 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShape Guided Gradient Voting for Domain Generalization
Jun 19, 2023



Domain generalization aims to address the domain shift between training and testing data. To learn the domain invariant representations, the model is usually trained on multiple domains. It has been found that the gradients of network weight relative to a specific task loss can characterize the task itself. In this work, with the assumption that the gradients of a specific domain samples under the classification task could also reflect the property of the domain, we propose a Shape Guided Gradient Voting (SGGV) method for domain generalization. Firstly, we introduce shape prior via extra inputs of the network to guide gradient descending towards a shape-biased direction for better generalization. Secondly, we propose a new gradient voting strategy to remove the outliers for robust optimization in the presence of shape guidance. To provide shape guidance, we add edge/sketch extracted from the training data as an explicit way, and also use texture augmented images as an implicit way. We conduct experiments on several popular domain generalization datasets in image classification task, and show that our shape guided gradient updating strategy brings significant improvement of the generalization.
Region-Enhanced Feature Learning for Scene Semantic Segmentation
Apr 18, 2023



Semantic segmentation in complex scenes not only relies on local object appearance but also on object locations and the surrounding environment. Nonetheless, it is difficult to model long-range context in the format of pairwise point correlations due to its huge computational cost for large-scale point clouds. In this paper, we propose to use regions as the intermediate representation of point clouds instead of fine-grained points or voxels to reduce the computational burden. We introduce a novel Region-Enhanced Feature Learning network (REFL-Net) that leverages region correlations to enhance the features of ambiguous points. We design a Region-based Feature Enhancement module (RFE) which consists of a Semantic-Spatial Region Extraction (SSRE) stage and a Region Dependency Modeling (RDM) stage. In the SSRE stage, we group the input points into a set of regions according to the point distances in both semantic and spatial space. In the RDM part, we explore region-wise semantic and spatial relationships via a self-attention block on region features and fuse point features with the region features to obtain more discriminative representations. Our proposed RFE module is a plug-and-play module that can be integrated with common semantic segmentation backbones. We conduct extensive experiments on ScanNetv2 and S3DIS datasets, and evaluate our RFE module with different segmentation backbones. Our REFL-Net achieves 1.8% mIoU gain on ScanNetv2 and 1.0% mIoU gain on S3DIS respectively with negligible computational cost compared to the backbone networks. Both quantitative and qualitative results show the powerful long-range context modeling ability and strong generalization ability of our REFL-Net.
MovingParts: Motion-based 3D Part Discovery in Dynamic Radiance Field
Mar 10, 2023We present MovingParts, a NeRF-based method for dynamic scene reconstruction and part discovery. We consider motion as an important cue for identifying parts, that all particles on the same part share the common motion pattern. From the perspective of fluid simulation, existing deformation-based methods for dynamic NeRF can be seen as parameterizing the scene motion under the Eulerian view, i.e., focusing on specific locations in space through which the fluid flows as time passes. However, it is intractable to extract the motion of constituting objects or parts using the Eulerian view representation. In this work, we introduce the dual Lagrangian view and enforce representations under the Eulerian/Lagrangian views to be cycle-consistent. Under the Lagrangian view, we parameterize the scene motion by tracking the trajectory of particles on objects. The Lagrangian view makes it convenient to discover parts by factorizing the scene motion as a composition of part-level rigid motions. Experimentally, our method can achieve fast and high-quality dynamic scene reconstruction from even a single moving camera, and the induced part-based representation allows direct applications of part tracking, animation, 3D scene editing, etc.
Semantics-Preserving Sketch Embedding for Face Generation
Nov 23, 2022With recent advances in image-to-image translation tasks, remarkable progress has been witnessed in generating face images from sketches. However, existing methods frequently fail to generate images with details that are semantically and geometrically consistent with the input sketch, especially when various decoration strokes are drawn. To address this issue, we introduce a novel W-W+ encoder architecture to take advantage of the high expressive power of W+ space and semantic controllability of W space. We introduce an explicit intermediate representation for sketch semantic embedding. With a semantic feature matching loss for effective semantic supervision, our sketch embedding precisely conveys the semantics in the input sketches to the synthesized images. Moreover, a novel sketch semantic interpretation approach is designed to automatically extract semantics from vectorized sketches. We conduct extensive experiments on both synthesized sketches and hand-drawn sketches, and the results demonstrate the superiority of our method over existing approaches on both semantics-preserving and generalization ability.
