with Token-Level Speaker Embeddings
Mar 30, 2022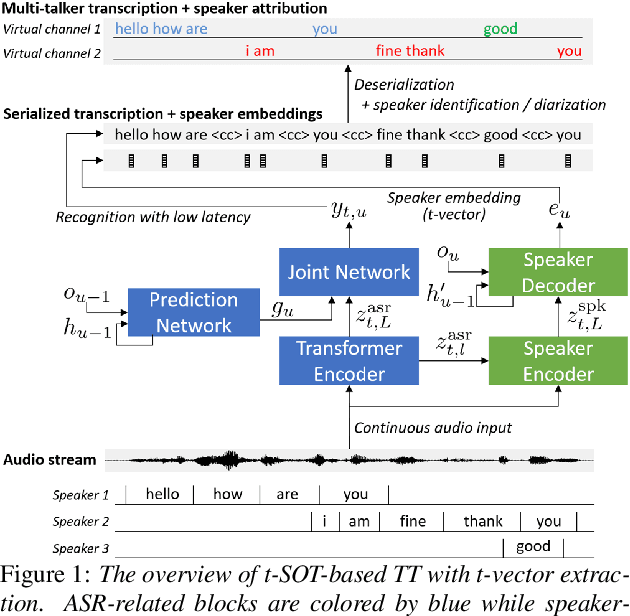
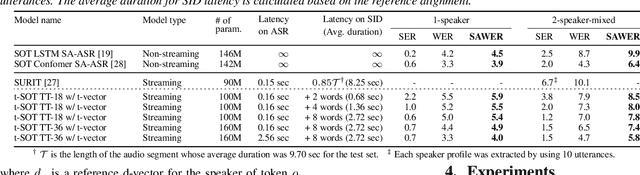
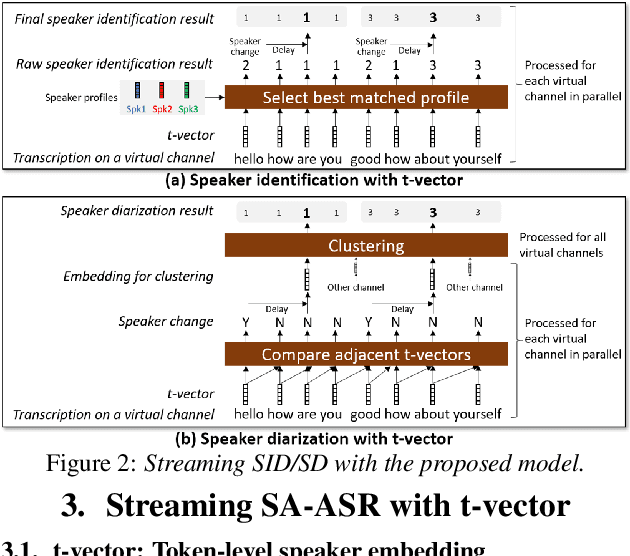
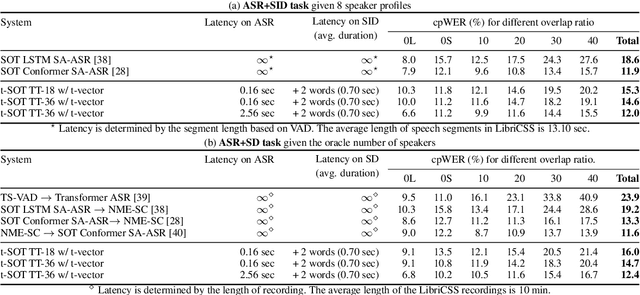
This paper presents a streaming speaker-attributed automatic speech recognition (SA-ASR) model that can recognize "who spoke what" with low latency even when multiple people are speaking simultaneously. Our model is based on token-level serialized output training (t-SOT) which was recently proposed to transcribe multi-talker speech in a streaming fashion. To further recognize speaker identities, we propose an encoder-decoder based speaker embedding extractor that can estimate a speaker representation for each recognized token not only from non-overlapping speech but also from overlapping speech. The proposed speaker embedding, named t-vector, is extracted synchronously with the t-SOT ASR model, enabling joint execution of speaker identification (SID) or speaker diarization (SD) with the multi-talker transcription with low latency. We evaluate the proposed model for a joint task of ASR and SID/SD by using LibriSpeechMix and LibriCSS corpora. The proposed model achieves substantially better accuracy than a prior streaming model and shows comparable or sometimes even superior results to the state-of-the-art offline SA-ASR model.
