 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeaPA: Difficulty-Aware Heap Sampling and On-Policy Query Augmentation for LLM Reinforcement Learning
Jan 30, 2026RLVR is now a standard way to train LLMs on reasoning tasks with verifiable outcomes, but when rollout generation dominates the cost, efficiency depends heavily on which prompts you sample and when. In practice, prompt pools are often static or only loosely tied to the model's learning progress, so uniform sampling can't keep up with the shifting capability frontier and ends up wasting rollouts on prompts that are already solved or still out of reach. Existing approaches improve efficiency through filtering, curricula, adaptive rollout allocation, or teacher guidance, but they typically assume a fixed pool-which makes it hard to support stable on-policy pool growth-or they add extra teacher cost and latency. We introduce HeaPA (Heap Sampling and On-Policy Query Augmentation), which maintains a bounded, evolving pool, tracks the frontier using heap-based boundary sampling, expands the pool via on-policy augmentation with lightweight asynchronous validation, and stabilizes correlated queries through topology-aware re-estimation of pool statistics and controlled reinsertion. Across two training corpora, two training recipes, and seven benchmarks, HeaPA consistently improves accuracy and reaches target performance with fewer computations while keeping wall-clock time comparable. Our analyses suggest these gains come from frontier-focused sampling and on-policy pool growth, with the benefits becoming larger as model scale increases. Our code is available at https://github.com/horizon-rl/HeaPA.
$\mathbb{R}^{2k}$ is Theoretically Large Enough for Embedding-based Top-$k$ Retrieval
Jan 29, 2026This paper studies the minimal dimension required to embed subset memberships ($m$ elements and ${m\choose k}$ subsets of at most $k$ elements) into vector spaces, denoted as Minimal Embeddable Dimension (MED). The tight bounds of MED are derived theoretically and supported empirically for various notions of "distances" or "similarities," including the $\ell_2$ metric, inner product, and cosine similarity. In addition, we conduct numerical simulation in a more achievable setting, where the ${m\choose k}$ subset embeddings are chosen as the centroid of the embeddings of the contained elements. Our simulation easily realizes a logarithmic dependency between the MED and the number of elements to embed. These findings imply that embedding-based retrieval limitations stem primarily from learnability challenges, not geometric constraints, guiding future algorithm design.
Do Reasoning Models Enhance Embedding Models?
Jan 29, 2026State-of-the-art embedding models are increasingly derived from decoder-only Large Language Model (LLM) backbones adapted via contrastive learning. Given the emergence of reasoning models trained via Reinforcement Learning with Verifiable Rewards (RLVR), a natural question arises: do enhanced reasoning translate to superior semantic representations when these models serve as embedding initializations? Contrary to expectation, our evaluation on MTEB and BRIGHT reveals a **null effect**: embedding models initialized from RLVR-tuned backbones yield no consistent performance advantage over their base counterparts when subjected to identical training recipes. To unpack this paradox, we introduce **H**ierarchical **R**epresentation **S**imilarity **A**nalysis (HRSA), a framework that decomposes similarity across representation, geometry, and function levels. HRSA reveals that while RLVR induces irreversible latent manifold's local geometry reorganization and reversible coordinate basis drift, it preserves the global manifold geometry and linear readout. Consequently, subsequent contrastive learning drives strong alignment between base- and reasoning-initialized models, a phenomenon we term **Manifold Realignment**. Empirically, our findings suggest that unlike Supervised Fine-Tuning (SFT), RLVR optimizes trajectories within an existing semantic landscape rather than fundamentally restructuring the landscape itself.
NAACL: Noise-AwAre Verbal Confidence Calibration for LLMs in RAG Systems
Jan 16, 2026Accurately assessing model confidence is essential for deploying large language models (LLMs) in mission-critical factual domains. While retrieval-augmented generation (RAG) is widely adopted to improve grounding, confidence calibration in RAG settings remains poorly understood. We conduct a systematic study across four benchmarks, revealing that LLMs exhibit poor calibration performance due to noisy retrieved contexts. Specifically, contradictory or irrelevant evidence tends to inflate the model's false certainty, leading to severe overconfidence. To address this, we propose NAACL Rules (Noise-AwAre Confidence CaLibration Rules) to provide a principled foundation for resolving overconfidence under noise. We further design NAACL, a noise-aware calibration framework that synthesizes supervision from about 2K HotpotQA examples guided by these rules. By performing supervised fine-tuning (SFT) with this data, NAACL equips models with intrinsic noise awareness without relying on stronger teacher models. Empirical results show that NAACL yields substantial gains, improving ECE scores by 10.9% in-domain and 8.0% out-of-domain. By bridging the gap between retrieval noise and verbal calibration, NAACL paves the way for both accurate and epistemically reliable LLMs.
