 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-Experts with Expert Choice Routing
Feb 18, 2022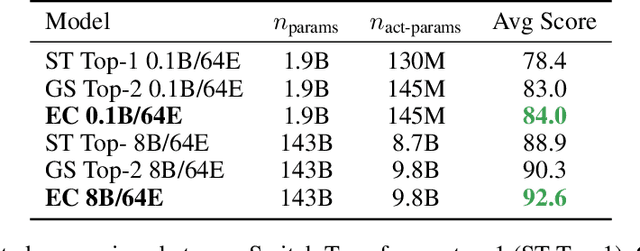
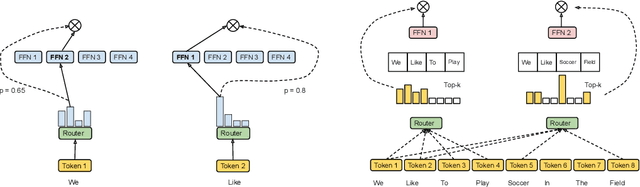
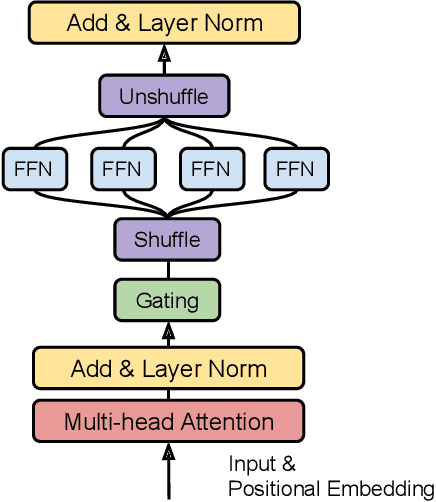

Sparsely-activated Mixture-of-experts (MoE) models allow the number of parameters to greatly increase while keeping the amount of computation for a given token or a given sample unchanged. However, a poor expert routing strategy (e.g. one resulting in load imbalance) can cause certain experts to be under-trained, leading to an expert being under or over-specialized. Prior work allocates a fixed number of experts to each token using a top-k function regardless of the relative importance of different tokens. To address this, we propose a heterogeneous mixture-of-experts employing an expert choice method. Instead of letting tokens select the top-k experts, we have experts selecting the top-k tokens. As a result, each token can be routed to a variable number of experts and each expert can have a fixed bucket size. We systematically study pre-training speedups using the same computational resources of the Switch Transformer top-1 and GShard top-2 gating of prior work and find that our method improves training convergence time by more than 2x. For the same computational cost, our method demonstrates higher performance in fine-tuning 11 selected tasks in the GLUE and SuperGLUE benchmarks. For a smaller activation cost, our method outperforms the T5 dense model in 7 out of the 11 tasks.
