 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuDi: Explaining Behavior Sequence Models by Automatic Statistics Generation and Rule Distillation
Aug 16, 2022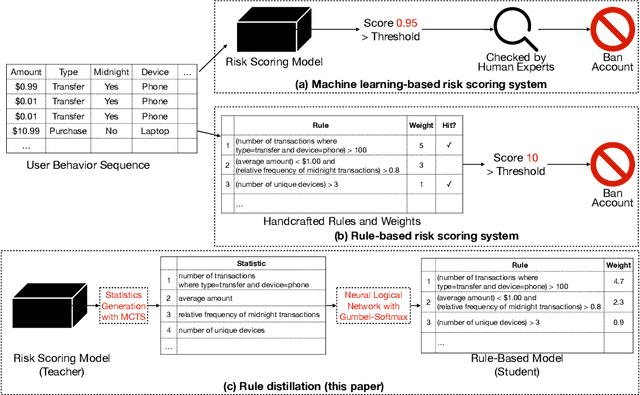
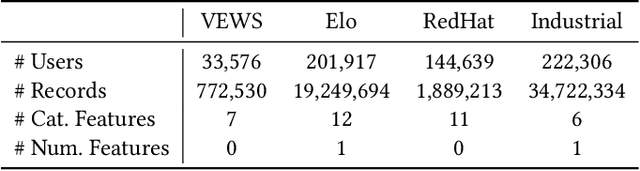
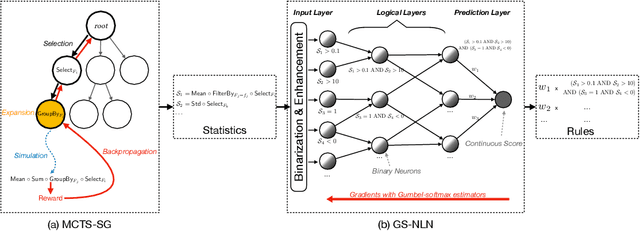
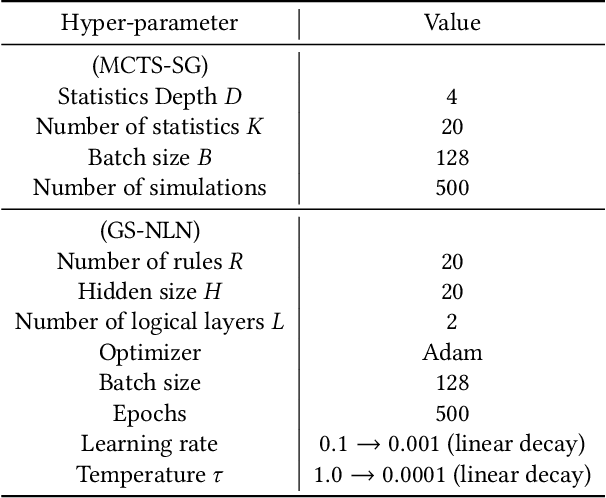
Risk scoring systems have been widely deployed in many applications, which assign risk scores to users according to their behavior sequences. Though many deep learning methods with sophisticated designs have achieved promising results, the black-box nature hinders their applications due to fairness, explainability, and compliance consideration. Rule-based systems are considered reliable in these sensitive scenarios. However, building a rule system is labor-intensive. Experts need to find informative statistics from user behavior sequences, design rules based on statistics and assign weights to each rule. In this paper, we bridge the gap between effective but black-box models and transparent rule models. We propose a two-stage method, RuDi, that distills the knowledge of black-box teacher models into rule-based student models. We design a Monte Carlo tree search-based statistics generation method that can provide a set of informative statistics in the first stage. Then statistics are composed into logical rules with our proposed neural logical networks by mimicking the outputs of teacher models. We evaluate RuDi on three real-world public datasets and an industrial dataset to demonstrate its effectiveness.
