 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Dynamical Models Through Diffeomorphic Vector Field Alignment
Dec 21, 2025Dynamical systems models such as recurrent neural networks (RNNs) are increasingly popular in theoretical neuroscience for hypothesis-generation and data analysis. Evaluating the dynamics in such models is key to understanding their learned generative mechanisms. However, such evaluation is impeded by two major challenges: First, comparison of learned dynamics across models is difficult because there is no enforced equivalence of their coordinate systems. Second, identification of mechanistically important low-dimensional motifs (e.g., limit sets) is intractable in high-dimensional nonlinear models such as RNNs. Here, we propose a comprehensive framework to address these two issues, termed Diffeomorphic vector field alignment FOR learned Models (DFORM). DFORM learns a nonlinear coordinate transformation between the state spaces of two dynamical systems, which aligns their trajectories in a maximally one-to-one manner. In so doing, DFORM enables an assessment of whether two models exhibit topological equivalence, i.e., similar mechanisms despite differences in coordinate systems. A byproduct of this method is a means to locate dynamical motifs on low-dimensional manifolds embedded within higher-dimensional systems. We verified DFORM's ability to identify linear and nonlinear coordinate transformations using canonical topologically equivalent systems, RNNs, and systems related by nonlinear flows. DFORM was also shown to provide a quantification of similarity between topologically distinct systems. We then demonstrated that DFORM can locate important dynamical motifs including invariant manifolds and saddle limit sets within high-dimensional models. Finally, using a set of RNN models trained on human functional MRI (fMRI) recordings, we illustrated that DFORM can identify limit cycles from high-dimensional data-driven models, which agreed well with prior numerical analysis.
Synergistic pathways of modulation enable robust task packing within neural dynamics
Aug 02, 2024



Understanding how brain networks learn and manage multiple tasks simultaneously is of interest in both neuroscience and artificial intelligence. In this regard, a recent research thread in theoretical neuroscience has focused on how recurrent neural network models and their internal dynamics enact multi-task learning. To manage different tasks requires a mechanism to convey information about task identity or context into the model, which from a biological perspective may involve mechanisms of neuromodulation. In this study, we use recurrent network models to probe the distinctions between two forms of contextual modulation of neural dynamics, at the level of neuronal excitability and at the level of synaptic strength. We characterize these mechanisms in terms of their functional outcomes, focusing on their robustness to context ambiguity and, relatedly, their efficiency with respect to packing multiple tasks into finite size networks. We also demonstrate distinction between these mechanisms at the level of the neuronal dynamics they induce. Together, these characterizations indicate complementarity and synergy in how these mechanisms act, potentially over multiple time-scales, toward enhancing robustness of multi-task learning.
DFORM: Diffeomorphic vector field alignment for assessing dynamics across learned models
Feb 15, 2024



Dynamical system models such as Recurrent Neural Networks (RNNs) have become increasingly popular as hypothesis-generating tools in scientific research. Evaluating the dynamics in such networks is key to understanding their learned generative mechanisms. However, comparison of learned dynamics across models is challenging due to their inherent nonlinearity and because a priori there is no enforced equivalence of their coordinate systems. Here, we propose the DFORM (Diffeomorphic vector field alignment for comparing dynamics across learned models) framework. DFORM learns a nonlinear coordinate transformation which provides a continuous, maximally one-to-one mapping between the trajectories of learned models, thus approximating a diffeomorphism between them. The mismatch between DFORM-transformed vector fields defines the orbital similarity between two models, thus providing a generalization of the concepts of smooth orbital and topological equivalence. As an example, we apply DFORM to models trained on a canonical neuroscience task, showing that learned dynamics may be functionally similar, despite overt differences in attractor landscapes.
Strong anti-Hebbian plasticity alters the convexity of network attractor landscapes
Dec 22, 2023



In this paper, we study recurrent neural networks in the presence of pairwise learning rules. We are specifically interested in how the attractor landscapes of such networks become altered as a function of the strength and nature (Hebbian vs. anti-Hebbian) of learning, which may have a bearing on the ability of such rules to mediate large-scale optimization problems. Through formal analysis, we show that a transition from Hebbian to anti-Hebbian learning brings about a pitchfork bifurcation that destroys convexity in the network attractor landscape. In larger-scale settings, this implies that anti-Hebbian plasticity will bring about multiple stable equilibria, and such effects may be outsized at interconnection or `choke' points. Furthermore, attractor landscapes are more sensitive to slower learning rates than faster ones. These results provide insight into the types of objective functions that can be encoded via different pairwise plasticity rules.