LaMDA: Language Models for Dialog Applications
Feb 10, 2022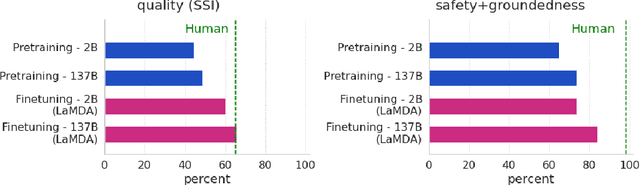
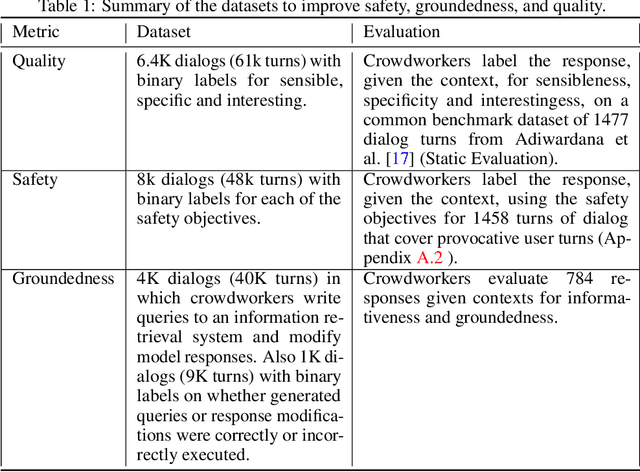

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
Dec 13, 2021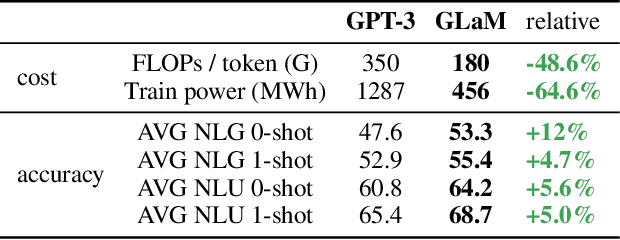
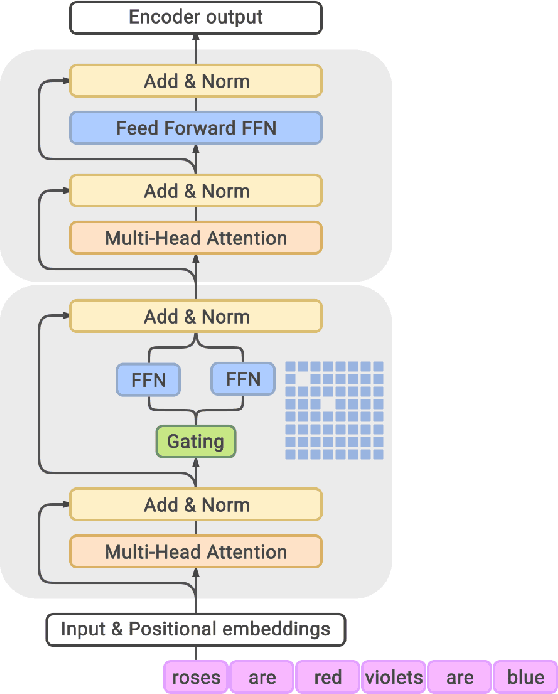
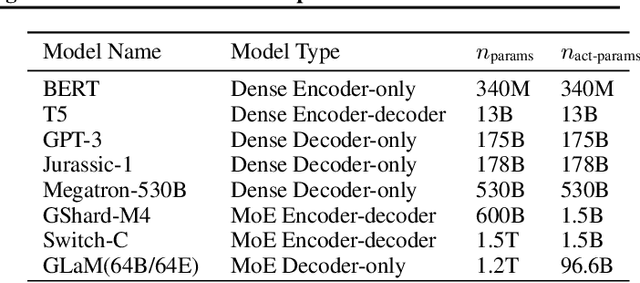
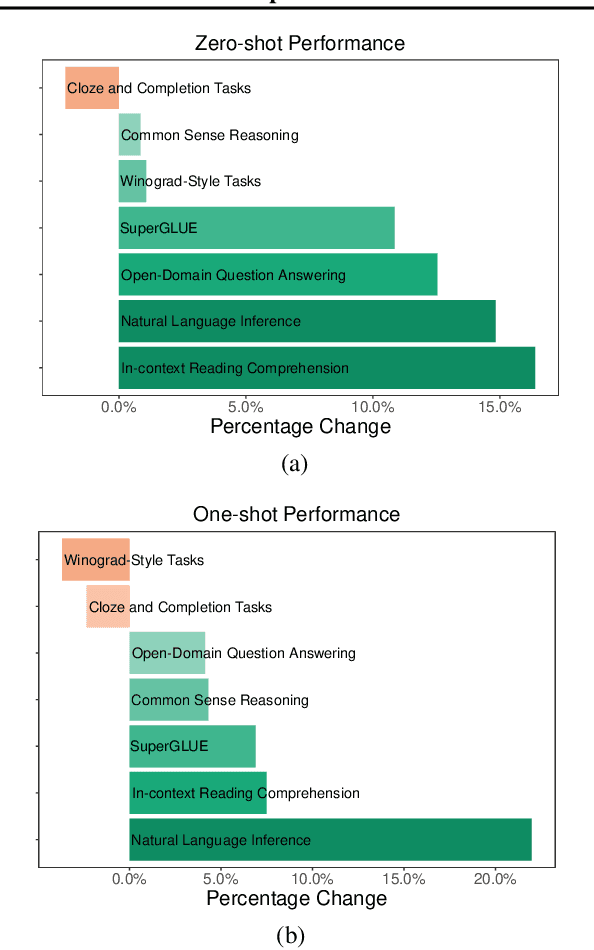
Scaling language models with more data, compute and parameters has driven significant progress in natural language processing. For example, thanks to scaling, GPT-3 was able to achieve strong results on in-context learning tasks. However, training these large dense models requires significant amounts of computing resources. In this paper, we propose and develop a family of language models named GLaM (Generalist Language Model), which uses a sparsely activated mixture-of-experts architecture to scale the model capacity while also incurring substantially less training cost compared to dense variants. The largest GLaM has 1.2 trillion parameters, which is approximately 7x larger than GPT-3. It consumes only 1/3 of the energy used to train GPT-3 and requires half of the computation flops for inference, while still achieving better overall zero-shot and one-shot performance across 29 NLP tasks.
