 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINO-BOLDNet: A DINOv3-Guided Multi-Slice Attention Network for T1-to-BOLD Generation
Dec 09, 2025



Generating BOLD images from T1w images offers a promising solution for recovering missing BOLD information and enabling downstream tasks when BOLD images are corrupted or unavailable. Motivated by this, we propose DINO-BOLDNet, a DINOv3-guided multi-slice attention framework that integrates a frozen self-supervised DINOv3 encoder with a lightweight trainable decoder. The model uses DINOv3 to extract within-slice structural representations, and a separate slice-attention module to fuse contextual information across neighboring slices. A multi-scale generation decoder then restores fine-grained functional contrast, while a DINO-based perceptual loss encourages structural and textural consistency between predictions and ground-truth BOLD in the transformer feature space. Experiments on a clinical dataset of 248 subjects show that DINO-BOLDNet surpasses a conditional GAN baseline in both PSNR and MS-SSIM. To our knowledge, this is the first framework capable of generating mean BOLD images directly from T1w images, highlighting the potential of self-supervised transformer guidance for structural-to-functional mapping.
Learning by Neighbor-Aware Semantics, Deciding by Open-form Flows: Towards Robust Zero-Shot Skeleton Action Recognition
Nov 12, 2025Recognizing unseen skeleton action categories remains highly challenging due to the absence of corresponding skeletal priors. Existing approaches generally follow an "align-then-classify" paradigm but face two fundamental issues, i.e., (i) fragile point-to-point alignment arising from imperfect semantics, and (ii) rigid classifiers restricted by static decision boundaries and coarse-grained anchors. To address these issues, we propose a novel method for zero-shot skeleton action recognition, termed $\texttt{$\textbf{Flora}$}$, which builds upon $\textbf{F}$lexib$\textbf{L}$e neighb$\textbf{O}$r-aware semantic attunement and open-form dist$\textbf{R}$ibution-aware flow cl$\textbf{A}$ssifier. Specifically, we flexibly attune textual semantics by incorporating neighboring inter-class contextual cues to form direction-aware regional semantics, coupled with a cross-modal geometric consistency objective that ensures stable and robust point-to-region alignment. Furthermore, we employ noise-free flow matching to bridge the modality distribution gap between semantic and skeleton latent embeddings, while a condition-free contrastive regularization enhances discriminability, leading to a distribution-aware classifier with fine-grained decision boundaries achieved through token-level velocity predictions. Extensive experiments on three benchmark datasets validate the effectiveness of our method, showing particularly impressive performance even when trained with only 10\% of the seen data. Code is available at https://github.com/cseeyangchen/Flora.
Chain-of-Thought Re-ranking for Image Retrieval Tasks
Sep 18, 2025



