 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Data-engine Foundation Model for Universal Few-shot 2D Vascular Image Segmentation
Apr 12, 2026The segmentation of 2D vascular structures via deep learning holds significant clinical value but is hindered by the scarcity of annotated data, severely limiting its widespread application. Developing a universal few-shot vascular segmentation model is highly desirable, yet remains challenging due to the need for extensive training and the inherent complexities of vascular imaging. In this work, we propose UniVG (Generative Data-engine Foundation Model for Universal Few-shot 2D Vascular Image Segmentation), a novel approach that learns the compositionality of vascular images and constructing a generative foundation model for robust vascular segmentation. UniVG enables the synthesis and learning of diverse and realistic vascular images through two key innovations: 1) Compositional learning for flexible and diverse vascular synthesis: It decomposes and recombines vascular structures with varying morphological features and diverse foreground-background configurations to generate richly diverse synthetic image-label pairs. 2) Few-shot generative adaptation for transferable segmentation: It fine-tunes pre-trained models with minimal annotated data to bridge the gap between synthetic and real vascular domains, synthesizing authentic and diverse vessel images for downstream few-shot vascular segmentation learning. To support our approach, we develop UniVG-58K, a large dataset comprising 58,689 vascular images across five imaging modalities, facilitating robust large-scale generative pre-training. Extensive experiments on 11 vessel segmentation tasks cross 5 modalties (only with 5 labeled images on each task) demonstrate that UniVG achieves performance comparable to fully supervised models, significantly reducing data collection and annotation costs. All code and datasets will be made publicly available at https://github.com/XinAloha/UniVG.
DINO-BOLDNet: A DINOv3-Guided Multi-Slice Attention Network for T1-to-BOLD Generation
Dec 09, 2025



Generating BOLD images from T1w images offers a promising solution for recovering missing BOLD information and enabling downstream tasks when BOLD images are corrupted or unavailable. Motivated by this, we propose DINO-BOLDNet, a DINOv3-guided multi-slice attention framework that integrates a frozen self-supervised DINOv3 encoder with a lightweight trainable decoder. The model uses DINOv3 to extract within-slice structural representations, and a separate slice-attention module to fuse contextual information across neighboring slices. A multi-scale generation decoder then restores fine-grained functional contrast, while a DINO-based perceptual loss encourages structural and textural consistency between predictions and ground-truth BOLD in the transformer feature space. Experiments on a clinical dataset of 248 subjects show that DINO-BOLDNet surpasses a conditional GAN baseline in both PSNR and MS-SSIM. To our knowledge, this is the first framework capable of generating mean BOLD images directly from T1w images, highlighting the potential of self-supervised transformer guidance for structural-to-functional mapping.