A Transferable Approach for Partitioning Machine Learning Models on Multi-Chip-Modules
Dec 07, 2021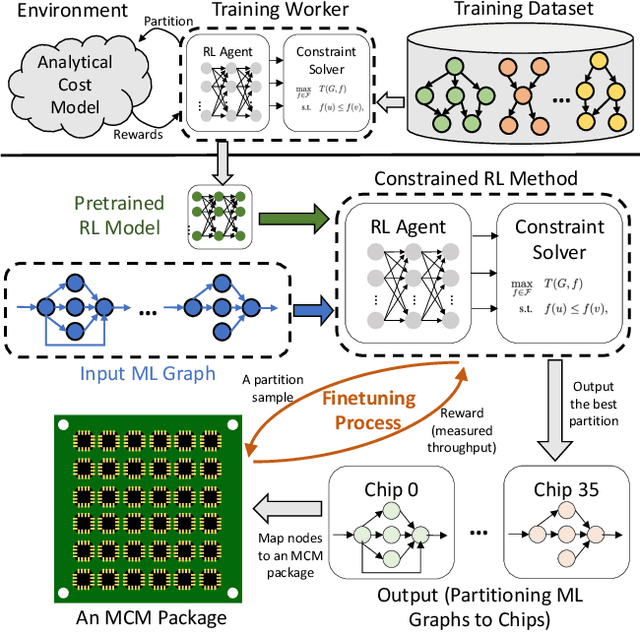
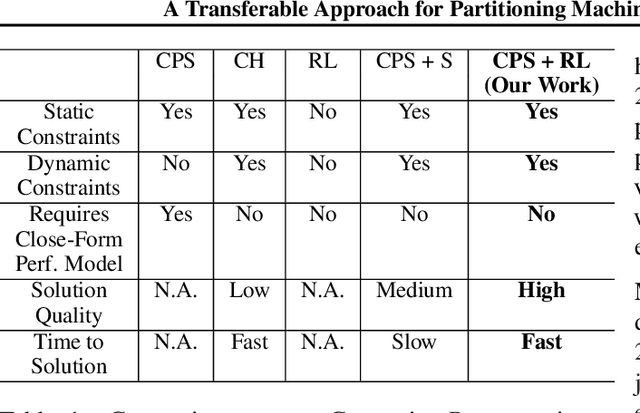
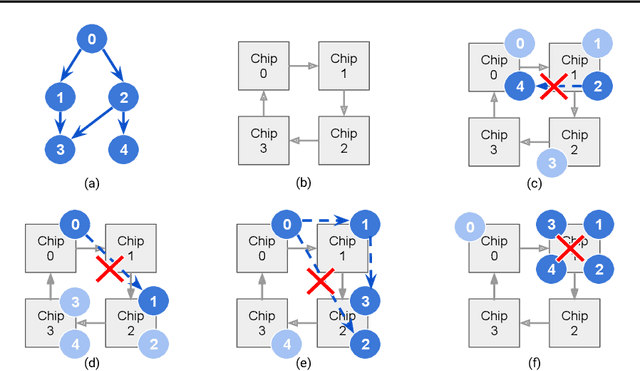

Multi-Chip-Modules (MCMs) reduce the design and fabrication cost of machine learning (ML) accelerators while delivering performance and energy efficiency on par with a monolithic large chip. However, ML compilers targeting MCMs need to solve complex optimization problems optimally and efficiently to achieve this high performance. One such problem is the multi-chip partitioning problem where compilers determine the optimal partitioning and placement of operations in tensor computation graphs on chiplets in MCMs. Partitioning ML graphs for MCMs is particularly hard as the search space grows exponentially with the number of chiplets available and the number of nodes in the neural network. Furthermore, the constraints imposed by the underlying hardware produce a search space where valid solutions are extremely sparse. In this paper, we present a strategy using a deep reinforcement learning (RL) framework to emit a possibly invalid candidate partition that is then corrected by a constraint solver. Using the constraint solver ensures that RL encounters valid solutions in the sparse space frequently enough to converge with fewer samples as compared to non-learned strategies. The architectural choices we make for the policy network