 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity-Level Text-Guided Image Manipulation
Feb 22, 2023



Existing text-guided image manipulation methods aim to modify the appearance of the image or to edit a few objects in a virtual or simple scenario, which is far from practical applications. In this work, we study a novel task on text-guided image manipulation on the entity level in the real world (eL-TGIM). The task imposes three basic requirements, (1) to edit the entity consistent with the text descriptions, (2) to preserve the entity-irrelevant regions, and (3) to merge the manipulated entity into the image naturally. To this end, we propose an elegant framework, dubbed as SeMani, forming the Semantic Manipulation of real-world images that can not only edit the appearance of entities but also generate new entities corresponding to the text guidance. To solve eL-TGIM, SeMani decomposes the task into two phases: the semantic alignment phase and the image manipulation phase. In the semantic alignment phase, SeMani incorporates a semantic alignment module to locate the entity-relevant region to be manipulated. In the image manipulation phase, SeMani adopts a generative model to synthesize new images conditioned on the entity-irrelevant regions and target text descriptions. We discuss and propose two popular generation processes that can be utilized in SeMani, the discrete auto-regressive generation with transformers and the continuous denoising generation with diffusion models, yielding SeMani-Trans and SeMani-Diff, respectively. We conduct extensive experiments on the real datasets CUB, Oxford, and COCO datasets to verify that SeMani can distinguish the entity-relevant and -irrelevant regions and achieve more precise and flexible manipulation in a zero-shot manner compared with baseline methods. Our codes and models will be released at https://github.com/Yikai-Wang/SeMani.
Meta Style Adversarial Training for Cross-Domain Few-Shot Learning
Feb 18, 2023Cross-Domain Few-Shot Learning (CD-FSL) is a recently emerging task that tackles few-shot learning across different domains. It aims at transferring prior knowledge learned on the source dataset to novel target datasets. The CD-FSL task is especially challenged by the huge domain gap between different datasets. Critically, such a domain gap actually comes from the changes of visual styles, and wave-SAN empirically shows that spanning the style distribution of the source data helps alleviate this issue. However, wave-SAN simply swaps styles of two images. Such a vanilla operation makes the generated styles ``real'' and ``easy'', which still fall into the original set of the source styles. Thus, inspired by vanilla adversarial learning, a novel model-agnostic meta Style Adversarial training (StyleAdv) method together with a novel style adversarial attack method is proposed for CD-FSL. Particularly, our style attack method synthesizes both ``virtual'' and ``hard'' adversarial styles for model training. This is achieved by perturbing the original style with the signed style gradients. By continually attacking styles and forcing the model to recognize these challenging adversarial styles, our model is gradually robust to the visual styles, thus boosting the generalization ability for novel target datasets. Besides the typical CNN-based backbone, we also employ our StyleAdv method on large-scale pretrained vision transformer. Extensive experiments conducted on eight various target datasets show the effectiveness of our method. Whether built upon ResNet or ViT, we achieve the new state of the art for CD-FSL. Codes and models will be released.
Exploring Efficient Few-shot Adaptation for Vision Transformers
Jan 06, 2023The task of Few-shot Learning (FSL) aims to do the inference on novel categories containing only few labeled examples, with the help of knowledge learned from base categories containing abundant labeled training samples. While there are numerous works into FSL task, Vision Transformers (ViTs) have rarely been taken as the backbone to FSL with few trials focusing on naive finetuning of whole backbone or classification layer.} Essentially, despite ViTs have been shown to enjoy comparable or even better performance on other vision tasks, it is still very nontrivial to efficiently finetune the ViTs in real-world FSL scenarios. To this end, we propose a novel efficient Transformer Tuning (eTT) method that facilitates finetuning ViTs in the FSL tasks. The key novelties come from the newly presented Attentive Prefix Tuning (APT) and Domain Residual Adapter (DRA) for the task and backbone tuning, individually. Specifically, in APT, the prefix is projected to new key and value pairs that are attached to each self-attention layer to provide the model with task-specific information. Moreover, we design the DRA in the form of learnable offset vectors to handle the potential domain gaps between base and novel data. To ensure the APT would not deviate from the initial task-specific information much, we further propose a novel prototypical regularization, which maximizes the similarity between the projected distribution of prefix and initial prototypes, regularizing the update procedure. Our method receives outstanding performance on the challenging Meta-Dataset. We conduct extensive experiments to show the efficacy of our model.
Vocabulary-informed Zero-shot and Open-set Learning
Jan 04, 2023Despite significant progress in object categorization, in recent years, a number of important challenges remain; mainly, the ability to learn from limited labeled data and to recognize object classes within large, potentially open, set of labels. Zero-shot learning is one way of addressing these challenges, but it has only been shown to work with limited sized class vocabularies and typically requires separation between supervised and unsupervised classes, allowing former to inform the latter but not vice versa. We propose the notion of vocabulary-informed learning to alleviate the above mentioned challenges and address problems of supervised, zero-shot, generalized zero-shot and open set recognition using a unified framework. Specifically, we propose a weighted maximum margin framework for semantic manifold-based recognition that incorporates distance constraints from (both supervised and unsupervised) vocabulary atoms. Distance constraints ensure that labeled samples are projected closer to their correct prototypes, in the embedding space, than to others. We illustrate that resulting model shows improvements in supervised, zero-shot, generalized zero-shot, and large open set recognition, with up to 310K class vocabulary on Animal with Attributes and ImageNet datasets.
* 17 pages, 8 figures. TPAMI 2019 extended from CVPR 2016 (arXiv:1604.07093)
Knockoffs-SPR: Clean Sample Selection in Learning with Noisy Labels
Jan 03, 2023A noisy training set usually leads to the degradation of the generalization and robustness of neural networks. In this paper, we propose a novel theoretically guaranteed clean sample selection framework for learning with noisy labels. Specifically, we first present a Scalable Penalized Regression (SPR) method, to model the linear relation between network features and one-hot labels. In SPR, the clean data are identified by the zero mean-shift parameters solved in the regression model. We theoretically show that SPR can recover clean data under some conditions. Under general scenarios, the conditions may be no longer satisfied; and some noisy data are falsely selected as clean data. To solve this problem, we propose a data-adaptive method for Scalable Penalized Regression with Knockoff filters (Knockoffs-SPR), which is provable to control the False-Selection-Rate (FSR) in the selected clean data. To improve the efficiency, we further present a split algorithm that divides the whole training set into small pieces that can be solved in parallel to make the framework scalable to large datasets. While Knockoffs-SPR can be regarded as a sample selection module for a standard supervised training pipeline, we further combine it with a semi-supervised algorithm to exploit the support of noisy data as unlabeled data. Experimental results on several benchmark datasets and real-world noisy datasets show the effectiveness of our framework and validate the theoretical results of Knockoffs-SPR. Our code and pre-trained models will be released.
Split-PU: Hardness-aware Training Strategy for Positive-Unlabeled Learning
Nov 30, 2022



