 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
First-place Solution for Streetscape Shop Sign Recognition Competition
Jan 06, 2025Text recognition technology applied to street-view storefront signs is increasingly utilized across various practical domains, including map navigation, smart city planning analysis, and business value assessments in commercial districts. This technology holds significant research and commercial potential. Nevertheless, it faces numerous challenges. Street view images often contain signboards with complex designs and diverse text styles, complicating the text recognition process. A notable advancement in this field was introduced by our team in a recent competition. We developed a novel multistage approach that integrates multimodal feature fusion, extensive self-supervised training, and a Transformer-based large model. Furthermore, innovative techniques such as BoxDQN, which relies on reinforcement learning, and text rectification methods were employed, leading to impressive outcomes. Comprehensive experiments have validated the effectiveness of these methods, showcasing our potential to enhance text recognition capabilities in complex urban environments.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
VoLTA: Vision-Language Transformer with Weakly-Supervised Local-Feature Alignment
Oct 09, 2022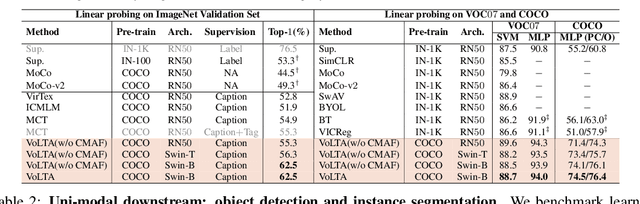
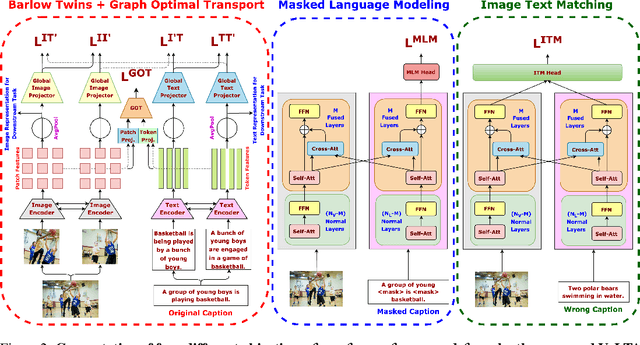
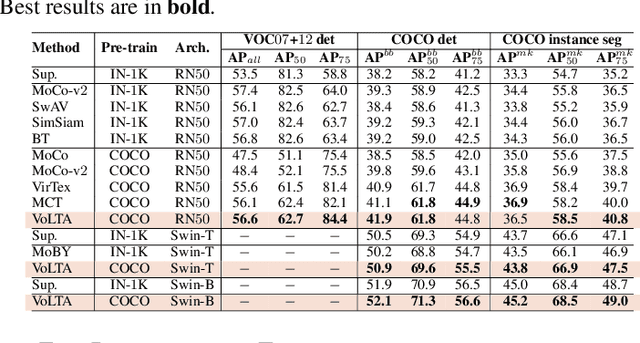

Vision-language pre-training (VLP) has recently proven highly effective for various uni- and multi-modal downstream applications. However, most existing end-to-end VLP methods use high-resolution image-text box data to perform well on fine-grained region-level tasks, such as object detection, segmentation, and referring expression comprehension. Unfortunately, such high-resolution images with accurate bounding box annotations are expensive to collect and use for supervision at scale. In this work, we propose VoLTA (Vision-Language Transformer with weakly-supervised local-feature Alignment), a new VLP paradigm that only utilizes image-caption data but achieves fine-grained region-level image understanding, eliminating the use of expensive box annotations. VoLTA adopts graph optimal transport-based weakly-supervised alignment on local image patches and text tokens to germinate an explicit, self-normalized, and interpretable low-level matching criterion. In addition, VoLTA pushes multi-modal fusion deep into the uni-modal backbones during pre-training and removes fusion-specific transformer layers, further reducing memory requirements. Extensive experiments on a wide range of vision- and vision-language downstream tasks demonstrate the effectiveness of VoLTA on fine-grained applications without compromising the coarse-grained downstream performance, often outperforming methods using significantly more caption and box annotations.