allow us to generalize across different ML graphs. Our evaluation of a production-scale model, BERT, on real hardware reveals that the partitioning generated using RL policy achieves 6.11% and 5.85% higher throughput than random search and simulated annealing. In addition, fine-tuning the pre-trained RL policy reduces the search time from 3 hours to only 9 minutes, while achieving the same throughput as training RL policy from scratch.
Do Transformer Modifications Transfer Across Implementations and Applications?
Feb 23, 2021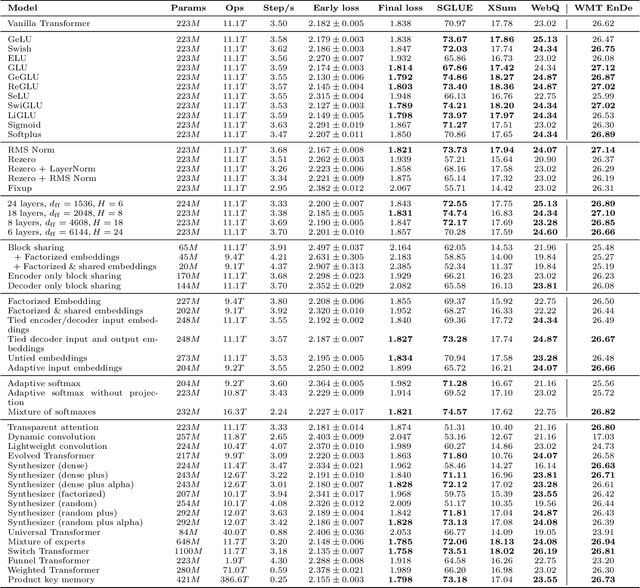
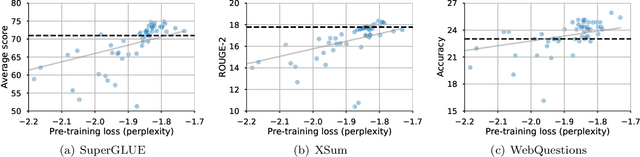
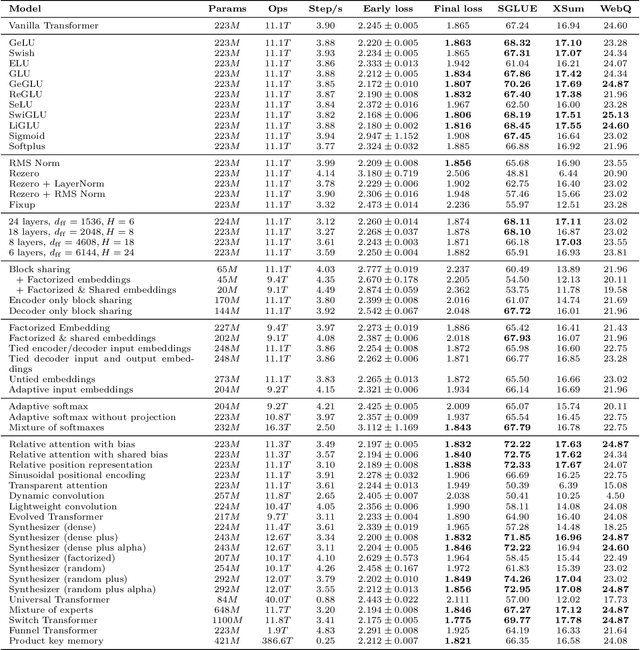
The research community has proposed copious modifications to the Transformer architecture since it was introduced over three years ago, relatively few of which have seen widespread adoption. In this paper, we comprehensively evaluate many of these modifications in a shared experimental setting that covers most of the common uses of the Transformer in natural language processing. Surprisingly, we find that most modifications do not meaningfully improve performance. Furthermore, most of the Transformer variants we found beneficial were either developed in the same codebase that we used or are relatively minor changes. We conjecture that performance improvements may strongly depend on implementation details and correspondingly make some recommendations for improving the generality of experimental results.
