 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntra-Instance VICReg: Bag of Self-Supervised Image Patch Embedding
Jun 17, 2022

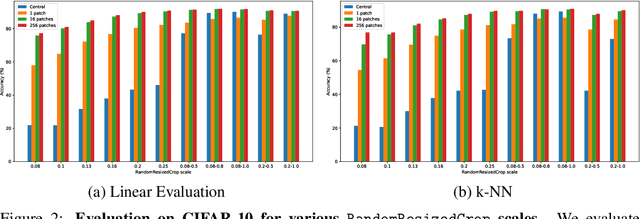

Recently, self-supervised learning (SSL) has achieved tremendous empirical advancements in learning image representation. However, our understanding and knowledge of the representation are still limited. This work shows that the success of the SOTA siamese-network-based SSL approaches is primarily based on learning a representation of image patches. Particularly, we show that when we learn a representation only for fixed-scale image patches and aggregate different patch representations linearly for an image (instance), it can achieve on par or even better results than the baseline methods on several benchmarks. Further, we show that the patch representation aggregation can also improve various SOTA baseline methods by a large margin. We also establish a formal connection between the SSL objective and the image patches co-occurrence statistics modeling, which supplements the prevailing invariance perspective. By visualizing the nearest neighbors of different image patches in the embedding space and projection space, we show that while the projection has more invariance, the embedding space tends to preserve more equivariance and locality. Finally, we propose a hypothesis for the future direction based on the discovery of this work.
Masked Siamese ConvNets
Jun 15, 2022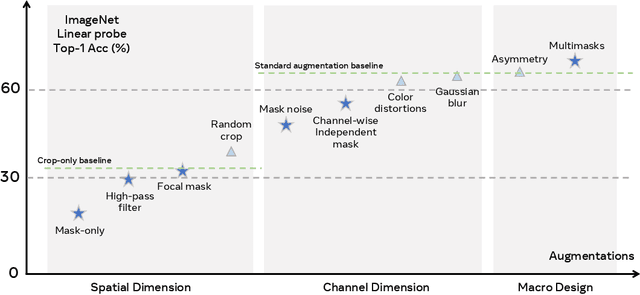
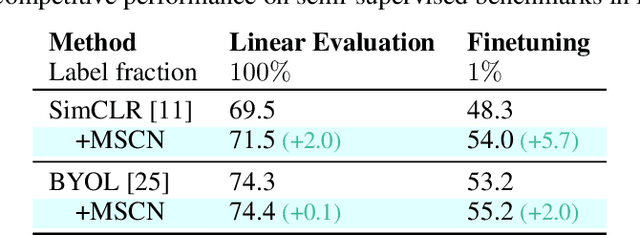

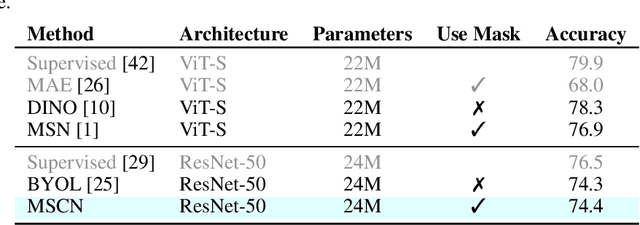
Self-supervised learning has shown superior performances over supervised methods on various vision benchmarks. The siamese network, which encourages embeddings to be invariant to distortions, is one of the most successful self-supervised visual representation learning approaches. Among all the augmentation methods, masking is the most general and straightforward method that has the potential to be applied to all kinds of input and requires the least amount of domain knowledge. However, masked siamese networks require particular inductive bias and practically only work well with Vision Transformers. This work empirically studies the problems behind masked siamese networks with ConvNets. We propose several empirical designs to overcome these problems gradually. Our method performs competitively on low-shot image classification and outperforms previous methods on object detection benchmarks. We discuss several remaining issues and hope this work can provide useful data points for future general-purpose self-supervised learning.
Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone
Jun 15, 2022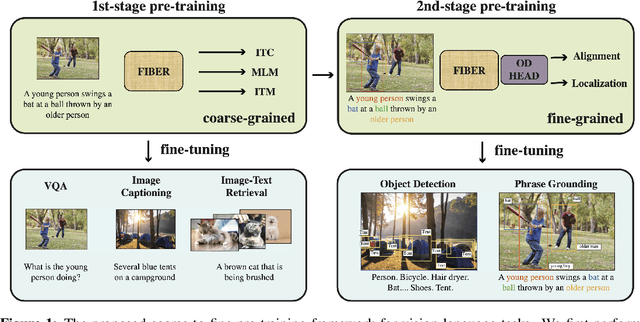

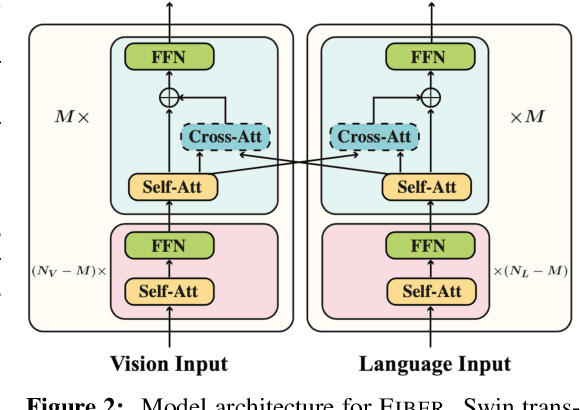
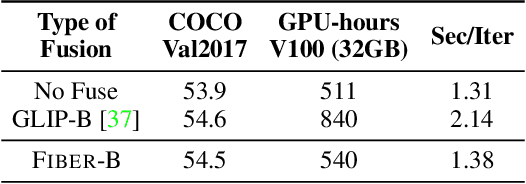
Vision-language (VL) pre-training has recently received considerable attention. However, most existing end-to-end pre-training approaches either only aim to tackle VL tasks such as image-text retrieval, visual question answering (VQA) and image captioning that test high-level understanding of images, or only target region-level understanding for tasks such as phrase grounding and object detection. We present FIBER (Fusion-In-the-Backbone-based transformER), a new VL model architecture that can seamlessly handle both these types of tasks. Instead of having dedicated transformer layers for fusion after the uni-modal backbones, FIBER pushes multimodal fusion deep into the model by inserting cross-attention into the image and text backbones, bringing gains in terms of memory and performance. In addition, unlike previous work that is either only pre-trained on image-text data or on fine-grained data with box-level annotations, we present a two-stage pre-training strategy that uses both these kinds of data efficiently: (i) coarse-grained pre-training based on image-text data; followed by (ii) fine-grained pre-training based on image-text-box data. We conduct comprehensive experiments on a wide range of VL tasks, ranging from VQA, image captioning, and retrieval, to phrase grounding, referring expression comprehension, and object detection. Using deep multimodal fusion coupled with the two-stage pre-training, FIBER provides consistent performance improvements over strong baselines across all tasks, often outperforming methods using magnitudes more data. Code is available at https://github.com/microsoft/FIBER.