MSA-GCN:Multiscale Adaptive Graph Convolution Network for Gait Emotion Recognition
Sep 19, 2022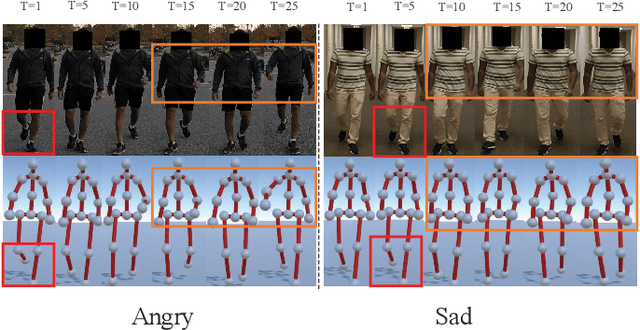
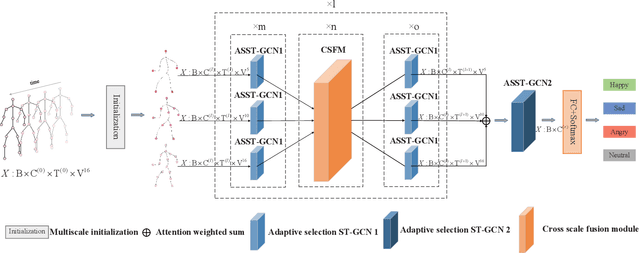
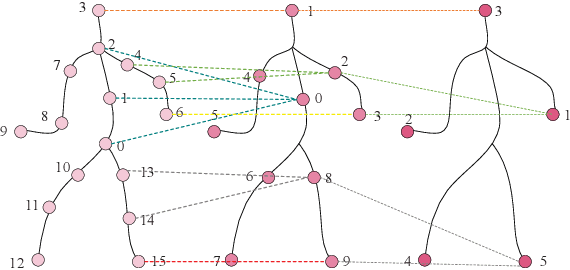
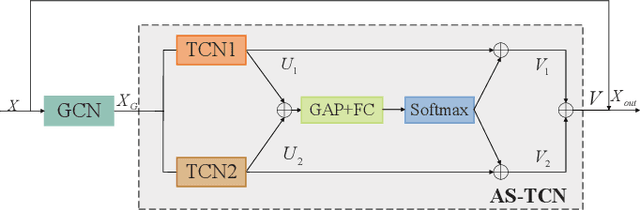
Gait emotion recognition plays a crucial role in the intelligent system. Most of the existing methods recognize emotions by focusing on local actions over time. However, they ignore that the effective distances of different emotions in the time domain are different, and the local actions during walking are quite similar. Thus, emotions should be represented by global states instead of indirect local actions. To address these issues, a novel Multi Scale Adaptive Graph Convolution Network (MSA-GCN) is presented in this work through constructing dynamic temporal receptive fields and designing multiscale information aggregation to recognize emotions. In our model, a adaptive selective spatial-temporal graph convolution is designed to select the convolution kernel dynamically to obtain the soft spatio-temporal features of different emotions. Moreover, a Cross-Scale mapping Fusion Mechanism (CSFM) is designed to construct an adaptive adjacency matrix to enhance information interaction and reduce redundancy. Compared with previous state-of-the-art methods, the proposed method achieves the best performance on two public datasets, improving the mAP by 2\%. We also conduct extensive ablations studies to show the effectiveness of different components in our methods.