ReMix: A General and Efficient Framework for Multiple Instance Learning based Whole Slide Image Classification
Jul 05, 2022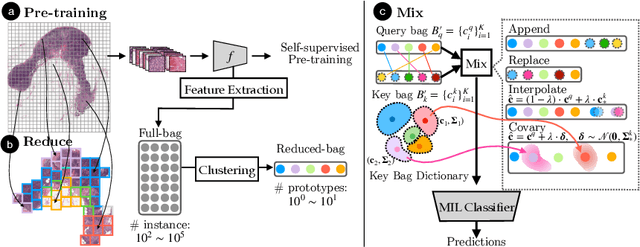
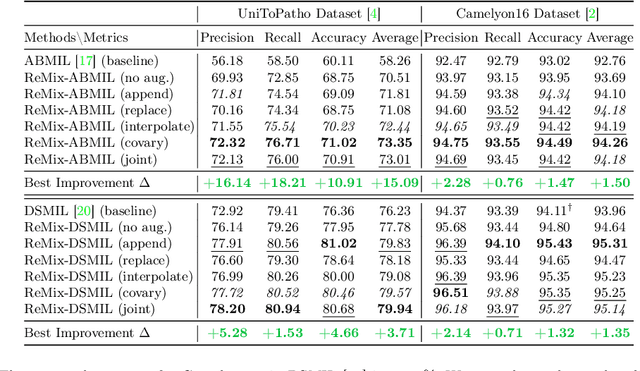
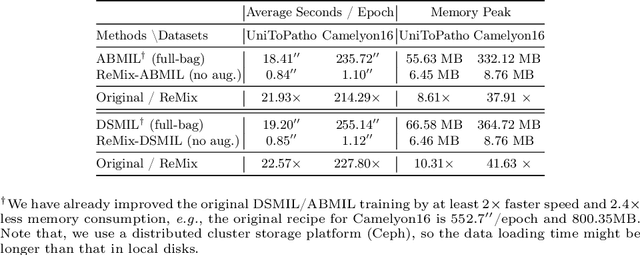

Whole slide image (WSI) classification often relies on deep weakly supervised multiple instance learning (MIL) methods to handle gigapixel resolution images and slide-level labels. Yet the decent performance of deep learning comes from harnessing massive datasets and diverse samples, urging the need for efficient training pipelines for scaling to large datasets and data augmentation techniques for diversifying samples. However, current MIL-based WSI classification pipelines are memory-expensive and computation-inefficient since they usually assemble tens of thousands of patches as bags for computation. On the other hand, despite their popularity in other tasks, data augmentations are unexplored for WSI MIL frameworks. To address them, we propose ReMix, a general and efficient framework for MIL based WSI classification. It comprises two steps: reduce and mix. First, it reduces the number of instances in WSI bags by substituting instances with instance prototypes, i.e., patch cluster centroids. Then, we propose a ``Mix-the-bag'' augmentation that contains four online, stochastic and flexible latent space augmentations. It brings diverse and reliable class-identity-preserving semantic changes in the latent space while enforcing semantic-perturbation invariance. We evaluate ReMix on two public datasets with two state-of-the-art MIL methods. In our experiments, consistent improvements in precision, accuracy, and recall have been achieved but with orders of magnitude reduced training time and memory consumption, demonstrating ReMix's effectiveness and efficiency. Code is available.
ReCo: A Dataset for Residential Community Layout Planning
Jun 08, 2022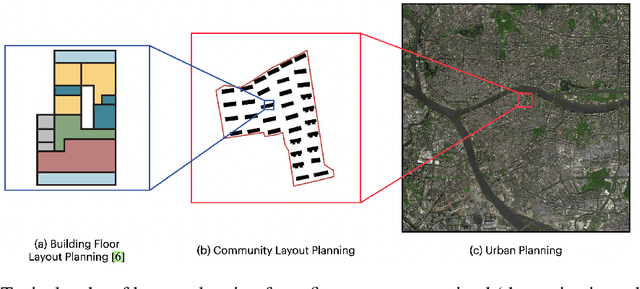
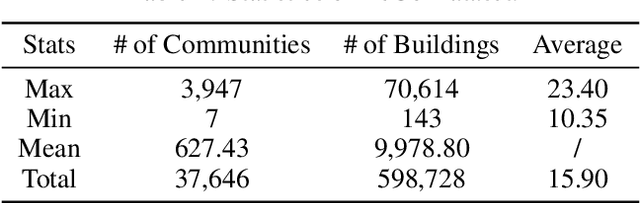
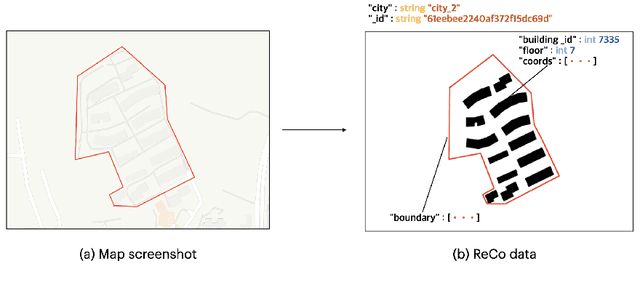
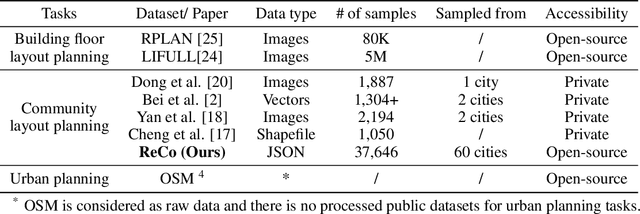
Layout planning is centrally important in the field of architecture and urban design. Among the various basic units carrying urban functions, residential community plays a vital part for supporting human life. Therefore, the layout planning of residential community has always been of concern, and has attracted particular attention since the advent of deep learning that facilitates the automated layout generation and spatial pattern recognition. However, the research circles generally suffer from the insufficiency of residential community layout benchmark or high-quality datasets, which hampers the future exploration of data-driven methods for residential community layout planning. The lack of datasets is largely due to the difficulties of large-scale real-world residential data acquisition and long-term expert screening. In order to address the issues and advance a