Positive-Unlabeled (PU) learning aims to learn a model with rare positive samples and abundant unlabeled samples. Compared with classical binary classification, the task of PU learning is much more challenging due to the existence of many incompletely-annotated data instances. Since only part of the most confident positive samples are available and evidence is not enough to categorize the rest samples, many of these unlabeled data may also be the positive samples. Research on this topic is particularly useful and essential to many real-world tasks which demand very expensive labelling cost. For example, the recognition tasks in disease diagnosis, recommendation system and satellite image recognition may only have few positive samples that can be annotated by the experts. These methods mainly omit the intrinsic hardness of some unlabeled data, which can result in sub-optimal performance as a consequence of fitting the easy noisy data and not sufficiently utilizing the hard data. In this paper, we focus on improving the commonly-used nnPU with a novel training pipeline. We highlight the intrinsic difference of hardness of samples in the dataset and the proper learning strategies for easy and hard data. By considering this fact, we propose first splitting the unlabeled dataset with an early-stop strategy. The samples that have inconsistent predictions between the temporary and base model are considered as hard samples. Then the model utilizes a noise-tolerant Jensen-Shannon divergence loss for easy data; and a dual-source consistency regularization for hard data which includes a cross-consistency between student and base model for low-level features and self-consistency for high-level features and predictions, respectively.
PatchMix Augmentation to Identify Causal Features in Few-shot Learning
Nov 29, 2022



The task of Few-shot learning (FSL) aims to transfer the knowledge learned from base categories with sufficient labelled data to novel categories with scarce known information. It is currently an important research question and has great practical values in the real-world applications. Despite extensive previous efforts are made on few-shot learning tasks, we emphasize that most existing methods did not take into account the distributional shift caused by sample selection bias in the FSL scenario. Such a selection bias can induce spurious correlation between the semantic causal features, that are causally and semantically related to the class label, and the other non-causal features. Critically, the former ones should be invariant across changes in distributions, highly related to the classes of interest, and thus well generalizable to novel classes, while the latter ones are not stable to changes in the distribution. To resolve this problem, we propose a novel data augmentation strategy dubbed as PatchMix that can break this spurious dependency by replacing the patch-level information and supervision of the query images with random gallery images from different classes from the query ones. We theoretically show that such an augmentation mechanism, different from existing ones, is able to identify the causal features. To further make these features to be discriminative enough for classification, we propose Correlation-guided Reconstruction (CGR) and Hardness-Aware module for instance discrimination and easier discrimination between similar classes. Moreover, such a framework can be adapted to the unsupervised FSL scenario.
RankDNN: Learning to Rank for Few-shot Learning
Nov 29, 2022