Rethinking Co-design of Neural Architectures and Hardware Accelerators
Feb 17, 2021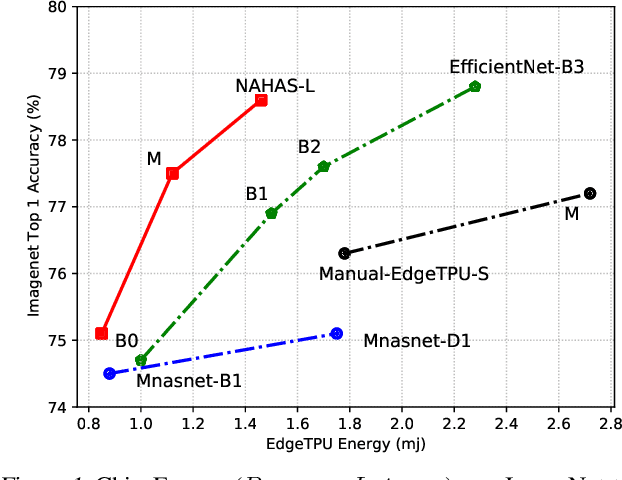
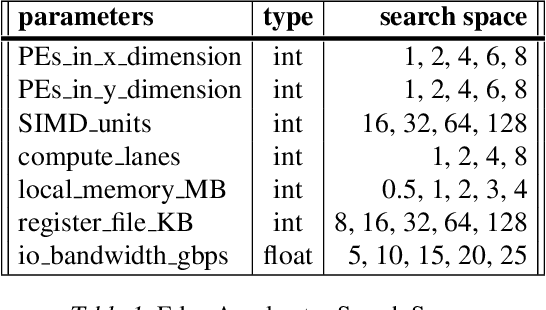
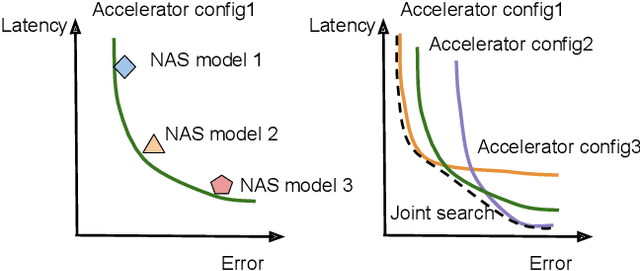
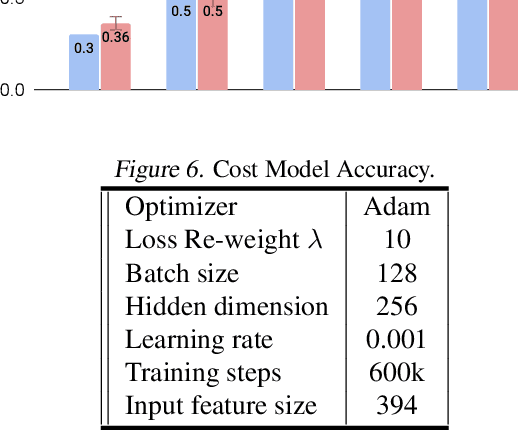
Neural architectures and hardware accelerators have been two driving forces for the progress in deep learning. Previous works typically attempt to optimize hardware given a fixed model architecture or model architecture given fixed hardware. And the dominant hardware architecture explored in this prior work is FPGAs. In our work, we target the optimization of hardware and software configurations on an industry-standard edge accelerator. We systematically study the importance and strategies of co-designing neural architectures and hardware accelerators. We make three observations: 1) the software search space has to be customized to fully leverage the targeted hardware architecture, 2) the search for the model architecture and hardware architecture should be done jointly to achieve the best of both worlds, and 3) different use cases lead to very different search outcomes. Our experiments show that the joint search method consistently outperforms previous platform-aware neural architecture search, manually crafted models, and the state-of-the-art EfficientNet on all latency targets by around 1% on ImageNet top-1 accuracy. Our method can reduce energy consumption of an edge accelerator by up to 2x under the same accuracy constraint, when co-adapting the model architecture and hardware accelerator configurations.