Contrastive and Non-Contrastive Self-Supervised Learning Recover Global and Local Spectral Embedding Methods
May 26, 2022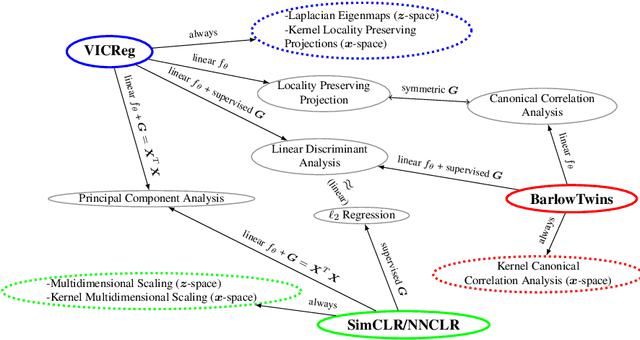
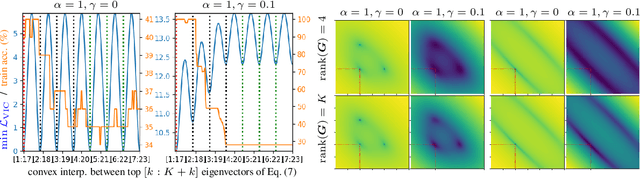
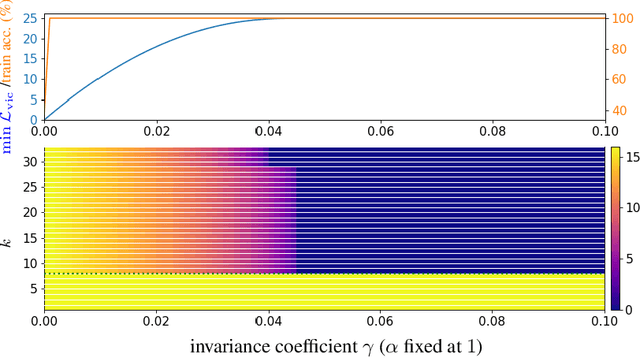
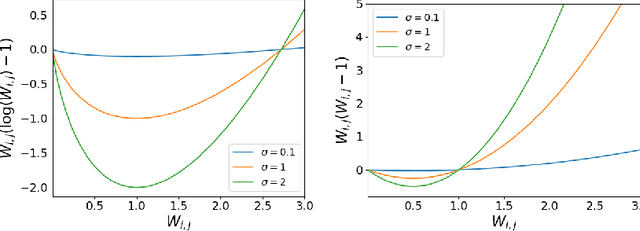
Self-Supervised Learning (SSL) surmises that inputs and pairwise positive relationships are enough to learn meaningful representations. Although SSL has recently reached a milestone: outperforming supervised methods in many modalities\dots the theoretical foundations are limited, method-specific, and fail to provide principled design guidelines to practitioners. In this paper, we propose a unifying framework under the helm of spectral manifold learning to address those limitations. Through the course of this study, we will rigorously demonstrate that VICReg, SimCLR, BarlowTwins et al. correspond to eponymous spectral methods such as Laplacian Eigenmaps, Multidimensional Scaling et al. This unification will then allow us to obtain (i) the closed-form optimal representation for each method, (ii) the closed-form optimal network parameters in the linear regime for each method, (iii) the impact of the pairwise relations used during training on each of those quantities and on downstream task performances, and most importantly, (iv) the first theoretical bridge between contrastive and non-contrastive methods towards global and local spectral embedding methods respectively, hinting at the benefits and limitations of each. For example, (i) if the pairwise relation is aligned with the downstream task, any SSL method can be employed successfully and will recover the supervised method, but in the low data regime, VICReg's invariance hyper-parameter should be high; (ii) if the pairwise relation is misaligned with the downstream task, VICReg with small invariance hyper-parameter should be preferred over SimCLR or BarlowTwins.
Pre-Train Your Loss: Easy Bayesian Transfer Learning with Informative Priors
May 20, 2022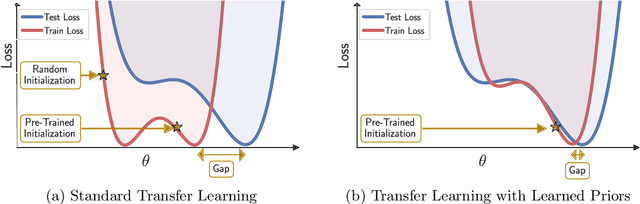

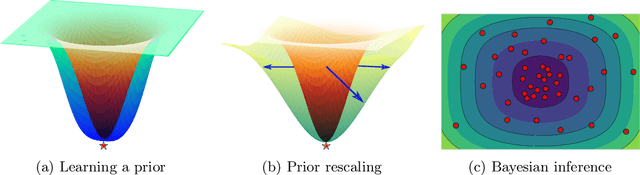
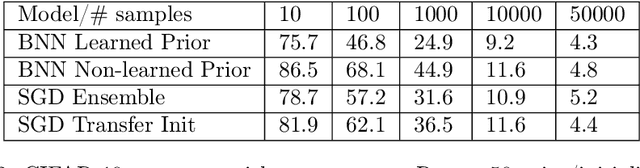
Deep learning is increasingly moving towards a transfer learning paradigm whereby large foundation models are fine-tuned on downstream tasks, starting from an initialization learned on the source task. But an initialization contains relatively little information about the source task. Instead, we show that we can learn highly informative posteriors from the source task, through supervised or self-supervised approaches, which then serve as the basis for priors that modify the whole loss surface on the downstream task. This simple modular approach enables significant performance gains and more data-efficient learning on a variety of downstream classification and segmentation tasks, serving as a drop-in replacement for standard pre-training strategies. These highly informative priors also can be saved for future use, similar to pre-trained weights, and stand in contrast to the zero-mean isotropic uninformative priors that are typically used in Bayesian deep learning.