Paint by Example: Exemplar-based Image Editing with Diffusion Models
Nov 23, 2022



Language-guided image editing has achieved great success recently. In this paper, for the first time, we investigate exemplar-guided image editing for more precise control. We achieve this goal by leveraging self-supervised training to disentangle and re-organize the source image and the exemplar. However, the naive approach will cause obvious fusing artifacts. We carefully analyze it and propose an information bottleneck and strong augmentations to avoid the trivial solution of directly copying and pasting the exemplar image. Meanwhile, to ensure the controllability of the editing process, we design an arbitrary shape mask for the exemplar image and leverage the classifier-free guidance to increase the similarity to the exemplar image. The whole framework involves a single forward of the diffusion model without any iterative optimization. We demonstrate that our method achieves an impressive performance and enables controllable editing on in-the-wild images with high fidelity.
Effect of Instance Normalization on Fine-Grained Control for Sketch-Based Face Image Generation
Jul 17, 2022

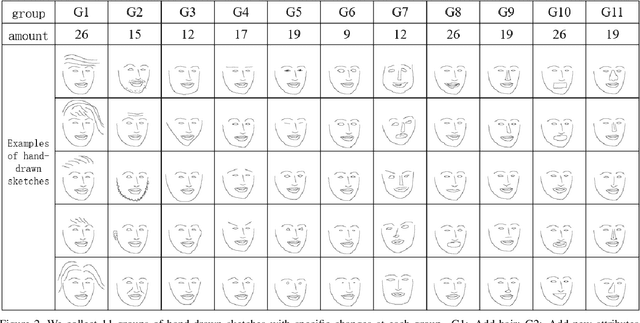
Sketching is an intuitive and effective way for content creation. While significant progress has been made for photorealistic image generation by using generative adversarial networks, it remains challenging to take a fine-grained control on synthetic content. The instance normalization layer, which is widely adopted in existing image translation networks, washes away details in the input sketch and leads to loss of precise control on the desired shape of the generated face images. In this paper, we comprehensively investigate the effect of instance normalization on generating photorealistic face images from hand-drawn sketches. We first introduce a visualization approach to analyze the feature embedding for sketches with a group of specific changes. Based on the visual analysis, we modify the instance normalization layers in the baseline image translation model. We elaborate a new set of hand-drawn sketches with 11 categories of specially designed changes and conduct extensive experimental analysis. The results and user studies demonstrate that our method markedly improve the quality of synthesized images and the conformance with user intention.