Astrocytes as a mechanism for meta-plasticity and contextually-guided network function
Nov 10, 2023



Astrocytes are a ubiquitous and enigmatic type of non-neuronal cell and are found in the brain of all vertebrates. While traditionally viewed as being supportive of neurons, it is increasingly recognized that astrocytes may play a more direct and active role in brain function and neural computation. On account of their sensitivity to a host of physiological covariates and ability to modulate neuronal activity and connectivity on slower time scales, astrocytes may be particularly well poised to modulate the dynamics of neural circuits in functionally salient ways. In the current paper, we seek to capture these features via actionable abstractions within computational models of neuron-astrocyte interaction. Specifically, we engage how nested feedback loops of neuron-astrocyte interaction, acting over separated time-scales may endow astrocytes with the capability to enable learning in context-dependent settings, where fluctuations in task parameters may occur much more slowly than within-task requirements. We pose a general model of neuron-synapse-astrocyte interaction and use formal analysis to characterize how astrocytic modulation may constitute a form of meta-plasticity, altering the ways in which synapses and neurons adapt as a function of time. We then embed this model in a bandit-based reinforcement learning task environment, and show how the presence of time-scale separated astrocytic modulation enables learning over multiple fluctuating contexts. Indeed, these networks learn far more reliably versus dynamically homogeneous networks and conventional non-network-based bandit algorithms. Our results indicate how the presence of neuron-astrocyte interaction in the brain may benefit learning over different time-scales and the conveyance of task-relevant contextual information onto circuit dynamics.
Representation Learning for Context-Dependent Decision-Making
May 12, 2022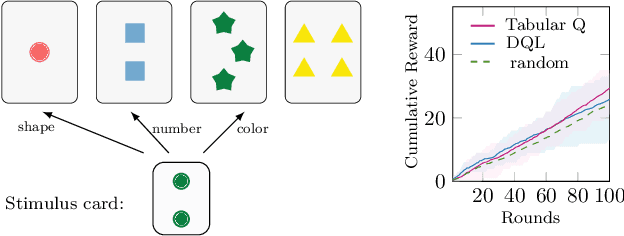
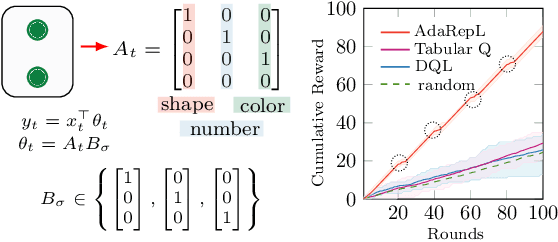
Humans are capable of adjusting to changing environments flexibly and quickly. Empirical evidence has revealed that representation learning plays a crucial role in endowing humans with such a capability. Inspired by this observation, we study representation learning in the sequential decision-making scenario with contextual changes. We propose an online algorithm that is able to learn and transfer context-dependent representations and show that it significantly outperforms the existing ones that do not learn representations adaptively. As a case study, we apply our algorithm to the Wisconsin Card Sorting Task, a well-established test for the mental flexibility of humans in sequential decision-making. By comparing our algorithm with the standard Q-learning and Deep-Q learning algorithms, we demonstrate the benefits of adaptive representation learning.