NewtonBench: Benchmarking Generalizable Scientific Law Discovery in LLM Agents
Oct 08, 2025Large language models are emerging as powerful tools for scientific law discovery, a foundational challenge in AI-driven science. However, existing benchmarks for this task suffer from a fundamental methodological trilemma, forcing a trade-off between scientific relevance, scalability, and resistance to memorization. Furthermore, they oversimplify discovery as static function fitting, failing to capture the authentic scientific process of uncovering embedded laws through the interactive exploration of complex model systems. To address these critical gaps, we introduce NewtonBench, a benchmark comprising 324 scientific law discovery tasks across 12 physics domains. Our design mitigates the evaluation trilemma by using metaphysical shifts - systematic alterations of canonical laws - to generate a vast suite of problems that are scalable, scientifically relevant, and memorization-resistant. Moreover, we elevate the evaluation from static function fitting to interactive model discovery, requiring agents to experimentally probe simulated complex systems to uncover hidden principles. Our extensive experiment reveals a clear but fragile capability for discovery in frontier LLMs: this ability degrades precipitously with increasing system complexity and exhibits extreme sensitivity to observational noise. Notably, we uncover a paradoxical effect of tool assistance: providing a code interpreter can hinder more capable models by inducing a premature shift from exploration to exploitation, causing them to satisfice on suboptimal solutions. These results demonstrate that robust, generalizable discovery in complex, interactive environments remains the core challenge. By providing a scalable, robust, and scientifically authentic testbed, NewtonBench offers a crucial tool for measuring true progress and guiding the development of next-generation AI agents capable of genuine scientific discovery.
The Cognitive Bandwidth Bottleneck: Shifting Long-Horizon Agent from Planning with Actions to Planning with Schemas
Oct 08, 2025Enabling LLMs to effectively operate long-horizon task which requires long-term planning and multiple interactions is essential for open-world autonomy. Conventional methods adopt planning with actions where a executable action list would be provided as reference. However, this action representation choice would be impractical when the environment action space is combinatorial exploded (e.g., open-ended real world). This naturally leads to a question: As environmental action space scales, what is the optimal action representation for long-horizon agents? In this paper, we systematically study the effectiveness of two different action representations. The first one is conventional planning with actions (PwA) which is predominantly adopted for its effectiveness on existing benchmarks. The other one is planning with schemas (PwS) which instantiate an action schema into action lists (e.g., "move [OBJ] to [OBJ]" -> "move apple to desk") to ensure concise action space and reliable scalability. This alternative is motivated by its alignment with human cognition and its compliance with environment-imposed action format restriction. We propose cognitive bandwidth perspective as a conceptual framework to qualitatively understand the differences between these two action representations and empirically observe a representation-choice inflection point between ALFWorld (~35 actions) and SciWorld (~500 actions), which serve as evidence of the need for scalable representations. We further conduct controlled experiments to study how the location of this inflection point interacts with different model capacities: stronger planning proficiency shifts the inflection rightward, whereas better schema instantiation shifts it leftward. Finally, noting the suboptimal performance of PwS agents, we provide an actionable guide for building more capable PwS agents for better scalable autonomy.
LLM-Hanabi: Evaluating Multi-Agent Gameplays with Theory-of-Mind and Rationale Inference in Imperfect Information Collaboration Game
Oct 06, 2025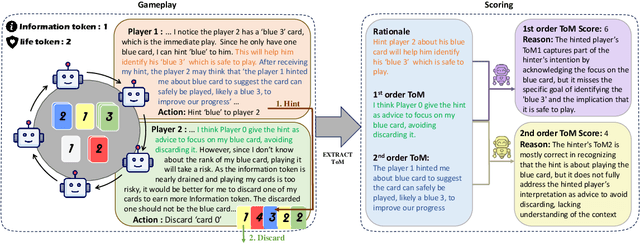
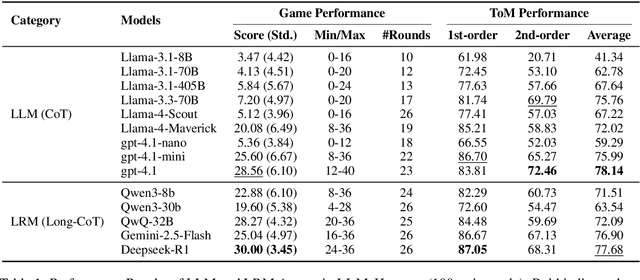
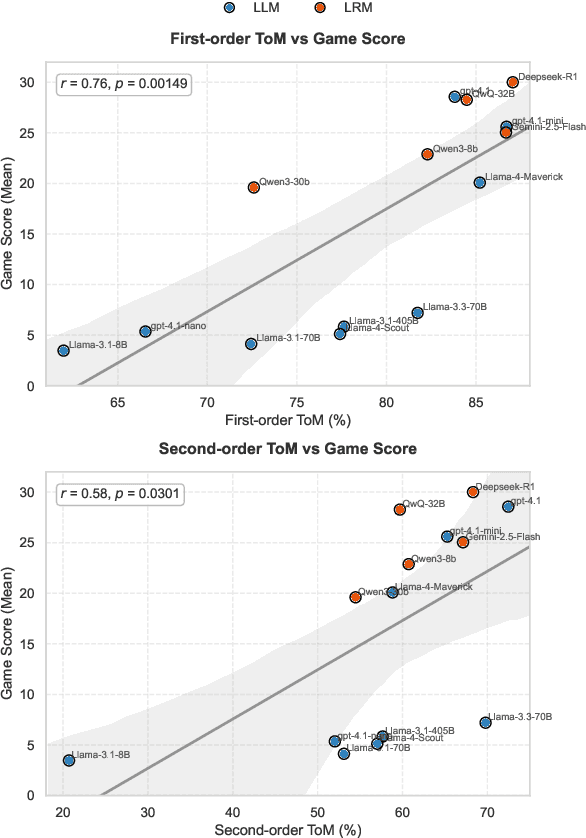