Exploiting Correspondences with All-pairs Correlations for Multi-view Depth Estimation
May 05, 2022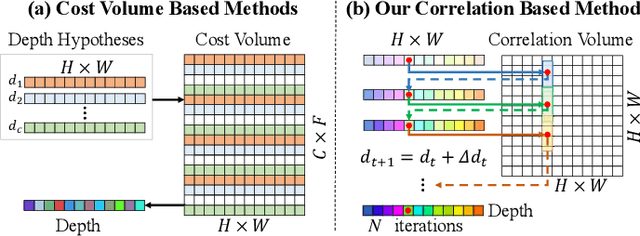
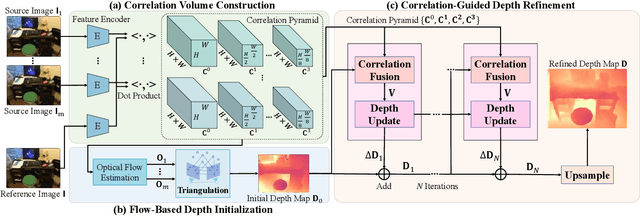
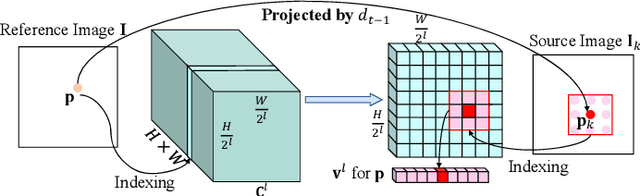
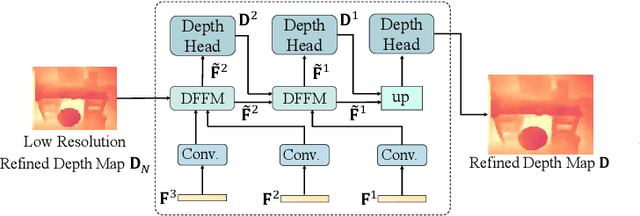
Multi-view depth estimation plays a critical role in reconstructing and understanding the 3D world. Recent learning-based methods have made significant progress in it. However, multi-view depth estimation is fundamentally a correspondence-based optimization problem, but previous learning-based methods mainly rely on predefined depth hypotheses to build correspondence as the cost volume and implicitly regularize it to fit depth prediction, deviating from the essence of iterative optimization based on stereo correspondence. Thus, they suffer unsatisfactory precision and generalization capability. In this paper, we are the first to explore more general image correlations to establish correspondences dynamically for depth estimation. We design a novel iterative multi-view depth estimation framework mimicking the optimization process, which consists of 1) a correlation volume construction module that models the pixel similarity between a reference image and source images as all-to-all correlations; 2) a flow-based depth initialization module that estimates the depth from the 2D optical flow; 3) a novel correlation-guided depth refinement module that reprojects points in different views to effectively fetch relevant correlations for further fusion and integrate the fused correlation for iterative depth update. Without predefined depth hypotheses, the fused correlations establish multi-view correspondence in an efficient way and guide the depth refinement heuristically. We conduct sufficient experiments on ScanNet, DeMoN, ETH3D, and 7Scenes to demonstrate the superiority of our method on multi-view depth estimation and its best generalization ability.
Neural Message Passing for Objective-Based Uncertainty Quantification and Optimal Experimental Design
Mar 14, 2022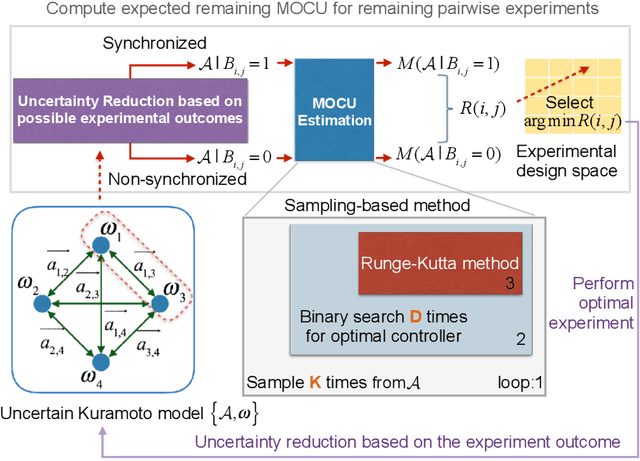
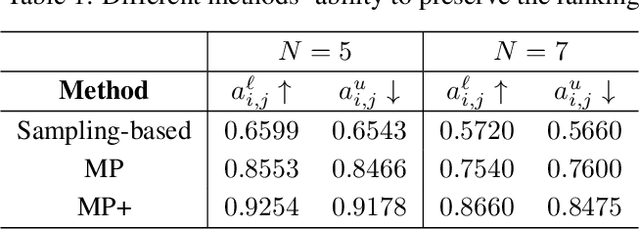
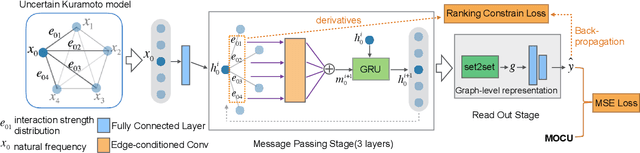
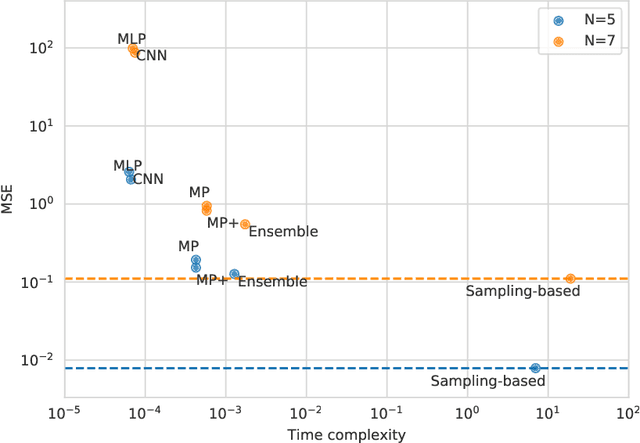