This paper introduces a new few-shot learning pipeline that casts relevance ranking for image retrieval as binary ranking relation classification. In comparison to image classification, ranking relation classification is sample efficient and domain agnostic. Besides, it provides a new perspective on few-shot learning and is complementary to state-of-the-art methods. The core component of our deep neural network is a simple MLP, which takes as input an image triplet encoded as the difference between two vector-Kronecker products, and outputs a binary relevance ranking order. The proposed RankMLP can be built on top of any state-of-the-art feature extractors, and our entire deep neural network is called the ranking deep neural network, or RankDNN. Meanwhile, RankDNN can be flexibly fused with other post-processing methods. During the meta test, RankDNN ranks support images according to their similarity with the query samples, and each query sample is assigned the class label of its nearest neighbor. Experiments demonstrate that RankDNN can effectively improve the performance of its baselines based on a variety of backbones and it outperforms previous state-of-the-art algorithms on multiple few-shot learning benchmarks, including miniImageNet, tieredImageNet, Caltech-UCSD Birds, and CIFAR-FS. Furthermore, experiments on the cross-domain challenge demonstrate the superior transferability of RankDNN.The code is available at: https://github.com/guoqianyu-alberta/RankDNN.
Self-supervised Amodal Video Object Segmentation
Oct 23, 2022



Amodal perception requires inferring the full shape of an object that is partially occluded. This task is particularly challenging on two levels: (1) it requires more information than what is contained in the instant retina or imaging sensor, (2) it is difficult to obtain enough well-annotated amodal labels for supervision. To this end, this paper develops a new framework of Self-supervised amodal Video object segmentation (SaVos). Our method efficiently leverages the visual information of video temporal sequences to infer the amodal mask of objects. The key intuition is that the occluded part of an object can be explained away if that part is visible in other frames, possibly deformed as long as the deformation can be reasonably learned. Accordingly, we derive a novel self-supervised learning paradigm that efficiently utilizes the visible object parts as the supervision to guide the training on videos. In addition to learning type prior to complete masks for known types, SaVos also learns the spatiotemporal prior, which is also useful for the amodal task and could generalize to unseen types. The proposed framework achieves the state-of-the-art performance on the synthetic amodal segmentation benchmark FISHBOWL and the real world benchmark KINS-Video-Car. Further, it lends itself well to being transferred to novel distributions using test-time adaptation, outperforming existing models even after the transfer to a new distribution.
ZITS++: Image Inpainting by Improving the Incremental Transformer on Structural Priors
Oct 12, 2022
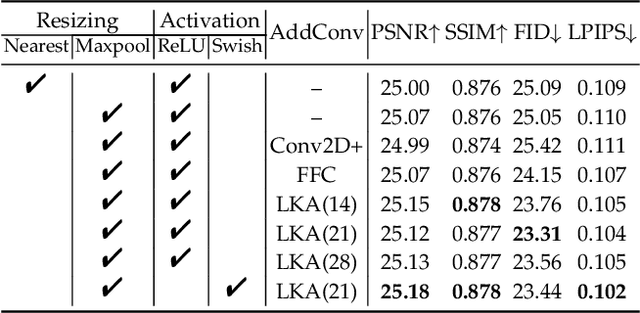

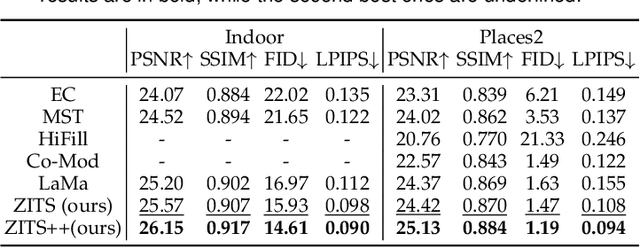
The image inpainting task fills missing areas of a corrupted image. Despite impressive results have been achieved recently, it is still challenging to restore corrupted images with both vivid textures and reasonable structures. Some previous methods only tackle regular textures while losing holistic structures limited by receptive fields of Convolution Neural Networks (CNNs). To this end, we study learning a Zero-initialized residual addition based Incremental Transformer on Structural priors (ZITS++), an improved model over our conference ZITS model. Specifically, given one corrupt image, we present the Transformer Structure Restorer (TSR) module to restore holistic structural priors at low image resolution, which are further upsampled by Simple Structure Upsampler (SSU) module to higher image resolution. Further, to well recover image texture details, we take the Fourier CNN Texture Restoration (FTR) module, which has both the Fourier and large-kernel attention convolutions. Typically, FTR can be independently pre-trained without image structural priors. Furthermore, to enhance the FTR, the upsampled structural priors from TSR are further processed by Structure Feature Encoder (SFE), and updating the FTR by a novel incremental training strategy of Zero-initialized Residual Addition (ZeroRA). Essentially, a new masking positional encoding is proposed to encode the large irregular masks. Extensive experiments on various datasets validate the efficacy of our model compared with other competitors. We also conduct extensive ablation to compare and verify various priors for image inpainting tasks.