 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocalBench-zh: Decomposing and Benchmarking the Speech Conversational Abilities in Mandarin Context
Nov 17, 2025



The development of multi-modal large language models (LLMs) leads to intelligent approaches capable of speech interactions. As one of the most widely spoken languages globally, Mandarin is supported by most models to enhance their applicability and reach. However, the scarcity of comprehensive speech-to-speech (S2S) benchmarks in Mandarin contexts impedes systematic evaluation for developers and hinders fair model comparison for users. In this work, we propose VocalBench-zh, an ability-level divided evaluation suite adapted to Mandarin context consisting of 10 well-crafted subsets and over 10K high-quality instances, covering 12 user-oriented characters. The evaluation experiment on 14 mainstream models reveals the common challenges for current routes, and highlights the need for new insights into next-generation speech interactive systems. The evaluation codes and datasets will be available at https://github.com/SJTU-OmniAgent/VocalBench-zh.
VocalNet-M2: Advancing Low-Latency Spoken Language Modeling via Integrated Multi-Codebook Tokenization and Multi-Token Prediction
Nov 13, 2025Current end-to-end spoken language models (SLMs) have made notable progress, yet they still encounter considerable response latency. This delay primarily arises from the autoregressive generation of speech tokens and the reliance on complex flow-matching models for speech synthesis. To overcome this, we introduce VocalNet-M2, a novel low-latency SLM that integrates a multi-codebook tokenizer and a multi-token prediction (MTP) strategy. Our model directly generates multi-codebook speech tokens, thus eliminating the need for a latency-inducing flow-matching model. Furthermore, our MTP strategy enhances generation efficiency and improves overall performance. Extensive experiments demonstrate that VocalNet-M2 achieves a substantial reduction in first chunk latency (from approximately 725ms to 350ms) while maintaining competitive performance across mainstream SLMs. This work also provides a comprehensive comparison of single-codebook and multi-codebook strategies, offering valuable insights for developing efficient and high-performance SLMs for real-time interactive applications.
Selecting Auxiliary Data via Neural Tangent Kernels for Low-Resource Domains
Nov 10, 2025Large language models (LLMs) have achieved remarkable success across widespread tasks, yet their application in low-resource domains remains a significant challenge due to data scarcity and the high risk of overfitting. While in-domain data is limited, there exist vast amounts of similar general-domain data, and our initial findings reveal that they could potentially serve as auxiliary supervision for domain enhancement. This observation leads us to our central research question: \textbf{\textit{how to effectively select the most valuable auxiliary data to maximize domain-specific performance}}, particularly when traditional methods are inapplicable due to a lack of large in-domain data pools or validation sets. To address this, we propose \textbf{NTK-Selector}, a principled and efficient framework for selecting general-domain auxiliary data to enhance domain-specific performance via neural tangent kernels (NTK). Our method tackles two challenges of directly applying NTK to LLMs, theoretical assumptions and prohibitive computational cost, by empirically demonstrating a stable NTK-like behavior in LLMs during LoRA fine-tuning and proposing a Jacobian-free approximation method. Extensive experiments across four low-resource domains (medical, financial, legal, and psychological) demonstrate that NTK-Selector consistently improves downstream performance. Specifically, fine-tuning on 1,000 in-domain samples alone only yielded +0.8 points for Llama3-8B-Instruct and +0.9 points for Qwen3-8B. In contrast, enriching with 9,000 auxiliary samples selected by NTK-Selector led to substantial \textbf{gains of +8.7 and +5.1 points}, which corresponds to a \textbf{10.9x and 5.7x improvement} over the domain-only setting.
CS3-Bench: Evaluating and Enhancing Speech-to-Speech LLMs for Mandarin-English Code-Switching
Oct 09, 2025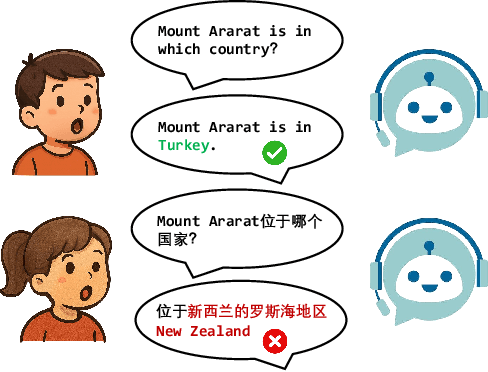