Masked Siamese ConvNets
Jun 15, 2022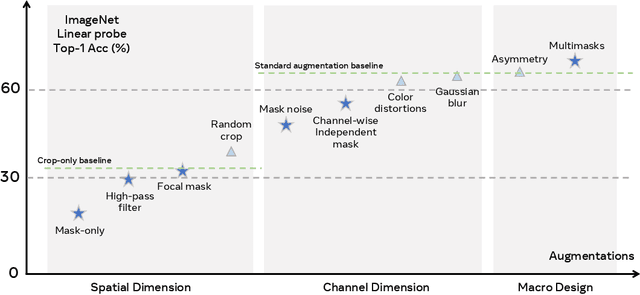
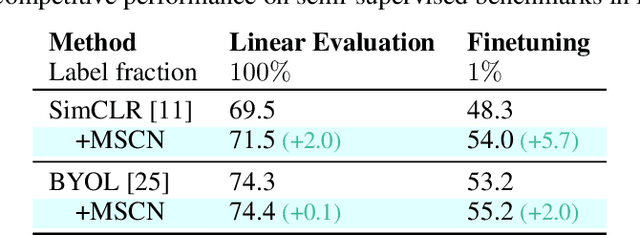

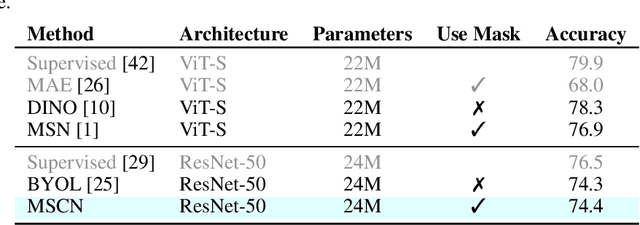
Self-supervised learning has shown superior performances over supervised methods on various vision benchmarks. The siamese network, which encourages embeddings to be invariant to distortions, is one of the most successful self-supervised visual representation learning approaches. Among all the augmentation methods, masking is the most general and straightforward method that has the potential to be applied to all kinds of input and requires the least amount of domain knowledge. However, masked siamese networks require particular inductive bias and practically only work well with Vision Transformers. This work empirically studies the problems behind masked siamese networks with ConvNets. We propose several empirical designs to overcome these problems gradually. Our method performs competitively on low-shot image classification and outperforms previous methods on object detection benchmarks. We discuss several remaining issues and hope this work can provide useful data points for future general-purpose self-supervised learning.
Positive Unlabeled Contrastive Learning
Jun 01, 2022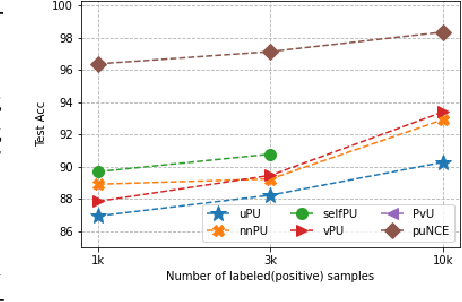
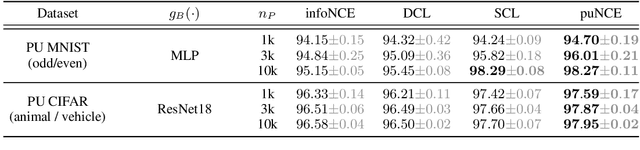
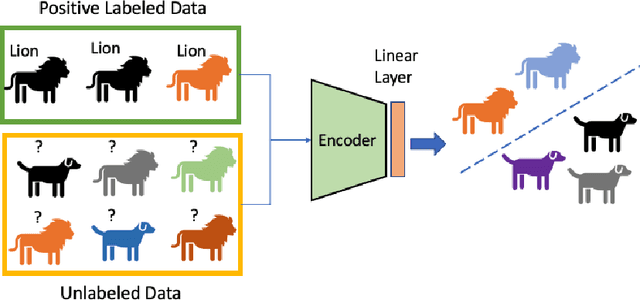
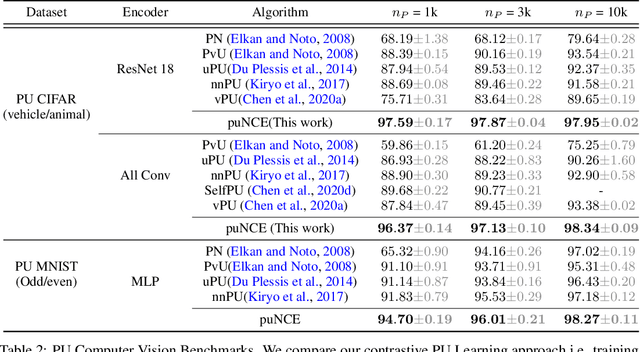
Self-supervised pretraining on unlabeled data followed by supervised finetuning on labeled data is a popular paradigm for learning from limited labeled examples. In this paper, we investigate and extend this paradigm to the classical positive unlabeled (PU) setting - the weakly supervised task of learning a binary classifier only using a few labeled positive examples and a set of unlabeled samples. We propose a novel PU learning objective positive unlabeled Noise Contrastive Estimation (puNCE) that leverages the available explicit (from labeled samples) and implicit (from unlabeled samples) supervision to learn useful representations from positive unlabeled input data. The underlying idea is to assign each training sample an individual weight; labeled positives are given unit weight; unlabeled samples are duplicated, one copy is labeled positive and the other as negative with weights $\pi$ and $(1-\pi)$ where $\pi$ denotes the class prior. Extensive experiments across vision and natural language tasks reveal that puNCE consistently improves over existing unsupervised and supervised contrastive baselines under limited supervision.