Large Foundation Model for Ads Recommendation
Aug 20, 2025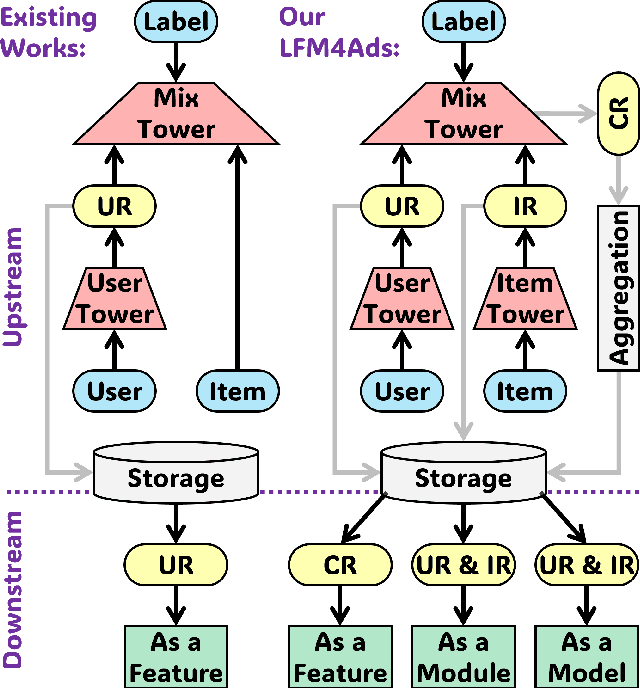
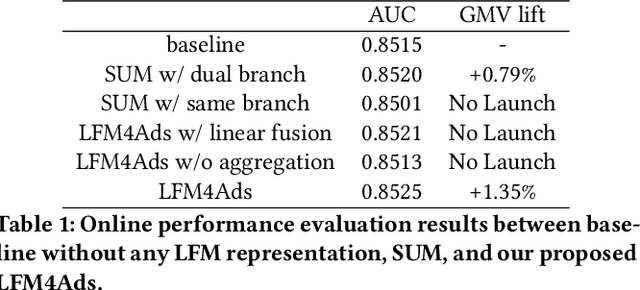
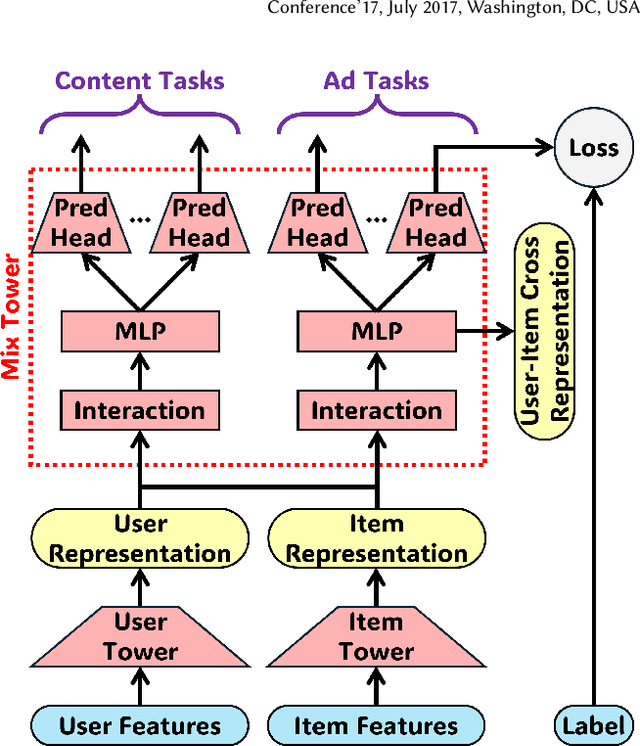
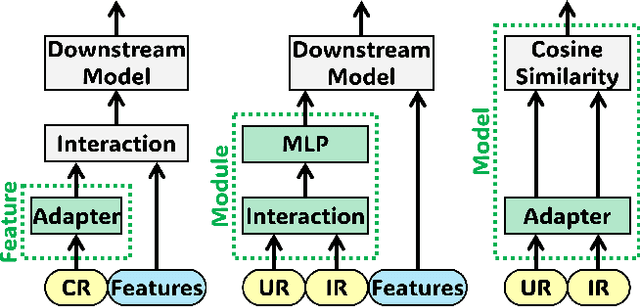
Online advertising relies on accurate recommendation models, with recent advances using pre-trained large-scale foundation models (LFMs) to capture users' general interests across multiple scenarios and tasks. However, existing methods have critical limitations: they extract and transfer only user representations (URs), ignoring valuable item representations (IRs) and user-item cross representations (CRs); and they simply use a UR as a feature in downstream applications, which fails to bridge upstream-downstream gaps and overlooks more transfer granularities. In this paper, we propose LFM4Ads, an All-Representation Multi-Granularity transfer framework for ads recommendation. It first comprehensively transfers URs, IRs, and CRs, i.e., all available representations in the pre-trained foundation model. To effectively utilize the CRs, it identifies the optimal extraction layer and aggregates them into transferable coarse-grained forms. Furthermore, we enhance the transferability via multi-granularity mechanisms: non-linear adapters for feature-level transfer, an Isomorphic Interaction Module for module-level transfer, and Standalone Retrieval for model-level transfer. LFM4Ads has been successfully deployed in Tencent's industrial-scale advertising platform, processing tens of billions of daily samples while maintaining terabyte-scale model parameters with billions of sparse embedding keys across approximately two thousand features. Since its production deployment in Q4 2024, LFM4Ads has achieved 10+ successful production launches across various advertising scenarios, including primary ones like Weixin Moments and Channels. These launches achieve an overall GMV lift of 2.45% across the entire platform, translating to estimated annual revenue increases in the hundreds of millions of dollars.
A multi-stage semi-supervised learning for ankle fracture classification on CT images
Mar 29, 2024



Because of the complicated mechanism of ankle injury, it is very difficult to diagnose ankle fracture in clinic. In order to simplify the process of fracture diagnosis, an automatic diagnosis model of ankle fracture was proposed. Firstly, a tibia-fibula segmentation network is proposed for the joint tibiofibular region of the ankle joint, and the corresponding segmentation dataset is established on the basis of fracture data. Secondly, the image registration method is used to register the bone segmentation mask with the normal bone mask. Finally, a semi-supervised classifier is constructed to make full use of a large number of unlabeled data to classify ankle fractures. Experiments show that the proposed method can segment fractures with fracture lines accurately and has better performance than the general method. At the same time, this method is superior to classification network in several indexes.