benchmark dataset for various intelligent spatial design and analysis applications in the development of smart city, we introduce Residential Community Layout Planning (ReCo) Dataset, which is the first and largest open-source vector dataset related to real-world community to date. ReCo Dataset is presented in multiple data formats with 37,646 residential community layout plans, covering 598,728 residential buildings with height information. ReCo can be conveniently adapted for residential community layout related urban design tasks, e.g., generative layout design, morphological pattern recognition and spatial evaluation. To validate the utility of ReCo in automated residential community layout planning, a Generative Adversarial Network (GAN) based generative model is further applied to the dataset. We expect ReCo Dataset to inspire more creative and practical work in intelligent design and beyond. The ReCo Dataset is published at: https://www.kaggle.com/fdudsde/reco-dataset.
mmFormer: Multimodal Medical Transformer for Incomplete Multimodal Learning of Brain Tumor Segmentation
Jun 06, 2022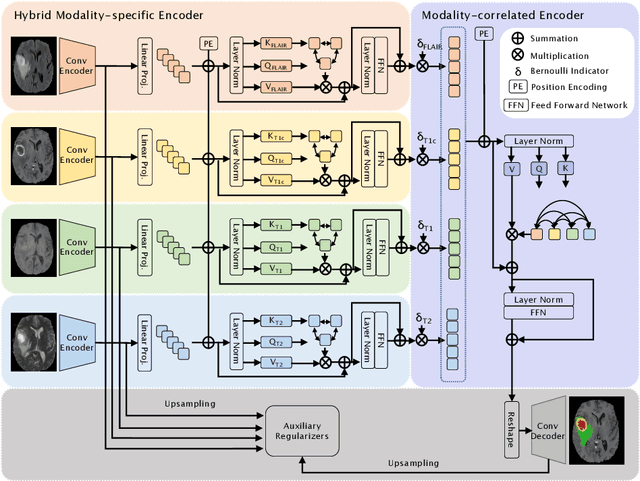
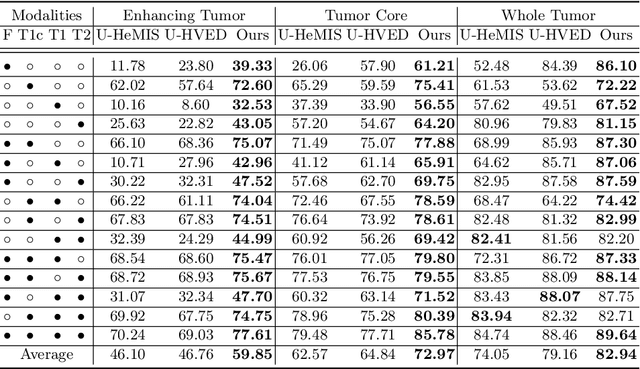

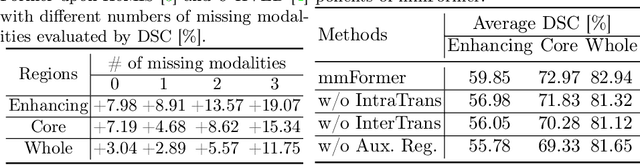
Accurate brain tumor segmentation from Magnetic Resonance Imaging (MRI) is desirable to joint learning of multimodal images. However, in clinical practice, it is not always possible to acquire a complete set of MRIs, and the problem of missing modalities causes severe performance degradation in existing multimodal segmentation methods. In this work, we present the first attempt to exploit the Transformer for multimodal brain tumor segmentation that is robust to any combinatorial subset of available modalities. Concretely, we propose a novel multimodal Medical Transformer (mmFormer) for incomplete multimodal learning with three main components: the hybrid modality-specific encoders that bridge a convolutional encoder and an intra-modal Transformer for both local and global context modeling within each modality; an inter-modal Transformer to build and align the long-range correlations across modalities for modality-invariant features with global semantics corresponding to tumor region; a decoder that performs a progressive up-sampling and fusion with the modality-invariant features to generate robust segmentation. Besides, auxiliary regularizers are introduced in both encoder and decoder to further enhance the model's robustness to incomplete modalities. We conduct extensive experiments on the public BraTS $2018$ dataset for brain tumor segmentation. The results demonstrate that the proposed mmFormer outperforms the state-of-the-art methods for incomplete multimodal brain tumor segmentation on almost all subsets of incomplete modalities, especially by an average 19.07% improvement of Dice on tumor segmentation with only one available modality. The code is available at https://github.com/YaoZhang93/mmFormer.