Topogivity: A Machine-Learned Chemical Rule for Discovering Topological Materials
Mar 02, 2022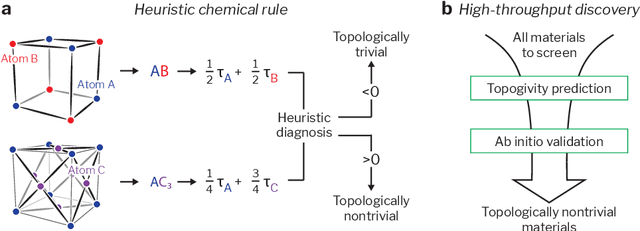
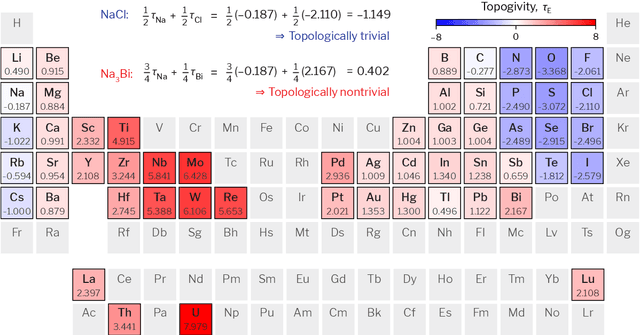
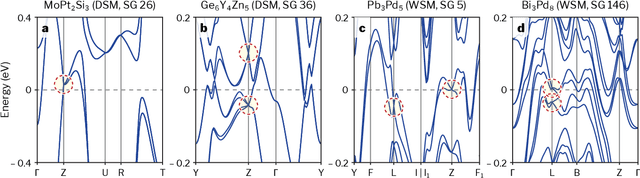
Topological materials present unconventional electronic properties that make them attractive for both basic science and next-generation technological applications. The majority of currently-known topological materials have been discovered using methods that involve symmetry-based analysis of the quantum wavefunction. Here we use machine learning to develop a simple-to-use heuristic chemical rule that diagnoses with a high accuracy whether a material is topological using only its chemical formula. This heuristic rule is based on a notion that we term topogivity, a machine-learned numerical value for each element that loosely captures its tendency to form topological materials. We next implement a high-throughput strategy for discovering topological materials based on the heuristic topogivity-rule prediction followed by ab initio validation. This way, we discover new topological materials that are not diagnosable using symmetry indicators, including several that may be promising for experimental observation.