Streaming Multi-Talker ASR with Token-Level Serialized Output Training
Feb 05, 2022
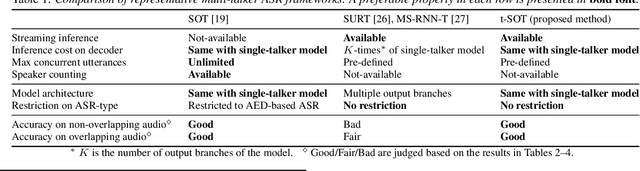
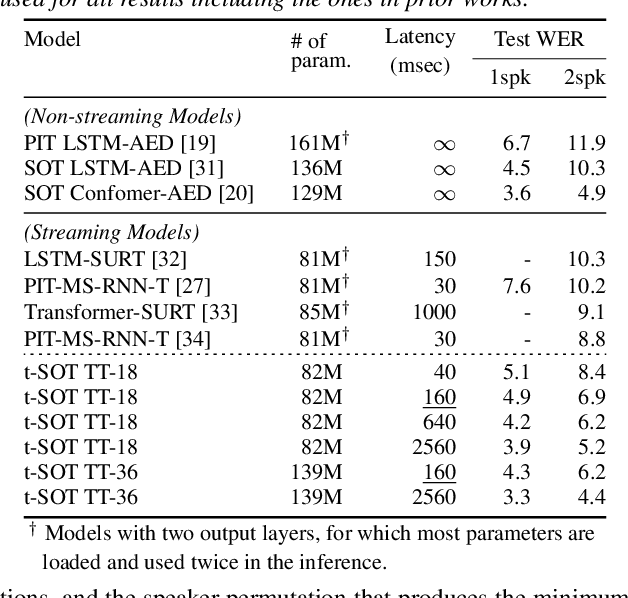
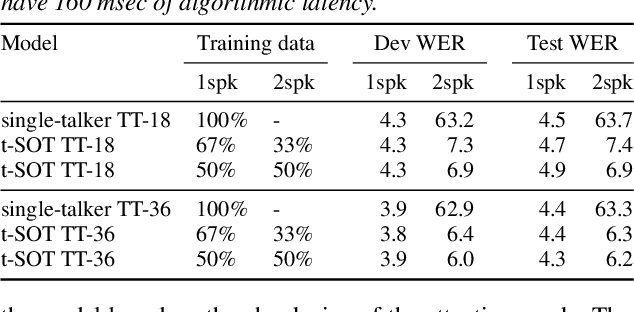
This paper proposes a token-level serialized output training (t-SOT), a novel framework for streaming multi-talker automatic speech recognition (ASR). Unlike existing streaming multi-talker ASR models using multiple output layers, the t-SOT model has only a single output layer that generates recognition tokens (e.g., words, subwords) of multiple speakers in chronological order based on their emission times. A special token that indicates the change of "virtual" output channels is introduced to keep track of the overlapping utterances. Compared to the prior streaming multi-talker ASR models, the t-SOT model has the advantages of less inference cost and a simpler model architecture. Moreover, in our experiments with LibriSpeechMix and LibriCSS datasets, the t-SOT-based transformer transducer model achieves the state-of-the-art word error rates by a significant margin to the prior results. For non-overlapping speech, the t-SOT model is on par with a single-talker ASR model in terms of both accuracy and computational cost, opening the door for deploying one model for both single- and multi-talker scenarios.
Sequence-level self-learning with multiple hypotheses
Dec 10, 2021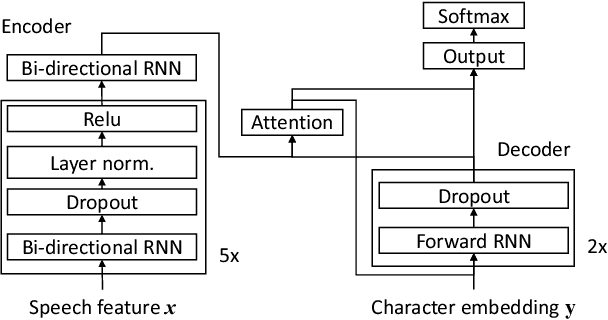
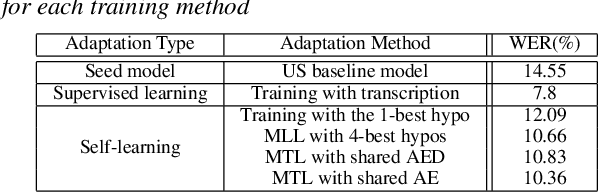
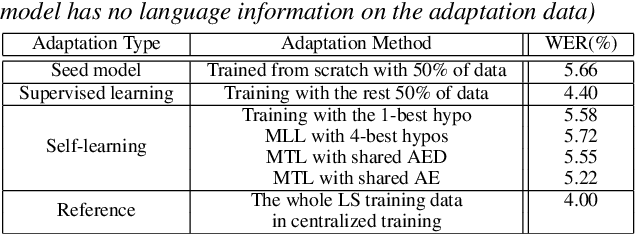
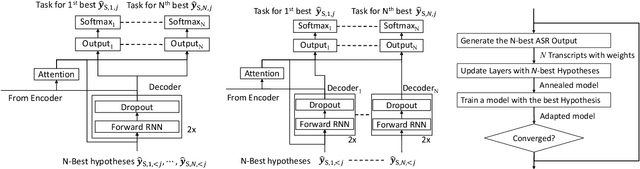
In this work, we develop new self-learning techniques with an attention-based sequence-to-sequence (seq2seq) model for automatic speech recognition (ASR). For untranscribed speech data, the hypothesis from an ASR system must be used as a label. However, the imperfect ASR result makes unsupervised learning difficult to consistently improve recognition performance especially in the case that multiple powerful teacher models are unavailable. In contrast to conventional unsupervised learning approaches, we adopt the \emph{multi-task learning} (MTL) framework where the $n$-th best ASR hypothesis is used as the label of each task. The seq2seq network is updated through the MTL framework so as to find the common representation that can cover multiple hypotheses. By doing so, the effect of the \emph{hard-decision} errors can be alleviated. We first demonstrate the effectiveness of our self-learning methods through ASR experiments in an accent adaptation task between the US and British English speech. Our experiment results show that our method can reduce the WER on the British speech data from 14.55\% to 10.36\% compared to the baseline model trained with the US English data only. Moreover, we investigate the effect of our proposed methods in a federated learning scenario.