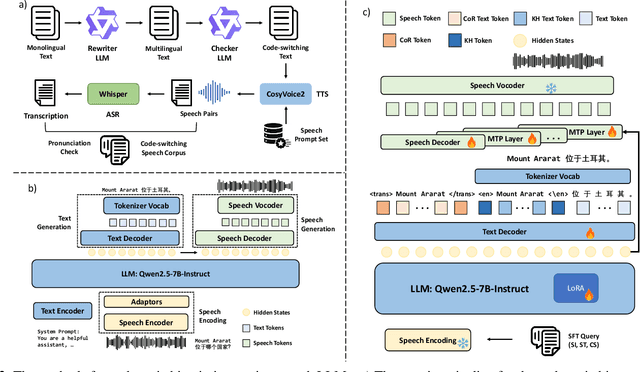
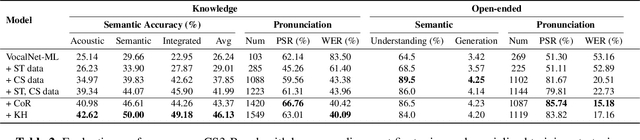
The advancement of multimodal large language models has accelerated the development of speech-to-speech interaction systems. While natural monolingual interaction has been achieved, we find existing models exhibit deficiencies in language alignment. In our proposed Code-Switching Speech-to-Speech Benchmark (CS3-Bench), experiments on 7 mainstream models demonstrate a relative performance drop of up to 66% in knowledge-intensive question answering and varying degrees of misunderstanding in open-ended conversations. Starting from a model with severe performance deterioration, we propose both data constructions and training approaches to improve the language alignment capabilities, specifically employing Chain of Recognition (CoR) to enhance understanding and Keyword Highlighting (KH) to guide generation. Our approach improves the knowledge accuracy from 25.14% to 46.13%, with open-ended understanding rate from 64.5% to 86.5%, and significantly reduces pronunciation errors in the secondary language. CS3-Bench is available at https://huggingface.co/datasets/VocalNet/CS3-Bench.
Wide-In, Narrow-Out: Revokable Decoding for Efficient and Effective DLLMs
Jul 24, 2025



Diffusion Large Language Models (DLLMs) have emerged as a compelling alternative to Autoregressive models, designed for fast parallel generation. However, existing DLLMs are plagued by a severe quality-speed trade-off, where faster parallel decoding leads to significant performance degradation. We attribute this to the irreversibility of standard decoding in DLLMs, which is easily polarized into the wrong decoding direction along with early error context accumulation. To resolve this, we introduce Wide-In, Narrow-Out (WINO), a training-free decoding algorithm that enables revokable decoding in DLLMs. WINO employs a parallel draft-and-verify mechanism, aggressively drafting multiple tokens while simultaneously using the model's bidirectional context to verify and re-mask suspicious ones for refinement. Verified in open-source DLLMs like LLaDA and MMaDA, WINO is shown to decisively improve the quality-speed trade-off. For instance, on the GSM8K math benchmark, it accelerates inference by 6$\times$ while improving accuracy by 2.58%; on Flickr30K captioning, it achieves a 10$\times$ speedup with higher performance. More comprehensive experiments are conducted to demonstrate the superiority and provide an in-depth understanding of WINO.
Differential-informed Sample Selection Accelerates Multimodal Contrastive Learning
Jul 17, 2025



The remarkable success of contrastive-learning-based multimodal models has been greatly driven by training on ever-larger datasets with expensive compute consumption. Sample selection as an alternative efficient paradigm plays an important direction to accelerate the training process. However, recent advances on sample selection either mostly rely on an oracle model to offline select a high-quality coreset, which is limited in the cold-start scenarios, or focus on online selection based on real-time model predictions, which has not sufficiently or efficiently considered the noisy correspondence. To address this dilemma, we propose a novel Differential-Informed Sample Selection (DISSect) method, which accurately and efficiently discriminates the noisy correspondence for training acceleration. Specifically, we rethink the impact of noisy correspondence on contrastive learning and propose that the differential between the predicted correlation of the current model and that of a historical model is more informative to characterize sample quality. Based on this, we construct a robust differential-based sample selection and analyze its theoretical insights. Extensive experiments on three benchmark datasets and various downstream tasks demonstrate the consistent superiority of DISSect over current state-of-the-art methods. Source code is available at: https://github.com/MediaBrain-SJTU/DISSect.
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Jul 02, 2025