Equivariant Contrastive Learning
Oct 28, 2021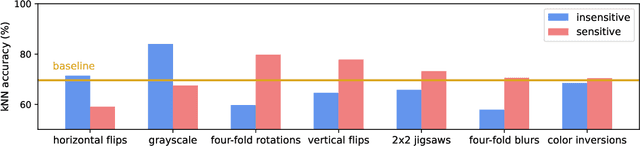
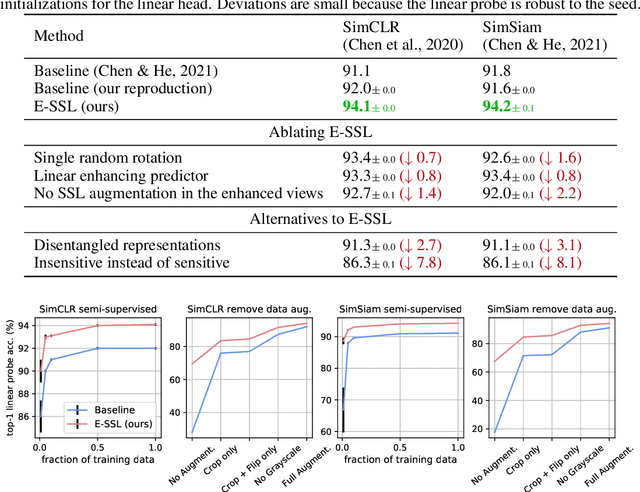


In state-of-the-art self-supervised learning (SSL) pre-training produces semantically good representations by encouraging them to be invariant under meaningful transformations prescribed from human knowledge. In fact, the property of invariance is a trivial instance of a broader class called equivariance, which can be intuitively understood as the property that representations transform according to the way the inputs transform. Here, we show that rather than using only invariance, pre-training that encourages non-trivial equivariance to some transformations, while maintaining invariance to other transformations, can be used to improve the semantic quality of representations. Specifically, we extend popular SSL methods to a more general framework which we name Equivariant Self-Supervised Learning (E-SSL). In E-SSL, a simple additional pre-training objective encourages equivariance by predicting the transformations applied to the input. We demonstrate E-SSL's effectiveness empirically on several popular computer vision benchmarks. Furthermore, we demonstrate usefulness of E-SSL for applications beyond computer vision; in particular, we show its utility on regression problems in photonics science. We will release our code.
Understanding Dimensional Collapse in Contrastive Self-supervised Learning
Oct 18, 2021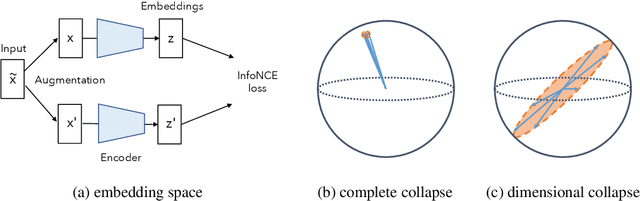

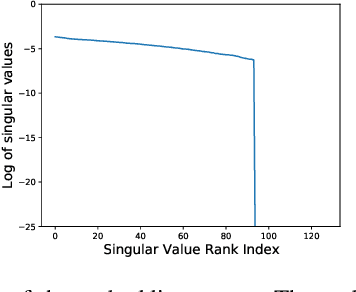
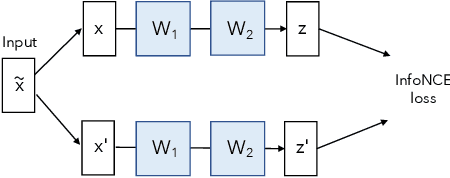
Self-supervised visual representation learning aims to learn useful representations without relying on human annotations. Joint embedding approach bases on maximizing the agreement between embedding vectors from different views of the same image. Various methods have been proposed to solve the collapsing problem where all embedding vectors collapse to a trivial constant solution. Among these methods, contrastive learning prevents collapse via negative sample pairs. It has been shown that non-contrastive methods suffer from a lesser collapse problem of a different nature: dimensional collapse, whereby the embedding vectors end up spanning a lower-dimensional subspace instead of the entire available embedding space. Here, we show that dimensional collapse also happens in contrastive learning. In this paper, we shed light on the dynamics at play in contrastive learning that leads to dimensional collapse. Inspired by our theory, we propose a novel contrastive learning method, called DirectCLR, which directly optimizes the representation space without relying on a trainable projector. Experiments show that DirectCLR outperforms SimCLR with a trainable linear projector on ImageNet.