Multiscale Low-Frequency Memory Network for Improved Feature Extraction in Convolutional Neural Networks
Mar 13, 2024



Deep learning and Convolutional Neural Networks (CNNs) have driven major transformations in diverse research areas. However, their limitations in handling low-frequency information present obstacles in certain tasks like interpreting global structures or managing smooth transition images. Despite the promising performance of transformer structures in numerous tasks, their intricate optimization complexities highlight the persistent need for refined CNN enhancements using limited resources. Responding to these complexities, we introduce a novel framework, the Multiscale Low-Frequency Memory (MLFM) Network, with the goal to harness the full potential of CNNs while keeping their complexity unchanged. The MLFM efficiently preserves low-frequency information, enhancing performance in targeted computer vision tasks. Central to our MLFM is the Low-Frequency Memory Unit (LFMU), which stores various low-frequency data and forms a parallel channel to the core network. A key advantage of MLFM is its seamless compatibility with various prevalent networks, requiring no alterations to their original core structure. Testing on ImageNet demonstrated substantial accuracy improvements in multiple 2D CNNs, including ResNet, MobileNet, EfficientNet, and ConvNeXt. Furthermore, we showcase MLFM's versatility beyond traditional image classification by successfully integrating it into image-to-image translation tasks, specifically in semantic segmentation networks like FCN and U-Net. In conclusion, our work signifies a pivotal stride in the journey of optimizing the efficacy and efficiency of CNNs with limited resources. This research builds upon the existing CNN foundations and paves the way for future advancements in computer vision. Our codes are available at https://github.com/AlphaWuSeu/ MLFM.
Speech Denoising Using Only Single Noisy Audio Samples
Oct 30, 2021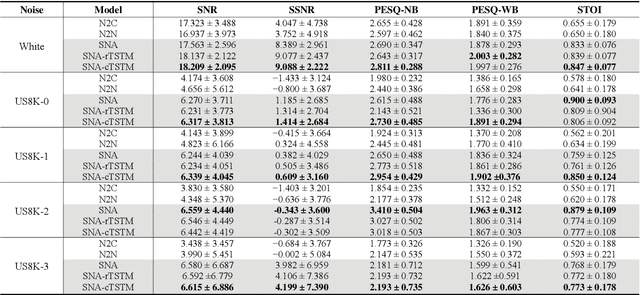
In this paper, we propose a novel Single Noisy Audio De-noising Framework (SNA-DF) for speech denoising using only single noisy audio samples, which overcomes the limi-tation of constructing either noisy-clean training pairs or multiple independent noisy audio samples. The proposed SNA-DF contains two modules: training audio pairs gener-ated module and audio denoising module. The first module adopts a random audio sub-sampler on single noisy audio samples for the generation of training audio pairs. The sub-sampled training audio pairs are then fed into the audio denoising module, which employs a deep complex U-Net incorporating a complex two-stage transformer (cTSTM) to extract both magnitude and phase information for taking full advantage of the complex features of single noisy au-dios. Experimental results show that the proposed SNA-DF not only eliminates the high dependence on clean targets of traditional audio denoising methods, but also outperforms the methods using multiple noisy audio samples.