Non-Stationary Representation Learning in Sequential Linear Bandits
Jan 13, 2022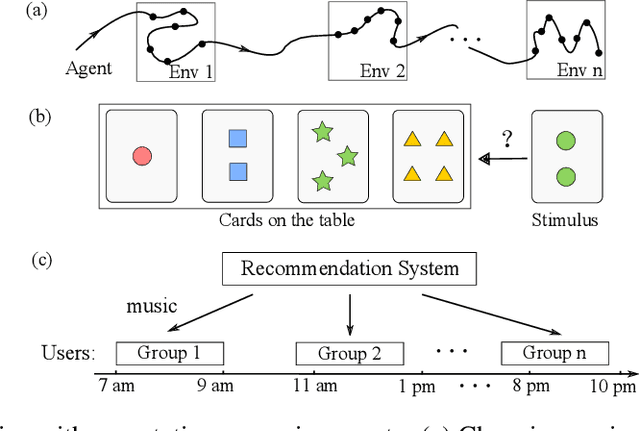
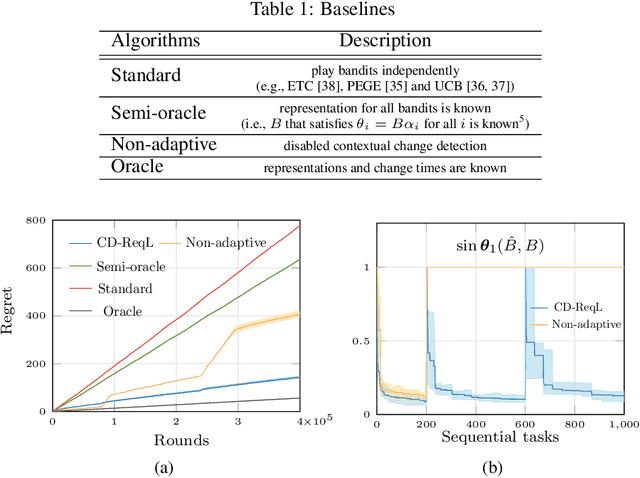
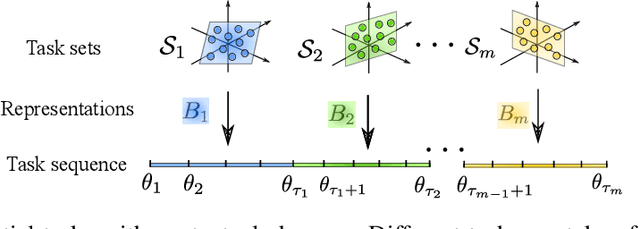
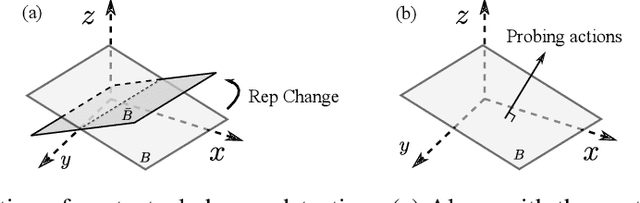
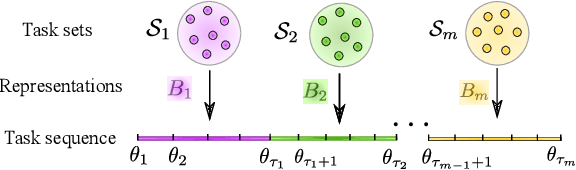
In this paper, we study representation learning for multi-task decision-making in non-stationary environments. We consider the framework of sequential linear bandits, where the agent performs a series of tasks drawn from distinct sets associated with different environments. The embeddings of tasks in each set share a low-dimensional feature extractor called representation, and representations are different across sets. We propose an online algorithm that facilitates efficient decision-making by learning and transferring non-stationary representations in an adaptive fashion. We prove that our algorithm significantly outperforms the existing ones that treat tasks independently. We also conduct experiments using both synthetic and real data to validate our theoretical insights and demonstrate the efficacy of our algorithm.
Slow manifolds in recurrent networks encode working memory efficiently and robustly
Jan 08, 2021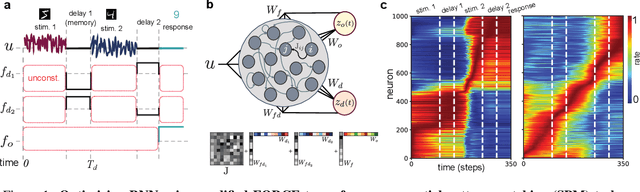
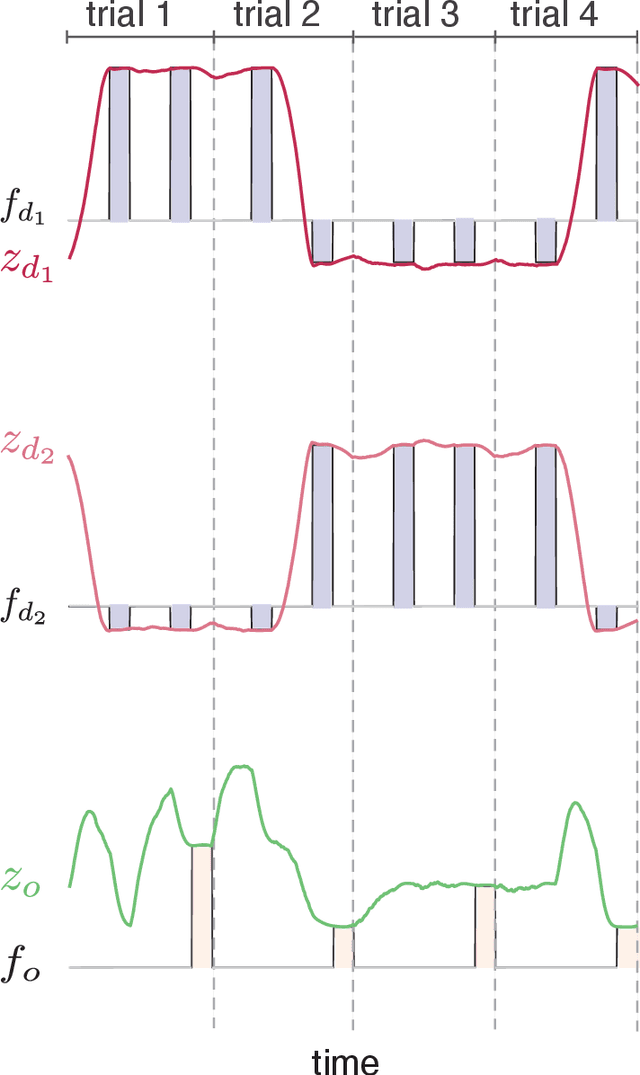
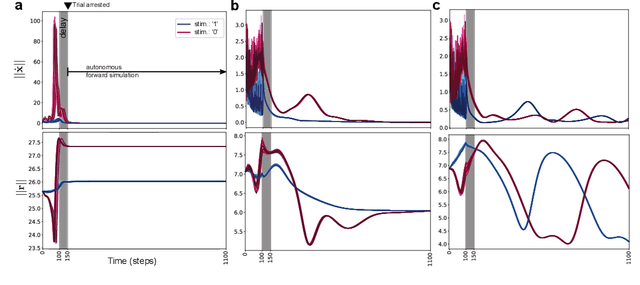