Separating the World and Ego Models for Self-Driving
Apr 14, 2022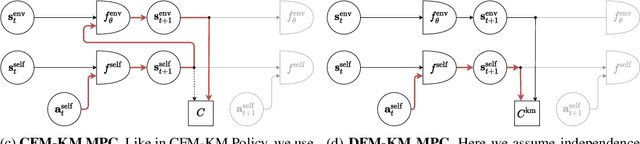

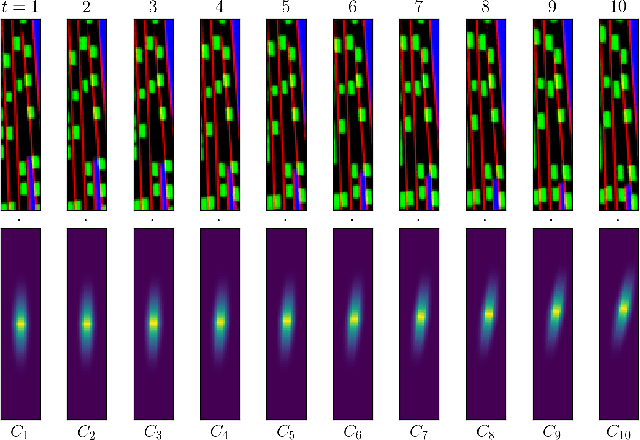
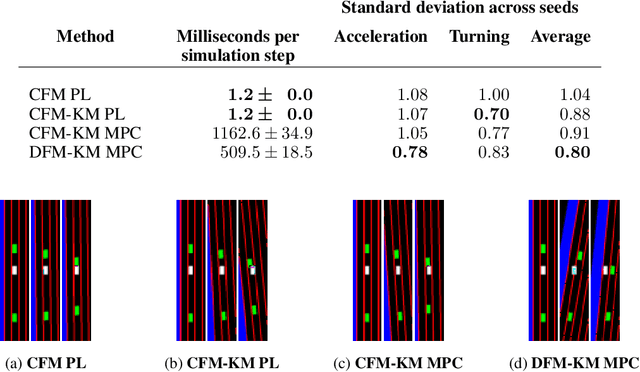
Training self-driving systems to be robust to the long-tail of driving scenarios is a critical problem. Model-based approaches leverage simulation to emulate a wide range of scenarios without putting users at risk in the real world. One promising path to faithful simulation is to train a forward model of the world to predict the future states of both the environment and the ego-vehicle given past states and a sequence of actions. In this paper, we argue that it is beneficial to model the state of the ego-vehicle, which often has simple, predictable and deterministic behavior, separately from the rest of the environment, which is much more complex and highly multimodal. We propose to model the ego-vehicle using a simple and differentiable kinematic model, while training a stochastic convolutional forward model on raster representations of the state to predict the behavior of the rest of the environment. We explore several configurations of such decoupled models, and evaluate their performance both with Model Predictive Control (MPC) and direct policy learning. We test our methods on the task of highway driving and demonstrate lower crash rates and better stability. The code is available at https://github.com/vladisai/pytorch-PPUU/tree/ICLR2022.