Image retrieval remains a fundamental yet challenging problem in computer vision. While recent advances in Multimodal Large Language Models (MLLMs) have demonstrated strong reasoning capabilities, existing methods typically employ them only for evaluation, without involving them directly in the ranking process. As a result, their rich multimodal reasoning abilities remain underutilized, leading to suboptimal performance. In this paper, we propose a novel Chain-of-Thought Re-Ranking (CoTRR) method to address this issue. Specifically, we design a listwise ranking prompt that enables MLLM to directly participate in re-ranking candidate images. This ranking process is grounded in an image evaluation prompt, which assesses how well each candidate aligns with users query. By allowing MLLM to perform listwise reasoning, our method supports global comparison, consistent reasoning, and interpretable decision-making - all of which are essential for accurate image retrieval. To enable structured and fine-grained analysis, we further introduce a query deconstruction prompt, which breaks down the original query into multiple semantic components. Extensive experiments on five datasets demonstrate the effectiveness of our CoTRR method, which achieves state-of-the-art performance across three image retrieval tasks, including text-to-image retrieval (TIR), composed image retrieval (CIR) and chat-based image retrieval (Chat-IR). Our code is available at https://github.com/freshfish15/CoTRR .
Kalman Filtering of Stationary Graph Signals
Sep 16, 2025In this paper, we propose a novel definition of stationary graph signals, formulated with respect to a symmetric graph shift, such as the graph Laplacian. We show that stationary graph signals can be generated by transmitting white noise through polynomial graph channels, and that their stationarity is preserved under polynomial channel transmission. In this paper, we also investigate Kalman filtering to dynamical systems characterized by polynomial state and observation matrices. We demonstrate that Kalman filtering maintains the stationarity of graph signals, while effectively incorporating both system dynamics and noise structure. In comparison to the static inverse filtering method and naive zero-signal strategy, the Kalman filtering procedure yields more accurate and adaptive signal estimates, highlighting its robustness and versatility in graph signal processing.
Meta-Inverse Reinforcement Learning for Mean Field Games via Probabilistic Context Variables
Sep 04, 2025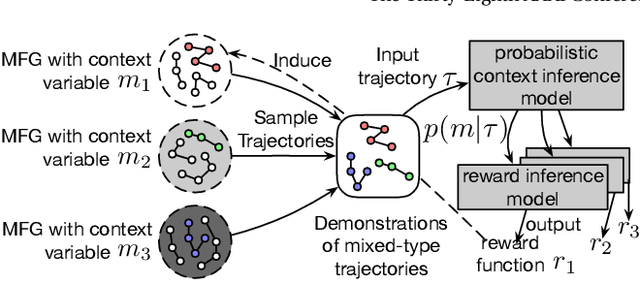
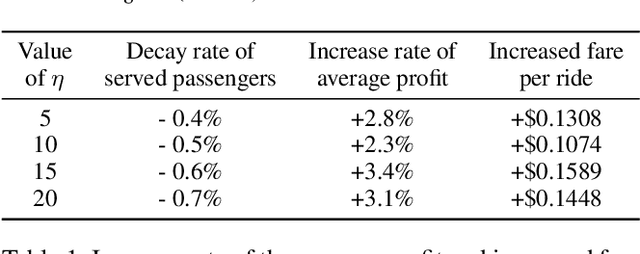
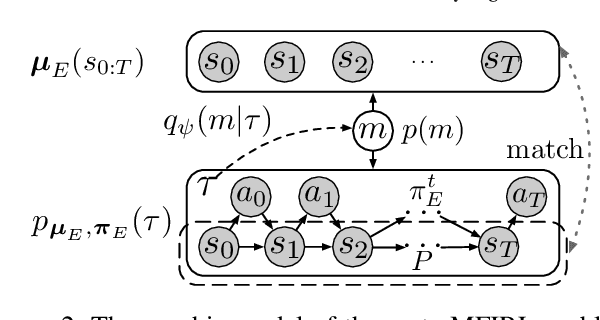
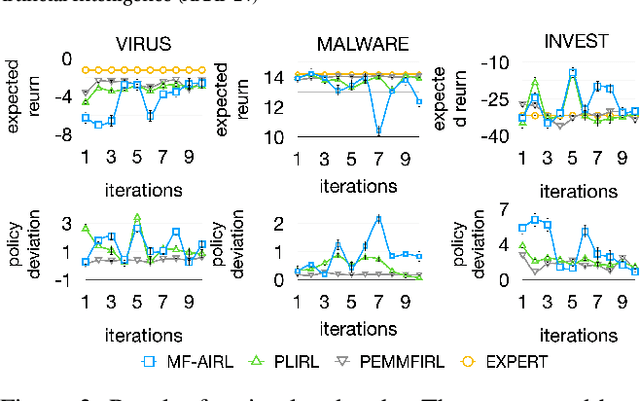
Designing suitable reward functions for numerous interacting intelligent agents is challenging in real-world applications. Inverse reinforcement learning (IRL) in mean field games (MFGs) offers a practical framework to infer reward functions from expert demonstrations. While promising, the assumption of agent homogeneity limits the capability of existing methods to handle demonstrations with heterogeneous and unknown objectives, which are common in practice. To this end, we propose a deep latent variable MFG model and an associated IRL method. Critically, our method can infer rewards from different yet structurally similar tasks without prior knowledge about underlying contexts or modifying the MFG model itself. Our experiments, conducted on simulated scenarios and a real-world spatial taxi-ride pricing problem, demonstrate the superiority of our approach over state-of-the-art IRL methods in MFGs.
Alternating Training-based Label Smoothing Enhances Prompt Generalization
Aug 25, 2025