Decoupled Pyramid Correlation Network for Liver Tumor Segmentation from CT images
May 26, 2022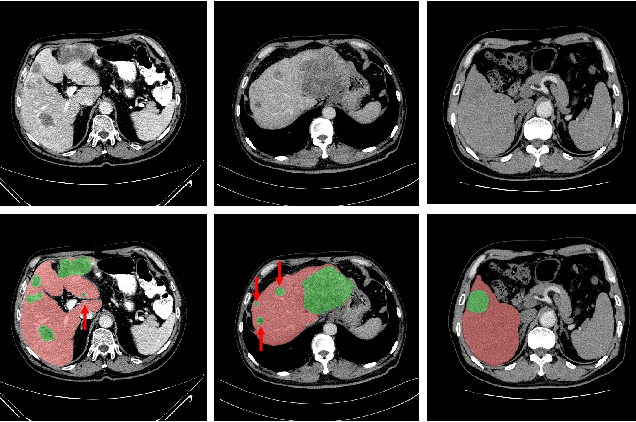
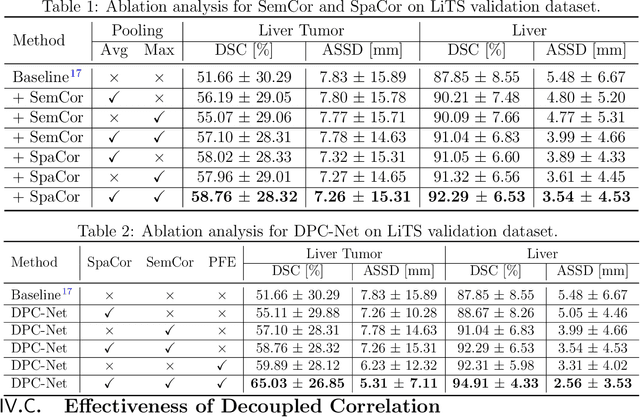
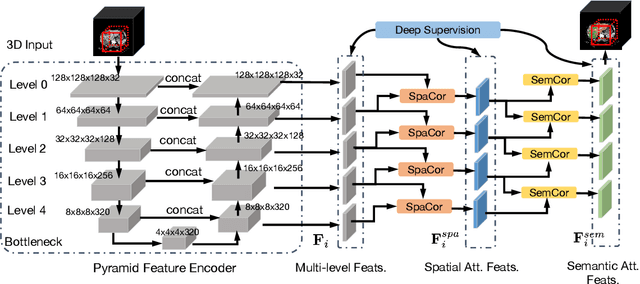
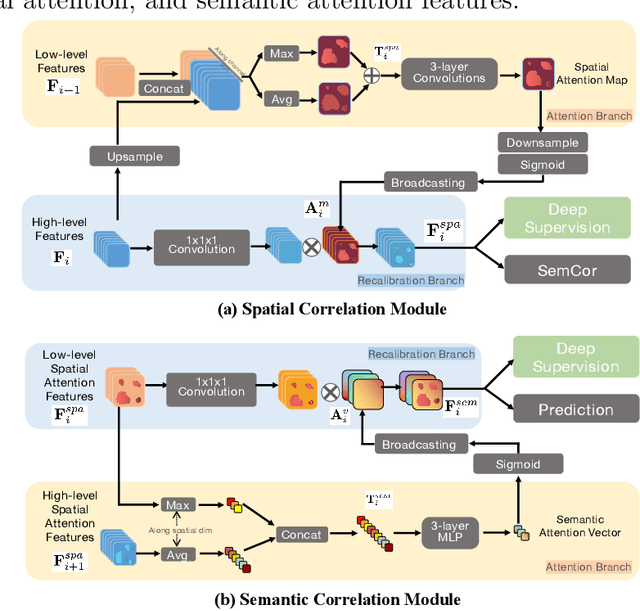
Purpose: Automated liver tumor segmentation from Computed Tomography (CT) images is a necessary prerequisite in the interventions of hepatic abnormalities and surgery planning. However, accurate liver tumor segmentation remains challenging due to the large variability of tumor sizes and inhomogeneous texture. Recent advances based on Fully Convolutional Network (FCN) for medical image segmentation drew on the success of learning discriminative pyramid features. In this paper, we propose a Decoupled Pyramid Correlation Network (DPC-Net) that exploits attention mechanisms to fully leverage both low- and high-level features embedded in FCN to segment liver tumor. Methods: We first design a powerful Pyramid Feature Encoder (PFE) to extract multi-level features from input images. Then we decouple the characteristics of features concerning spatial dimension (i.e., height, width, depth) and semantic dimension (i.e., channel). On top of that, we present two types of attention modules, Spatial Correlation (SpaCor) and Semantic Correlation (SemCor) modules, to recursively measure the correlation of multi-level features. The former selectively emphasizes global semantic information in low-level features with the guidance of high-level ones. The latter adaptively enhance spatial details in high-level features with the guidance of low-level ones. Results: We evaluate the DPC-Net on MICCAI 2017 LiTS Liver Tumor Segmentation (LiTS) challenge dataset. Dice Similarity Coefficient (DSC) and Average