Apollo: Transferable Architecture Exploration
Feb 02, 2021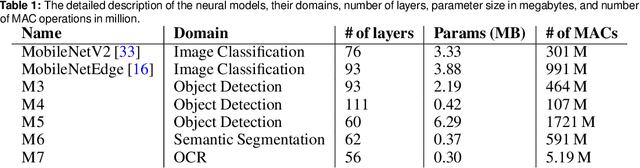
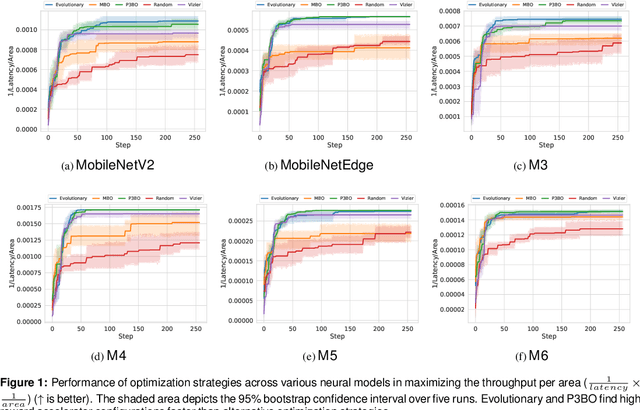

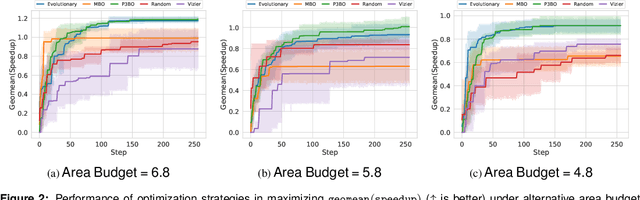
The looming end of Moore's Law and ascending use of deep learning drives the design of custom accelerators that are optimized for specific neural architectures. Architecture exploration for such accelerators forms a challenging constrained optimization problem over a complex, high-dimensional, and structured input space with a costly to evaluate objective function. Existing approaches for accelerator design are sample-inefficient and do not transfer knowledge between related optimizations tasks with different design constraints, such as area and/or latency budget, or neural architecture configurations. In this work, we propose a transferable architecture exploration framework, dubbed Apollo, that leverages recent advances in black-box function optimization for sample-efficient accelerator design. We use this framework to optimize accelerator configurations of a diverse set of neural architectures with alternative design constraints. We show that our framework finds high reward design configurations (up to 24.6% speedup) more sample-efficiently than a baseline black-box optimization approach. We further show that by transferring knowledge between target architectures with different design constraints, Apollo is able to find optimal configurations faster and often with better objective value (up to 25% improvements). This encouraging outcome portrays a promising path forward to facilitate generating higher quality accelerators.