Effective multi-agent collaboration requires agents to infer the rationale behind others' actions, a capability rooted in Theory-of-Mind (ToM). While recent Large Language Models (LLMs) excel at logical inference, their ability to infer rationale in dynamic, collaborative settings remains under-explored. This study introduces LLM-Hanabi, a novel benchmark that uses the cooperative game Hanabi to evaluate the rationale inference and ToM of LLMs. Our framework features an automated evaluation system that measures both game performance and ToM proficiency. Across a range of models, we find a significant positive correlation between ToM and in-game success. Notably, first-order ToM (interpreting others' intent) correlates more strongly with performance than second-order ToM (predicting others' interpretations). These findings highlight that for effective AI collaboration, the ability to accurately interpret a partner's rationale is more critical than higher-order reasoning. We conclude that prioritizing first-order ToM is a promising direction for enhancing the collaborative capabilities of future models.
Safety Compliance: Rethinking LLM Safety Reasoning through the Lens of Compliance
Sep 26, 2025The proliferation of Large Language Models (LLMs) has demonstrated remarkable capabilities, elevating the critical importance of LLM safety. However, existing safety methods rely on ad-hoc taxonomy and lack a rigorous, systematic protection, failing to ensure safety for the nuanced and complex behaviors of modern LLM systems. To address this problem, we solve LLM safety from legal compliance perspectives, named safety compliance. In this work, we posit relevant established legal frameworks as safety standards for defining and measuring safety compliance, including the EU AI Act and GDPR, which serve as core legal frameworks for AI safety and data security in Europe. To bridge the gap between LLM safety and legal compliance, we first develop a new benchmark for safety compliance by generating realistic LLM safety scenarios seeded with legal statutes. Subsequently, we align Qwen3-8B using Group Policy Optimization (GRPO) to construct a safety reasoner, Compliance Reasoner, which effectively aligns LLMs with legal standards to mitigate safety risks. Our comprehensive experiments demonstrate that the Compliance Reasoner achieves superior performance on the new benchmark, with average improvements of +10.45% for the EU AI Act and +11.85% for GDPR.
Structuring the Unstructured: A Systematic Review of Text-to-Structure Generation for Agentic AI with a Universal Evaluation Framework
Aug 17, 2025



The evolution of AI systems toward agentic operation and context-aware retrieval necessitates transforming unstructured text into structured formats like tables, knowledge graphs, and charts. While such conversions enable critical applications from summarization to data mining, current research lacks a comprehensive synthesis of methodologies, datasets, and metrics. This systematic review examines text-to-structure techniques and the encountered challenges, evaluates current datasets and assessment criteria, and outlines potential directions for future research. We also introduce a universal evaluation framework for structured outputs, establishing text-to-structure as foundational infrastructure for next-generation AI systems.
Prospect Theory Fails for LLMs: Revealing Instability of Decision-Making under Epistemic Uncertainty
Aug 12, 2025



Prospect Theory (PT) models human decision-making under uncertainty, while epistemic markers (e.g., maybe) serve to express uncertainty in language. However, it remains largely unexplored whether Prospect Theory applies to contemporary Large Language Models and whether epistemic markers, which express human uncertainty, affect their decision-making behaviour. To address these research gaps, we design a three-stage experiment based on economic questionnaires. We propose a more general and precise evaluation framework to model LLMs' decision-making behaviour under PT, introducing uncertainty through the empirical probability values associated with commonly used epistemic markers in comparable contexts. We then incorporate epistemic markers into the evaluation framework based on their corresponding probability values to examine their influence on LLM decision-making behaviours. Our findings suggest that modelling LLMs' decision-making with PT is not consistently reliable, particularly when uncertainty is expressed in diverse linguistic forms. Our code is released in https://github.com/HKUST-KnowComp/MarPT.