Symmetric Surface Distance (ASSD) are employed for evaluation. The proposed method obtains a DSC of 76.4% and an ASSD of 0.838 mm for liver tumor segmentation, outperforming the state-of-the-art methods. It also achieves a competitive results with a DSC of 96.0% and an ASSD of 1.636 mm for liver segmentation.
Interacting with Non-Cooperative User: A New Paradigm for Proactive Dialogue Policy
Apr 07, 2022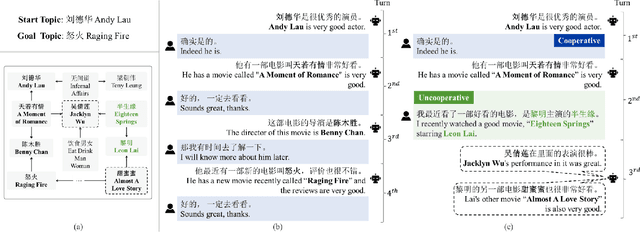
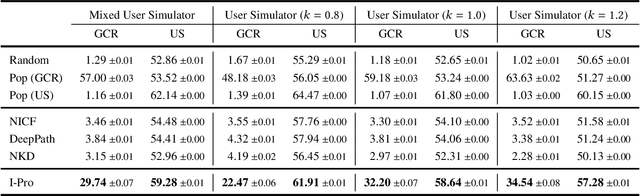

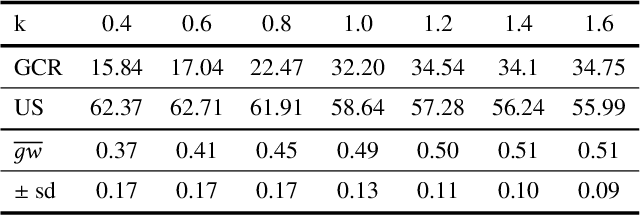
Proactive dialogue system is able to lead the conversation to a goal topic and has advantaged potential in bargain, persuasion and negotiation. Current corpus-based learning manner limits its practical application in real-world scenarios. To this end, we contribute to advance the study of the proactive dialogue policy to a more natural and challenging setting, i.e., interacting dynamically with users. Further, we call attention to the non-cooperative user behavior -- the user talks about off-path topics when he/she is not satisfied with the previous topics introduced by the agent. We argue that the targets of reaching the goal topic quickly and maintaining a high user satisfaction are not always converge, because the topics close to the goal and the topics user preferred may not be the same. Towards this issue, we propose a new solution named I-Pro that can learn Proactive policy in the Interactive setting. Specifically, we learn the trade-off via a learned goal weight, which consists of four factors (dialogue turn, goal completion difficulty, user satisfaction estimation, and cooperative degree). The experimental results demonstrate I-Pro significantly outperforms baselines in terms of effectiveness and interpretability.