The Effects of Regularization and Data Augmentation are Class Dependent
Apr 08, 2022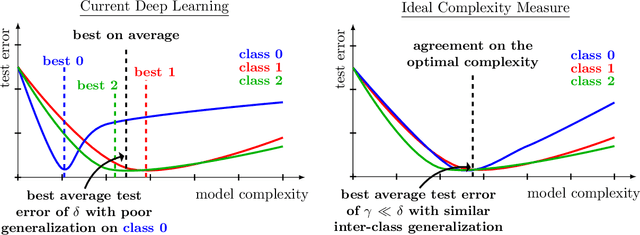
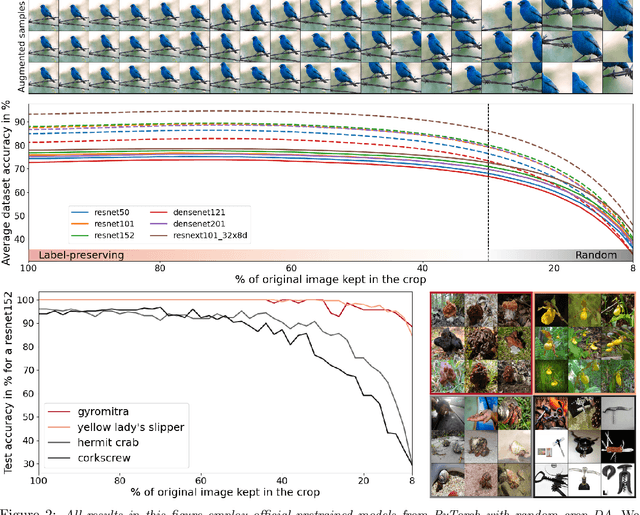
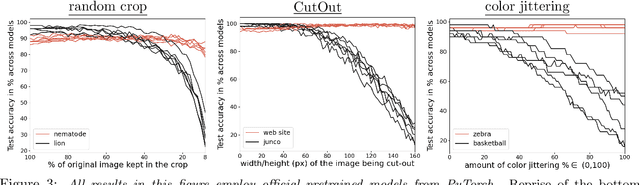
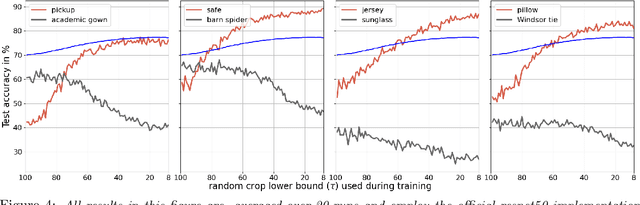
Regularization is a fundamental technique to prevent over-fitting and to improve generalization performances by constraining a model's complexity. Current Deep Networks heavily rely on regularizers such as Data-Augmentation (DA) or weight-decay, and employ structural risk minimization, i.e. cross-validation, to select the optimal regularization hyper-parameters. In this study, we demonstrate that techniques such as DA or weight decay produce a model with a reduced complexity that is unfair across classes. The optimal amount of DA or weight decay found from cross-validation leads to disastrous model performances on some classes e.g. on Imagenet with a resnet50, the "barn spider" classification test accuracy falls from $68\%$ to $46\%$ only by introducing random crop DA during training. Even more surprising, such performance drop also appears when introducing uninformative regularization techniques such as weight decay. Those results demonstrate that our search for ever increasing generalization performance -- averaged over all classes and samples -- has left us with models and regularizers that silently sacrifice performances on some classes. This scenario can become dangerous when deploying a model on downstream tasks e.g. an Imagenet pre-trained resnet50 deployed on INaturalist sees its performances fall from $70\%$ to $30\%$ on class \#8889 when introducing random crop DA during the Imagenet pre-training phase. Those results demonstrate that designing novel regularizers without class-dependent bias remains an open research question.