Real-world scientific or engineering applications often involve mathematical modeling of complex uncertain systems with a large number of unknown parameters. The complexity of such systems, and the enormous uncertainties therein, typically make accurate model identification from the available data infeasible. In such cases, it is desirable to represent the model uncertainty in a Bayesian paradigm, based on which we can design robust operators that maintain the best overall performance across all possible models and design optimal experiments that can effectively reduce uncertainty to maximally enhance the performance of such operators. While objective-based uncertainty quantification (objective-UQ) based on MOCU (mean objective cost of uncertainty) has been shown to provide effective means for quantifying and handling uncertainty in complex systems, a major drawback has been the high computational cost of estimating MOCU. In this work, we demonstrate for the first time that one can design accurate surrogate models for efficient objective-UQ via MOCU based on a data-driven approach. We adopt a neural message passing model for surrogate modeling, which incorporates a novel axiomatic constraint loss that penalizes an increase in the estimated system uncertainty. As an illustrative example, we consider the optimal experimental design (OED) problem for uncertain Kuramoto models, where the goal is to predict the experiments that can most effectively enhance the robust synchronization performance through uncertainty reduction. Through quantitative performance assessment, we show that our proposed approach can accelerate MOCU-based OED by four to five orders of magnitude, virtually without any visible loss of performance compared to the previous state-of-the-art. The proposed approach can be applied to general OED tasks, beyond the Kuramoto model.
Dual Progressive Prototype Network for Generalized Zero-Shot Learning
Nov 22, 2021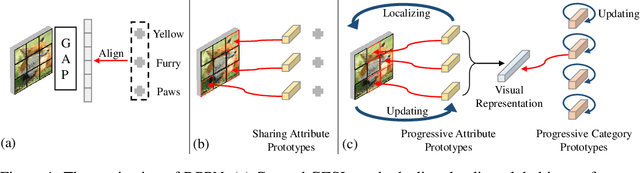
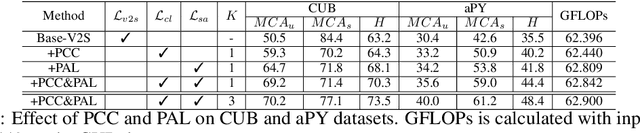
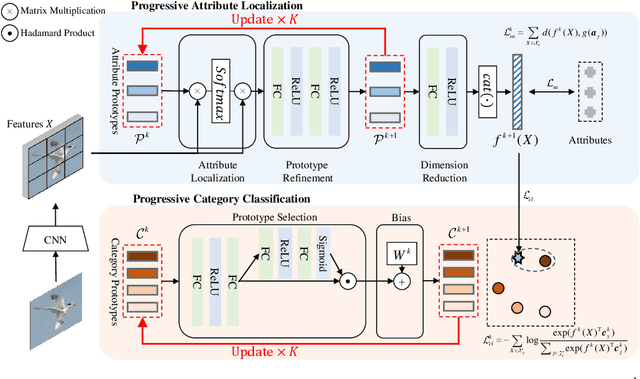
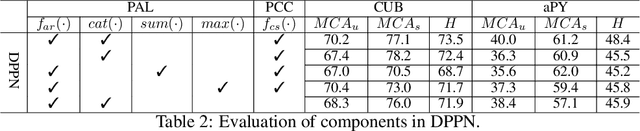
Generalized Zero-Shot Learning (GZSL) aims to recognize new categories with auxiliary semantic information,e.g., category attributes. In this paper, we handle the critical issue of domain shift problem, i.e., confusion between seen and unseen categories, by progressively improving cross-domain transferability and category discriminability of visual representations. Our approach, named Dual Progressive