Modeling Temporal-Modal Entity Graph for Procedural Multimodal Machine Comprehension
Apr 06, 2022Procedural Multimodal Documents (PMDs) organize textual instructions and corresponding images step by step. Comprehending PMDs and inducing their representations for the downstream reasoning tasks is designated as Procedural MultiModal Machine Comprehension (M3C). In this study, we approach Procedural M3C at a fine-grained level (compared with existing explorations at a document or sentence level), that is, entity. With delicate consideration, we model entity both in its temporal and cross-modal relation and propose a novel Temporal-Modal Entity Graph (TMEG). Specifically, graph structure is formulated to capture textual and visual entities and trace their temporal-modal evolution. In addition, a graph aggregation module is introduced to conduct graph encoding and reasoning. Comprehensive experiments across three Procedural M3C tasks are conducted on a traditional dataset RecipeQA and our new dataset CraftQA, which can better evaluate the generalization of TMEG.
Enhanced Temporal Knowledge Embeddings with Contextualized Language Representations
Mar 21, 2022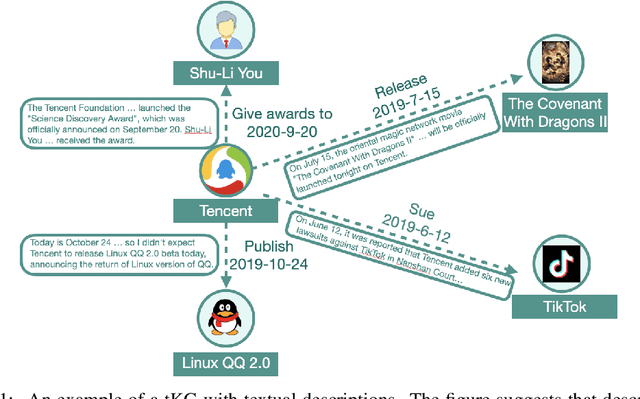

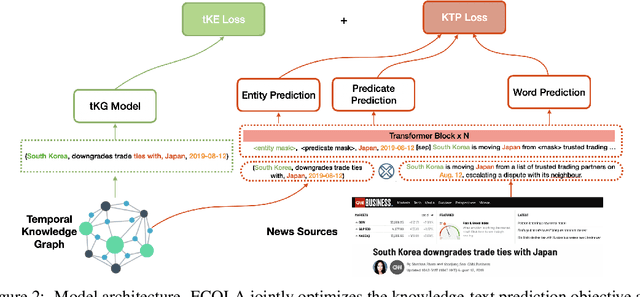
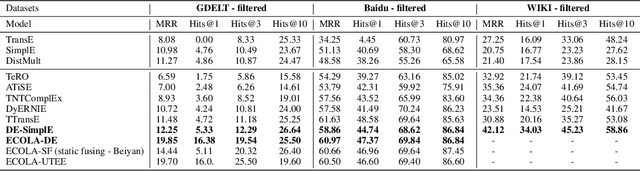
With the emerging research effort to integrate structured and unstructured knowledge, many approaches incorporate factual knowledge into pre-trained language models (PLMs) and apply the knowledge-enhanced PLMs on downstream NLP tasks. However, (1) they only consider static factual knowledge, but knowledge graphs (KGs) also contain temporal facts or events indicating evolutionary relationships among entities at different timestamps. (2) PLMs cannot be directly applied to many KG tasks, such as temporal KG completion. In this paper, we focus on \textbf{e}nhancing temporal knowledge embeddings with \textbf{co}ntextualized \textbf{la}nguage representations (ECOLA). We align structured knowledge contained in temporal knowledge graphs with their textual descriptions extracted from news articles and propose a novel knowledge-text prediction task to inject the abundant information from descriptions into temporal knowledge embeddings. ECOLA jointly optimizes the knowledge-text prediction objective and the temporal knowledge embeddings, which can simultaneously take full advantage of textual and knowledge information. For training ECOLA, we introduce three temporal KG datasets with aligned textual descriptions. Experimental results on the temporal knowledge graph completion task show that ECOLA outperforms state-of-the-art temporal KG models by a large margin. The proposed datasets can serve as new temporal KG benchmarks and facilitate future research on structured and unstructured knowledge integration.