A Data-Augmentation Is Worth A Thousand Samples: Exact Quantification From Analytical Augmented Sample Moments
Feb 16, 2022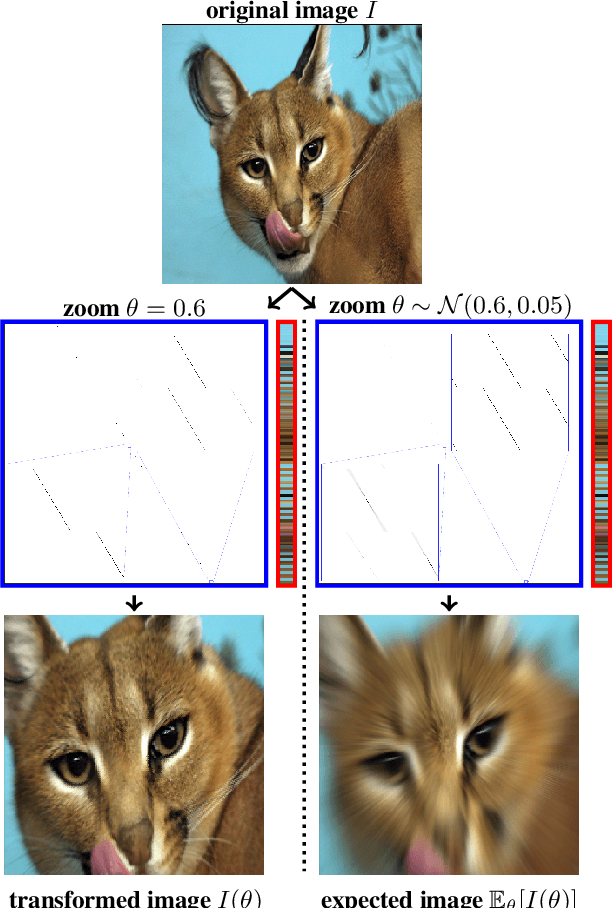
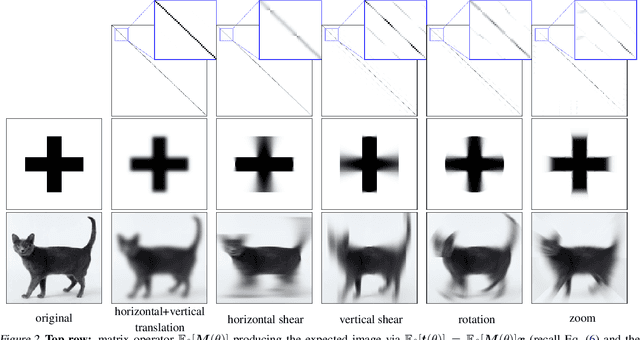
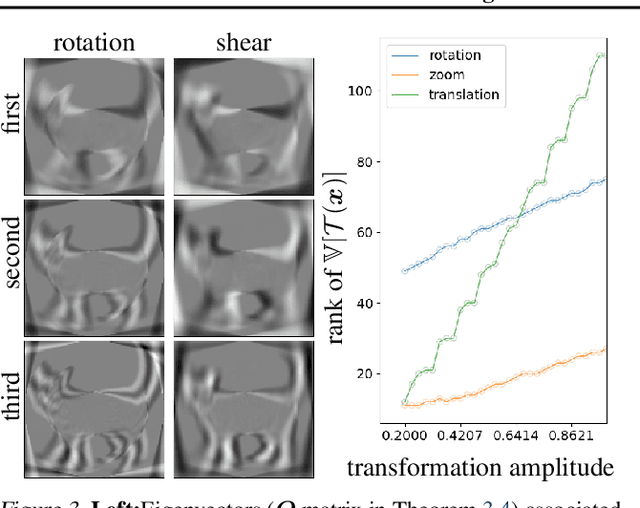
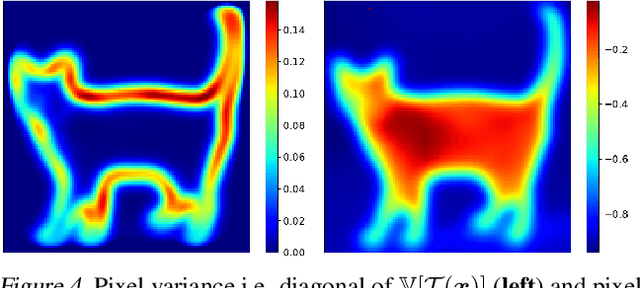
Data-Augmentation (DA) is known to improve performance across tasks and datasets. We propose a method to theoretically analyze the effect of DA and study questions such as: how many augmented samples are needed to correctly estimate the information encoded by that DA? How does the augmentation policy impact the final parameters of a model? We derive several quantities in close-form, such as the expectation and variance of an image, loss, and model's output under a given DA distribution. Those derivations open new avenues to quantify the benefits and limitations of DA. For example, we show that common DAs require tens of thousands of samples for the loss at hand to be correctly estimated and for the model training to converge. We show that for a training loss to be stable under DA sampling, the model's saliency map (gradient of the loss with respect to the model's input) must align with the smallest eigenvector of the sample variance under the considered DA augmentation, hinting at a possible explanation on why models tend to shift their focus from edges to textures.