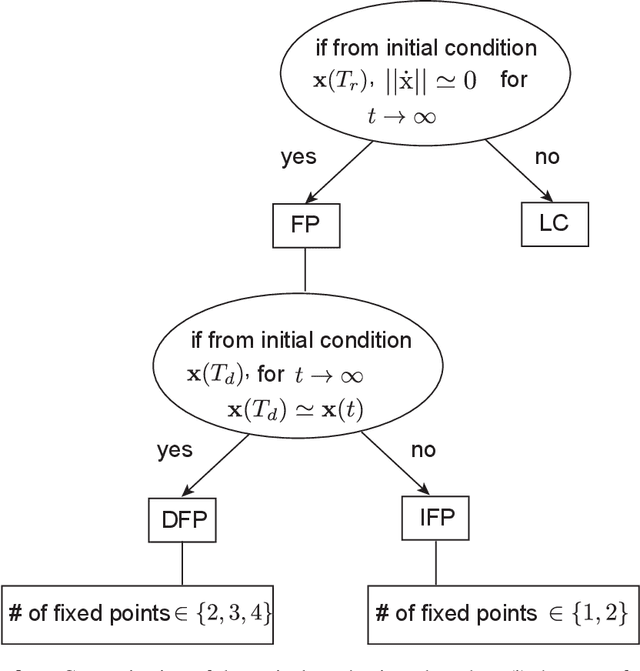
Working memory is a cognitive function involving the storage and manipulation of latent information over brief intervals of time, thus making it crucial for context-dependent computation. Here, we use a top-down modeling approach to examine network-level mechanisms of working memory, an enigmatic issue and central topic of study in neuroscience and machine intelligence. We train thousands of recurrent neural networks on a working memory task and then perform dynamical systems analysis on the ensuing optimized networks, wherein we find that four distinct dynamical mechanisms can emerge. In particular, we show the prevalence of a mechanism in which memories are encoded along slow stable manifolds in the network state space, leading to a phasic neuronal activation profile during memory periods. In contrast to mechanisms in which memories are directly encoded at stable attractors, these networks naturally forget stimuli over time. Despite this seeming functional disadvantage, they are more efficient in terms of how they leverage their attractor landscape and paradoxically, are considerably more robust to noise. Our results provide new dynamical hypotheses regarding how working memory function is encoded in both natural and artificial neural networks.