Collaborative Driving: Learning- Aided Joint Topology Formulation and Beamforming
Mar 18, 2022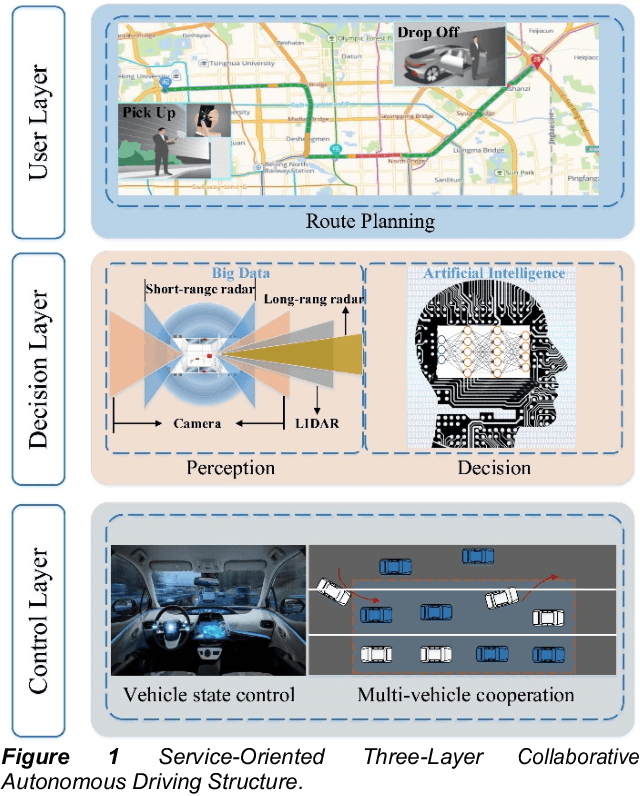
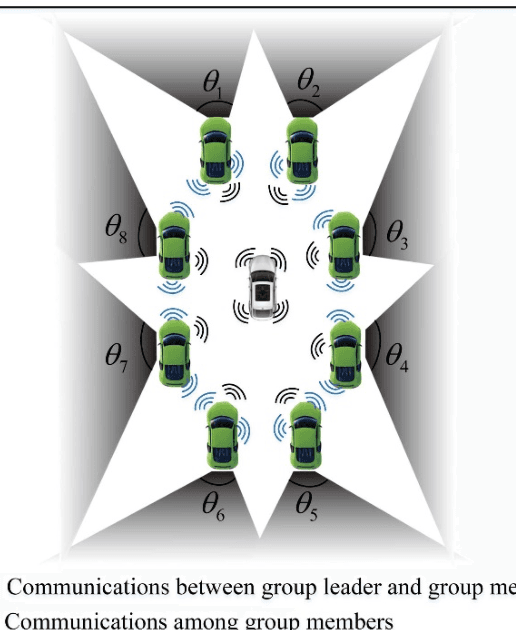
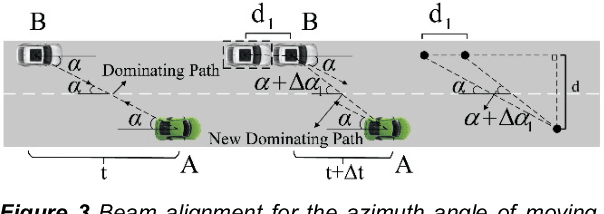
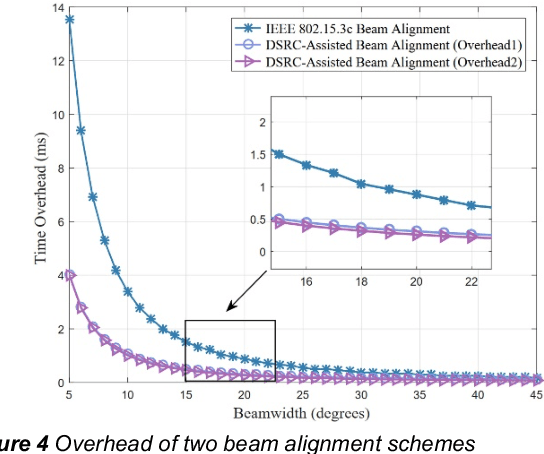
Currently, autonomous vehicles are able to drive more naturally based on the driving policies learned from millions of driving miles in real environments. However, to further improve the automation level of vehicles is a challenging task, especially in the case of multi-vehicle cooperation. In recent heated discussions of 6G, millimeter-wave (mmWave) and terahertz (THz) bands are deemed to play important roles in new radio communication architectures and algorithms. To enable reliable autonomous driving in 6G, in this paper, we envision collaborative autonomous driving, a new framework that jointly controls driving topology and formulate vehicular networks in the mmWave/THz bands. As a swarm intelligence system, the collaborative driving scheme goes beyond existing autonomous driving patterns based on single-vehicle intelligence in terms of safety and efficiency. With efficient data sharing, the proposed framework is able to achieve cooperative sensing and load balancing so that improve sensing efficiency with saved computational resources. To deal with the new challenges in the collaborative driving framework, we further illustrate two promising approaches for mmWave/THz-based vehicle-to-vehicle (V2V) communications. Finally, we discuss several potential open research problems for the proposed collaborative driving scheme.