Recent advances in pre-trained vision-language models have demonstrated remarkable zero-shot generalization capabilities. To further enhance these models' adaptability to various downstream tasks, prompt tuning has emerged as a parameter-efficient fine-tuning method. However, despite its efficiency, the generalization ability of prompt remains limited. In contrast, label smoothing (LS) has been widely recognized as an effective regularization technique that prevents models from becoming over-confident and improves their generalization. This inspires us to explore the integration of LS with prompt tuning. However, we have observed that the vanilla LS even weakens the generalization ability of prompt tuning. To address this issue, we propose the Alternating Training-based Label Smoothing (ATLaS) method, which alternately trains with standard one-hot labels and soft labels generated by LS to supervise the prompt tuning. Moreover, we introduce two types of efficient offline soft labels, including Class-wise Soft Labels (CSL) and Instance-wise Soft Labels (ISL), to provide inter-class or instance-class relationships for prompt tuning. The theoretical properties of the proposed ATLaS method are analyzed. Extensive experiments demonstrate that the proposed ATLaS method, combined with CSL and ISL, consistently enhances the generalization performance of prompt tuning. Moreover, the proposed ATLaS method exhibits high compatibility with prevalent prompt tuning methods, enabling seamless integration into existing methods.
Think as Cardiac Sonographers: Marrying SAM with Left Ventricular Indicators Measurements According to Clinical Guidelines
Aug 12, 2025Left ventricular (LV) indicator measurements following clinical echocardiog-raphy guidelines are important for diagnosing cardiovascular disease. Alt-hough existing algorithms have explored automated LV quantification, they can struggle to capture generic visual representations due to the normally small training datasets. Therefore, it is necessary to introduce vision founda-tional models (VFM) with abundant knowledge. However, VFMs represented by the segment anything model (SAM) are usually suitable for segmentation but incapable of identifying key anatomical points, which are critical in LV indicator measurements. In this paper, we propose a novel framework named AutoSAME, combining the powerful visual understanding of SAM with seg-mentation and landmark localization tasks simultaneously. Consequently, the framework mimics the operation of cardiac sonographers, achieving LV indi-cator measurements consistent with clinical guidelines. We further present fil-tered cross-branch attention (FCBA) in AutoSAME, which leverages relatively comprehensive features in the segmentation to enhance the heatmap regression (HR) of key points from the frequency domain perspective, optimizing the vis-ual representation learned by the latter. Moreover, we propose spatial-guided prompt alignment (SGPA) to automatically generate prompt embeddings guid-ed by spatial properties of LV, thereby improving the accuracy of dense pre-dictions by prior spatial knowledge. The extensive experiments on an echocar-diography dataset demonstrate the efficiency of each design and the superiori-ty of our AutoSAME in LV segmentation, landmark localization, and indicator measurements. The code will be available at https://github.com/QC-LIU-1997/AutoSAME.
EndoAgent: A Memory-Guided Reflective Agent for Intelligent Endoscopic Vision-to-Decision Reasoning
Aug 10, 2025



Developing general artificial intelligence (AI) systems to support endoscopic image diagnosis is an emerging research priority. Existing methods based on large-scale pretraining often lack unified coordination across tasks and struggle to handle the multi-step processes required in complex clinical workflows. While AI agents have shown promise in flexible instruction parsing and tool integration across domains, their potential in endoscopy remains underexplored. To address this gap, we propose EndoAgent, the first memory-guided agent for vision-to-decision endoscopic analysis that integrates iterative reasoning with adaptive tool selection and collaboration. Built on a dual-memory design, it enables sophisticated decision-making by ensuring logical coherence through short-term action tracking and progressively enhancing reasoning acuity through long-term experiential learning. To support diverse clinical tasks, EndoAgent integrates a suite of expert-designed tools within a unified reasoning loop. We further introduce EndoAgentBench, a benchmark of 5,709 visual question-answer pairs that assess visual understanding and language generation capabilities in realistic scenarios. Extensive experiments show that EndoAgent consistently outperforms both general and medical multimodal models, exhibiting its strong flexibility and reasoning capabilities.
Harnessing Adaptive Topology Representations for Zero-Shot Graph Question Answering
Aug 08, 2025



Large Multimodal Models (LMMs) have shown generalized zero-shot capabilities in diverse domain question-answering (QA) tasks, including graph QA that involves complex graph topologies. However, most current approaches use only a single type of graph representation, namely Topology Representation Form (TRF), such as prompt-unified text descriptions or style-fixed visual styles. Those "one-size-fits-all" approaches fail to consider the specific preferences of different models or tasks, often leading to incorrect or overly long responses. To address this, we first analyze the characteristics and weaknesses of existing TRFs, and then design a set of TRFs, denoted by $F_{ZS}$, tailored to zero-shot graph QA. We then introduce a new metric, Graph Response Efficiency (GRE), which measures the balance between the performance and the brevity in graph QA. Built on these, we develop the DynamicTRF framework, which aims to improve both the accuracy and conciseness of graph QA. To be specific, DynamicTRF first creates a TRF Preference (TRFP) dataset that ranks TRFs based on their GRE scores, to probe the question-specific TRF preferences. Then it trains a TRF router on the TRFP dataset, to adaptively assign the best TRF from $F_{ZS}$ for each question during the inference. Extensive experiments across 7 in-domain algorithmic graph QA tasks and 2 out-of-domain downstream tasks show that DynamicTRF significantly enhances the zero-shot graph QA of LMMs in terms of accuracy
Marine Chlorophyll Prediction and Driver Analysis based on LSTM-RF Hybrid Models
Aug 07, 2025Marine chlorophyll concentration is an important indicator of ecosystem health and carbon cycle strength, and its accurate prediction is crucial for red tide warning and ecological response. In this paper, we propose a LSTM-RF hybrid model that combines the advantages of LSTM and RF, which solves the deficiencies of a single model in time-series modelling and nonlinear feature portrayal. Trained with multi-source ocean data(temperature, salinity, dissolved oxygen, etc.), the experimental results show that the LSTM-RF model has an R^2 of 0.5386, an MSE of 0.005806, and an MAE of 0.057147 on the test set, which is significantly better than using LSTM (R^2 = 0.0208) and RF (R^2 =0.4934) alone , respectively. The standardised treatment and sliding window approach improved the prediction accuracy of the model and provided an innovative solution for high-frequency prediction of marine ecological variables.