XCrossNet: Feature Structure-Oriented Learning for Click-Through Rate Prediction
Apr 22, 2021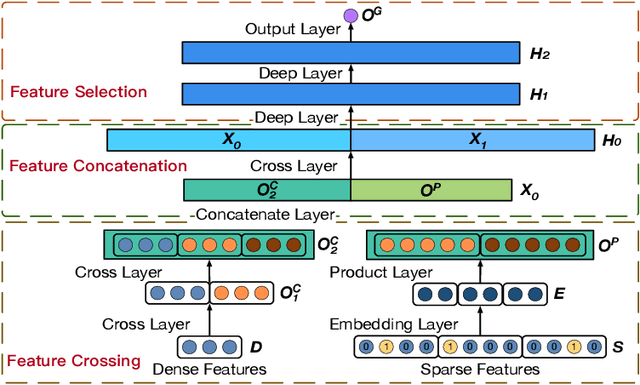
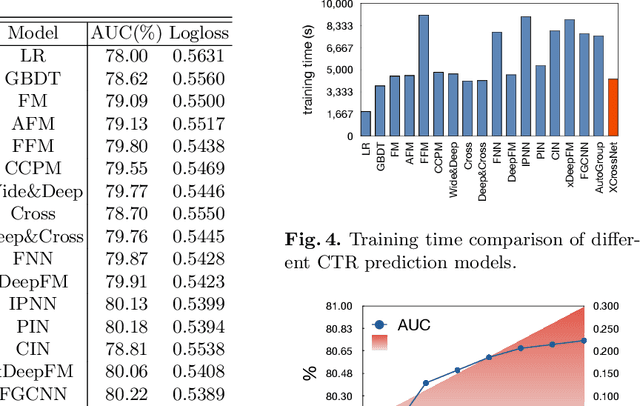
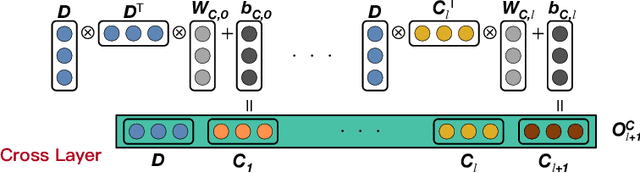
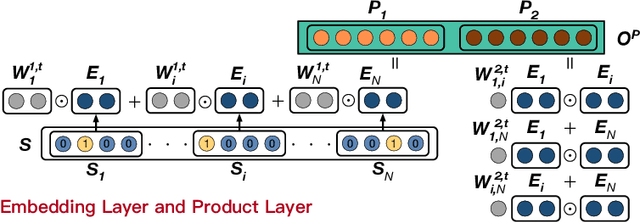
Click-Through Rate (CTR) prediction is a core task in nowadays commercial recommender systems. Feature crossing, as the mainline of research on CTR prediction, has shown a promising way to enhance predictive performance. Even though various models are able to learn feature interactions without manual feature engineering, they rarely attempt to individually learn representations for different feature structures. In particular, they mainly focus on the modeling of cross sparse features but neglect to specifically represent cross dense features. Motivated by this, we propose a novel Extreme Cross Network, abbreviated XCrossNet, which aims at learning dense and sparse feature interactions in an explicit manner. XCrossNet as a feature structure-oriented model leads to a more expressive representation and a more precise CTR prediction, which is not only explicit and interpretable, but also time-efficient and easy to implement. Experimental studies on Criteo Kaggle dataset show significant improvement of XCrossNet over state-of-the-art models on both effectiveness and efficiency.
Compressing complex convolutional neural network based on an improved deep compression algorithm
Mar 06, 2019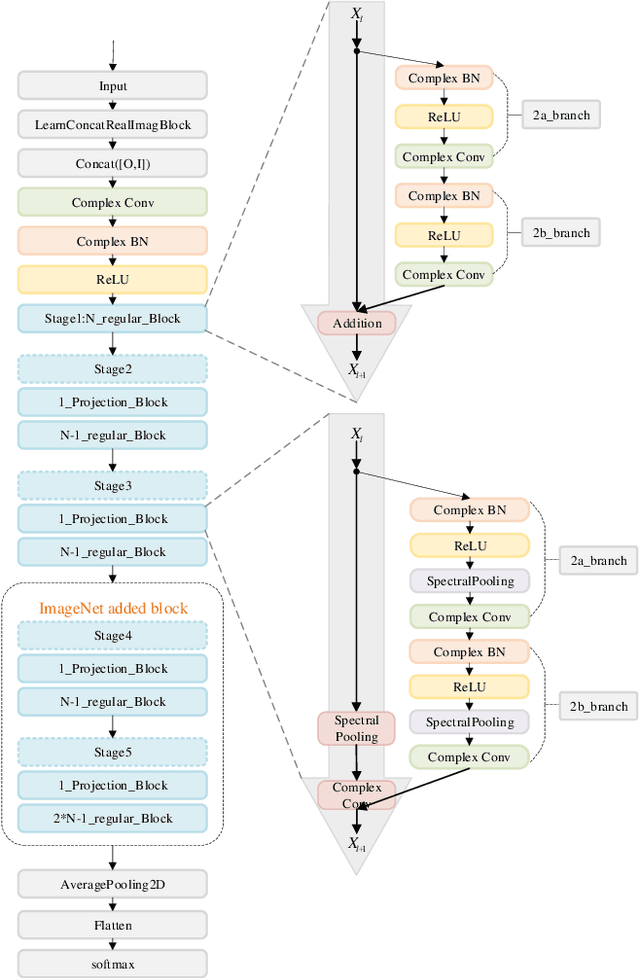
Although convolutional neural network (CNN) has made great progress, large redundant parameters restrict its deployment on embedded devices, especially mobile devices. The recent compression works are focused on real-value convolutional neural network (Real CNN), however, to our knowledge, there is no attempt for the compression of complex-value convolutional neural network (Complex CNN). Compared with the real-valued network, the complex-value neural network is easier to optimize, generalize, and has better learning potential. This paper extends the commonly used deep compression algorithm from real domain to complex domain and proposes an improved deep compression algorithm for the compression of Complex CNN. The proposed algorithm compresses the network about 8 times on CIFAR-10 dataset with less than 3% accuracy loss. On the ImageNet dataset, our method compresses the model about 16 times and the accuracy loss is about 2% without retraining.