Graph Attention Transformer Network for Multi-Label Image Classification
Mar 08, 2022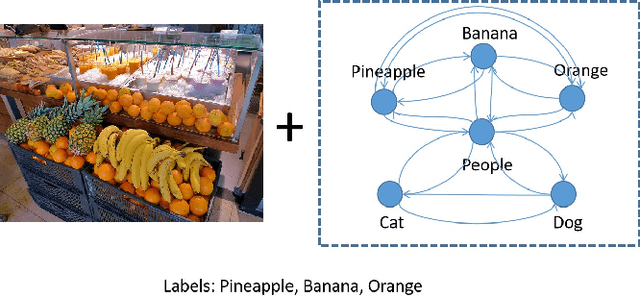
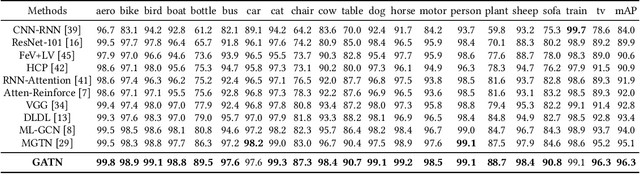
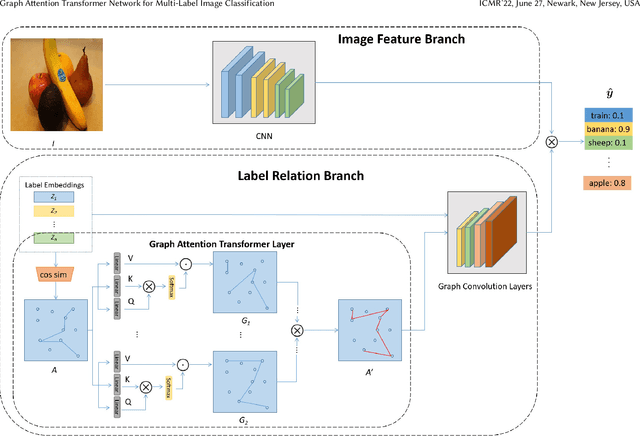
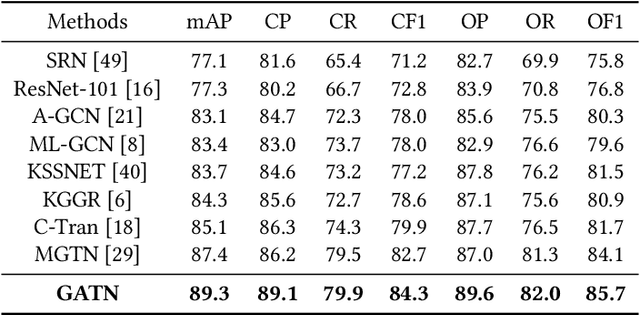
Multi-label classification aims to recognize multiple objects or attributes from images. However, it is challenging to learn from proper label graphs to effectively characterize such inter-label correlations or dependencies. Current methods often use the co-occurrence probability of labels based on the training set as the adjacency matrix to model this correlation, which is greatly limited by the dataset and affects the model's generalization ability. In this paper, we propose a Graph Attention Transformer Network (GATN), a general framework for multi-label image classification that can effectively mine complex inter-label relationships. First, we use the cosine similarity based on the label word embedding as the initial correlation matrix, which can represent rich semantic information. Subsequently, we design the graph attention transformer layer to transfer this adjacency matrix to adapt to the current domain. Our extensive experiments have demonstrated that our proposed methods can achieve state-of-the-art performance on three datasets.