Prototype Network (DPPN), constructs two types of prototypes that record prototypical visual patterns for attributes and categories, respectively. With attribute prototypes, DPPN alternately searches attribute-related local regions and updates corresponding attribute prototypes to progressively explore accurate attribute-region correspondence. This enables DPPN to produce visual representations with accurate attribute localization ability, which benefits the semantic-visual alignment and representation transferability. Besides, along with progressive attribute localization, DPPN further projects category prototypes into multiple spaces to progressively repel visual representations from different categories, which boosts category discriminability. Both attribute and category prototypes are collaboratively learned in a unified framework, which makes visual representations of DPPN transferable and distinctive. Experiments on four benchmarks prove that DPPN effectively alleviates the domain shift problem in GZSL.
Contrastive Learning for Mitochondria Segmentation
Sep 25, 2021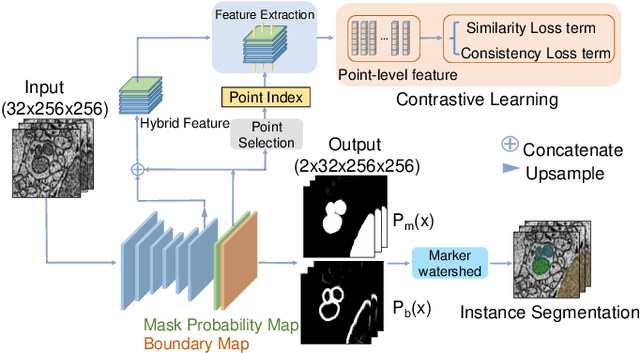


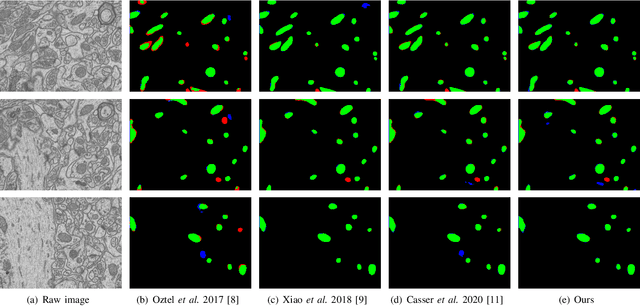
Mitochondria segmentation in electron microscopy images is essential in neuroscience. However, due to the image degradation during the imaging process, the large variety of mitochondrial structures, as well as the presence of noise, artifacts and other sub-cellular structures, mitochondria segmentation is very challenging. In this paper, we propose a novel and effective contrastive learning framework to learn a better feature representation from hard examples to improve segmentation. Specifically, we adopt a point sampling strategy to pick out representative pixels from hard examples in the training phase. Based on these sampled pixels, we introduce a pixel-wise label-based contrastive loss which consists of a similarity loss term and a consistency loss term. The similarity term can increase the similarity of pixels from the same class and the separability of pixels from different classes in feature space, while the consistency term is able to enhance the sensitivity of the 3D model to changes in image content from frame to frame. We demonstrate the effectiveness of our method on MitoEM dataset as well as FIB-SEM dataset and show better or on par with state-of-the-art results.