We present GLM-4.1V-Thinking, a vision-language model (VLM) designed to advance general-purpose multimodal understanding and reasoning. In this report, we share our key findings in the development of the reasoning-centric training framework. We first develop a capable vision foundation model with significant potential through large-scale pre-training, which arguably sets the upper bound for the final performance. We then propose Reinforcement Learning with Curriculum Sampling (RLCS) to unlock the full potential of the model, leading to comprehensive capability enhancement across a diverse range of tasks, including STEM problem solving, video understanding, content recognition, coding, grounding, GUI-based agents, and long document understanding. We open-source GLM-4.1V-9B-Thinking, which achieves state-of-the-art performance among models of comparable size. In a comprehensive evaluation across 28 public benchmarks, our model outperforms Qwen2.5-VL-7B on nearly all tasks and achieves comparable or even superior performance on 18 benchmarks relative to the significantly larger Qwen2.5-VL-72B. Notably, GLM-4.1V-9B-Thinking also demonstrates competitive or superior performance compared to closed-source models such as GPT-4o on challenging tasks including long document understanding and STEM reasoning, further underscoring its strong capabilities. Code, models and more information are released at https://github.com/THUDM/GLM-4.1V-Thinking.
Universal Video Temporal Grounding with Generative Multi-modal Large Language Models
Jun 23, 2025This paper presents a computational model for universal video temporal grounding, which accurately localizes temporal moments in videos based on natural language queries (e.g., questions or descriptions). Unlike existing methods that are often limited to specific video domains or durations, we propose UniTime, a robust and universal video grounding model leveraging the strong vision-language understanding capabilities of generative Multi-modal Large Language Models (MLLMs). Our model effectively handles videos of diverse views, genres, and lengths while comprehending complex language queries. The key contributions include: (i) We consider steering strong MLLMs for temporal grounding in videos. To enable precise timestamp outputs, we incorporate temporal information by interleaving timestamp tokens with video tokens. (ii) By training the model to handle videos with different input granularities through adaptive frame scaling, our approach achieves robust temporal grounding for both short and long videos. (iii) Comprehensive experiments show that UniTime outperforms state-of-the-art approaches in both zero-shot and dataset-specific finetuned settings across five public temporal grounding benchmarks. (iv) When employed as a preliminary moment retriever for long-form video question-answering (VideoQA), UniTime significantly improves VideoQA accuracy, highlighting its value for complex video understanding tasks.
ConText: Driving In-context Learning for Text Removal and Segmentation
Jun 04, 2025This paper presents the first study on adapting the visual in-context learning (V-ICL) paradigm to optical character recognition tasks, specifically focusing on text removal and segmentation. Most existing V-ICL generalists employ a reasoning-as-reconstruction approach: they turn to using a straightforward image-label compositor as the prompt and query input, and then masking the query label to generate the desired output. This direct prompt confines the model to a challenging single-step reasoning process. To address this, we propose a task-chaining compositor in the form of image-removal-segmentation, providing an enhanced prompt that elicits reasoning with enriched intermediates. Additionally, we introduce context-aware aggregation, integrating the chained prompt pattern into the latent query representation, thereby strengthening the model's in-context reasoning. We also consider the issue of visual heterogeneity, which complicates the selection of homogeneous demonstrations in text recognition. Accordingly, this is effectively addressed through a simple self-prompting strategy, preventing the model's in-context learnability from devolving into specialist-like, context-free inference. Collectively, these insights culminate in our ConText model, which achieves new state-of-the-art across both in- and out-of-domain benchmarks. The code is available at https://github.com/Ferenas/ConText.
Bridging the Dynamic Perception Gap: Training-Free Draft Chain-of-Thought for Dynamic Multimodal Spatial Reasoning
May 22, 2025While chains-of-thought (CoT) have advanced complex reasoning in multimodal large language models (MLLMs), existing methods remain confined to text or static visual domains, often faltering in dynamic spatial reasoning tasks. To bridge this gap, we present GRASSLAND, a novel maze navigation benchmark designed to evaluate dynamic spatial reasoning. Our experiments show that augmenting textual reasoning chains with dynamic visual drafts, overlaid on input images, significantly outperforms conventional approaches, offering new insights into spatial reasoning in evolving environments. To generalize this capability, we propose D2R (Dynamic Draft-Augmented Reasoning), a training-free framework that seamlessly integrates textual CoT with corresponding visual drafts into MLLMs. Extensive evaluations demonstrate that D2R consistently enhances performance across diverse tasks, establishing a robust baseline for dynamic spatial reasoning without requiring model fine-tuning. Project is open at https://github.com/Cratileo/D2R.