Neural Manifold Clustering and Embedding
Jan 24, 2022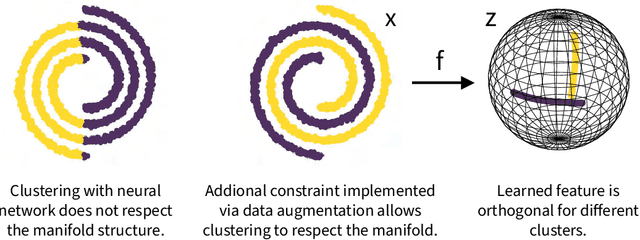



Given a union of non-linear manifolds, non-linear subspace clustering or manifold clustering aims to cluster data points based on manifold structures and also learn to parameterize each manifold as a linear subspace in a feature space. Deep neural networks have the potential to achieve this goal under highly non-linear settings given their large capacity and flexibility. We argue that achieving manifold clustering with neural networks requires two essential ingredients: a domain-specific constraint that ensures the identification of the manifolds, and a learning algorithm for embedding each manifold to a linear subspace in the feature space. This work shows that many constraints can be implemented by data augmentation. For subspace feature learning, Maximum Coding Rate Reduction (MCR$^2$) objective can be used. Putting them together yields {\em Neural Manifold Clustering and Embedding} (NMCE), a novel method for general purpose manifold clustering, which significantly outperforms autoencoder-based deep subspace clustering. Further, on more challenging natural image datasets, NMCE can also outperform other algorithms specifically designed for clustering. Qualitatively, we demonstrate that NMCE learns a meaningful and interpretable feature space. As the formulation of NMCE is closely related to several important Self-supervised learning (SSL) methods, we believe this work can help us build a deeper understanding on SSL representation learning.
Sparse Coding with Multi-Layer Decoders using Variance Regularization
Dec 16, 2021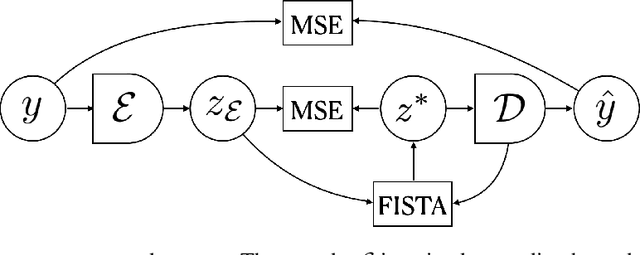
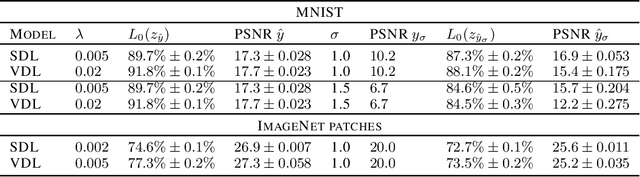


Sparse coding with an $l_1$ penalty and a learned linear dictionary requires regularization of the dictionary to prevent a collapse in the $l_1$ norms of the codes. Typically, this regularization entails bounding the Euclidean norms of the dictionary's elements. In this work, we propose a novel sparse coding protocol which prevents a collapse in the codes without the need to regularize the decoder. Our method regularizes the codes directly so that each latent code component has variance greater than a fixed threshold over a set of sparse representations for a given set of inputs. Furthermore, we explore ways to effectively train sparse coding systems with multi-layer decoders since they can model more complex relationships than linear dictionaries. In our experiments with MNIST and natural image patches, we show that decoders learned with our approach have interpretable features both in the linear and multi-layer case. Moreover, we show that sparse autoencoders with multi-layer decoders trained using our variance regularization method produce higher quality reconstructions with sparser representations when compared to autoencoders with linear dictionaries. Additionally, sparse representations obtained with our variance regularization approach are useful in the downstream tasks of denoising and classification in the low-data regime.