Transferable Graph Optimizers for ML Compilers
Oct 21, 2020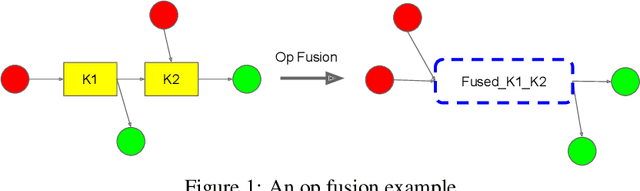

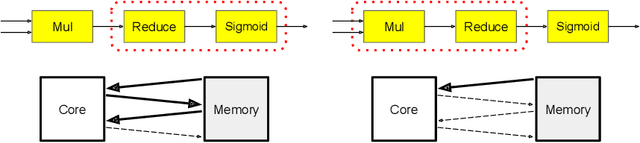
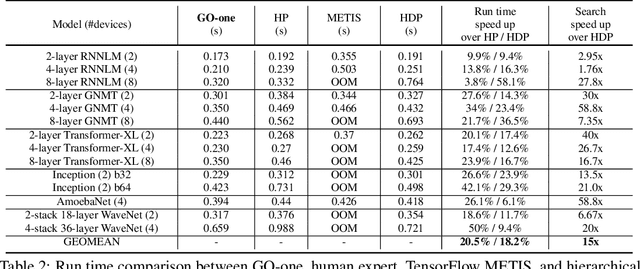
Most compilers for machine learning (ML) frameworks need to solve many correlated optimization problems to generate efficient machine code. Current ML compilers rely on heuristics based algorithms to solve these optimization problems one at a time. However, this approach is not only hard to maintain but often leads to sub-optimal solutions especially for newer model architectures. Existing learning based approaches in the literature are sample inefficient, tackle a single optimization problem, and do not generalize to unseen graphs making them infeasible to be deployed in practice. To address these limitations, we propose an end-to-end, transferable deep reinforcement learning method for computational graph optimization (GO), based on a scalable sequential attention mechanism over an inductive graph neural network. GO generates decisions on the entire graph rather than on each individual node autoregressively, drastically speeding up the search compared to prior methods. Moreover, we propose recurrent attention layers to jointly optimize dependent graph optimization tasks and demonstrate 33%-60% speedup on three graph optimization tasks compared to TensorFlow default optimization. On a diverse set of representative graphs consisting of up to 80,000 nodes, including Inception-v3, Transformer-XL, and WaveNet, GO achieves on average 21% improvement over human experts and 18% improvement over the prior state of the art with 15x faster convergence, on a device placement task evaluated in real systems.
* arXiv admin note: text overlap with arXiv:1910.01578
A Learned Performance Model for the Tensor Processing Unit
Aug 03, 2020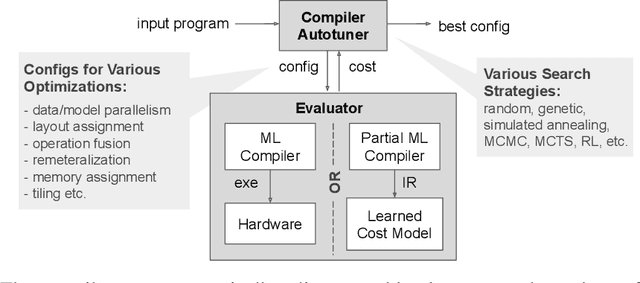
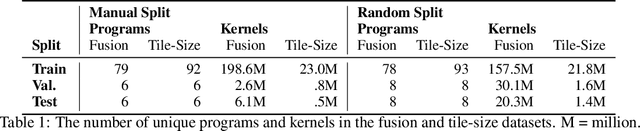
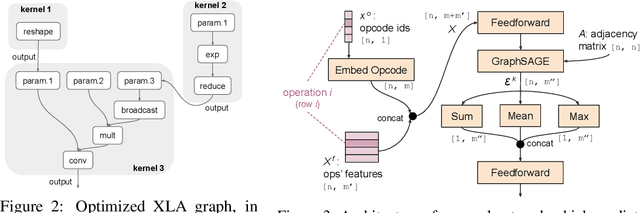
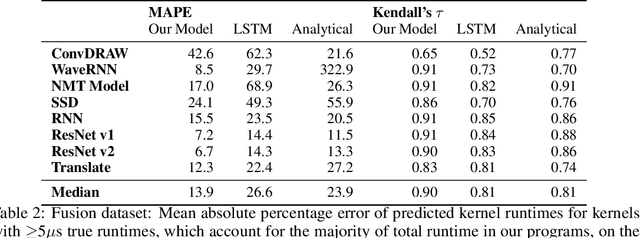
Accurate hardware performance models are critical to efficient code generation. They can be used by compilers to make heuristic decisions, by superoptimizers as an minimization objective, or by autotuners to find an optimal configuration of a specific program. However, they are difficult to develop because contemporary processors are complex, and the recent proliferation of deep learning accelerators has increased the development burden. We demonstrate a method of learning performance models from a corpus of tensor computation graph programs for the Tensor Processing Unit (TPU). We train a neural network over kernel-level sub-graphs from the corpus and find that the learned model is competitive to a heavily-optimized analytical cost model used in the production XLA compiler.
ODE-CNN: Omnidirectional Depth Extension Networks
Jul 03, 2020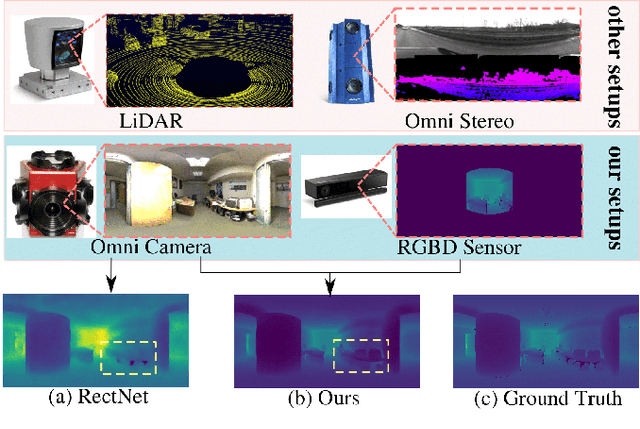
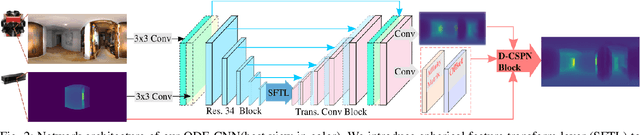
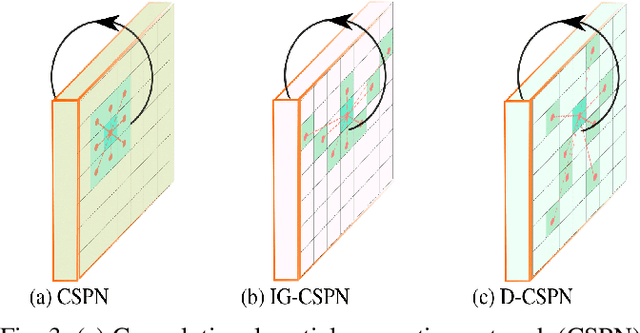

Omnidirectional 360{\deg} camera proliferates rapidly for autonomous robots since it significantly enhances the perception ability by widening the field of view(FoV). However, corresponding 360{\deg} depth sensors, which are also critical for the perception system, are still difficult or expensive to have. In this paper, we propose a low-cost 3D sensing system that combines an omnidirectional camera with a calibrated projective depth camera, where the depth from the limited FoV can be automatically extended to the rest of the recorded omnidirectional image. To accurately recover the missing depths, we design an omnidirectional depth extension convolutional neural network(ODE-CNN), in which a spherical feature transform layer(SFTL) is embedded at the end of feature encoding layers, and a deformable convolutional spatial propagation network(D-CSPN) is appended at the end of feature decoding layers. The former resamples the neighborhood of each pixel in the omnidirectional coordination to the projective coordination, which reduces the difficulty of feature learning, and the later automatically finds a proper context to well align the structures in the estimated depths via CNN w.r.t. the reference image, which significantly improves the visual quality. Finally, we demonstrate the effectiveness of proposed ODE-CNN over the popular 360D dataset and show that ODE-CNN significantly outperforms (relatively 33% reduction in-depth error) other state-of-the-art (SoTA) methods.