 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCUS-rPPG: A Fast-Converging Unsupervised Framework for Remote Photoplethysmography via Gradient Oscillation Suppression
Jun 02, 2026Remote photoplethysmography (rPPG) enables non-contact extraction of blood volume pulse (BVP) signals using consumer-grade cameras. Recent unsupervised rPPG methods learn BVP representations without requiring ground-truth physiological annotations, yet their optimization is often hindered by noisy and unstable gradients, resulting in slow convergence and limited cross-domain generalization. In this paper, we propose FCUS-rPPG, a fast-converging unsupervised rPPG framework with strong generalization capability. Motivated by the observation that BVP representations exhibit both multi-spectral covariation and low-dimensional manifold structure, we design a spectrally shared backbone that facilitates BVP feature disentanglement while improving optimization efficiency. To jointly enhance convergence stability and generalization performance, we further develop a unified optimization framework operating at the gradient, loss-landscape, and feature-representation levels. Specifically, a post-verification masking mechanism filters out misleading gradients according to the weak-amplitude physiological prior of BVP signals; a perturbation-based loss landscape smoothing strategy steers optimization toward more generalizable flat minima; and a noise-aware null-space regularization constrains feature updates to the orthogonal complement of the noise subspace, thereby mitigating noise-induced representation drift. Extensive experiments on five datasets demonstrate that FCUS-rPPG requires only one training epoch, whereas existing methods typically require tens to hundreds of epochs. Notably, FCUS-rPPG consistently achieves state-of-the-art (SOTA) performance in cross-dataset evaluations. This study provides an efficient and robust solution to the real-world deployment of unsupervised rPPG. The source code will be publicly available at https://github.com/JiaJieLee/FCUS-rPPG.
Adaptive Physical-Facial Representation Fusion via Subject-Invariant Cross-Modal Prompt Tuning for Video-Based Emotion Recognition
May 07, 2026Emotion recognition from facial videos enables non-contact inference of human emotional states. Although facial expressions are widely used cues, they cannot fully reflect intrinsic affective states. Remote photoplethysmography (rPPG) provides complementary physiological information, but it is highly susceptible to noise and inter-subject variability, limiting generalization to unseen individuals. Existing multimodal methods combine facial and rPPG features, yet their fusion strategies often disrupt pretrained facial representations and lack explicit mechanisms to suppress subject-specific variations. To address these issues, we propose a subject-invariant cross-modal prompt-tuning framework for video-based emotion recognition. Specifically, rPPG waveforms are transformed into noise-robust time-frequency representations (TFRs), from which modality-complementary prompts are generated to modulate facial tokens within a frozen Vision Transformer (ViT). This design enables effective cross-modal interaction while preserving the generalizable facial representations learned by the pretrained backbone. In addition, we introduce a decoupled shared-specific adapter (DSSA) into each ViT layer to explicitly separate subject-shared and subject-specific components, thereby improving cross-subject generalization. Experiments on the MAHNOB-HCI and DEAP benchmarks demonstrate that the proposed method consistently outperforms strong baselines in both recognition accuracy and generalization ability, highlighting its effectiveness for video-based emotion recognition.
SVC 2026: the Second Multimodal Deception Detection Challenge and the First Domain Generalized Remote Physiological Measurement Challenge
Apr 07, 2026Subtle visual signals, although difficult to perceive with the naked eye, contain important information that can reveal hidden patterns in visual data. These signals play a key role in many applications, including biometric security, multimedia forensics, medical diagnosis, industrial inspection, and affective computing. With the rapid development of computer vision and representation learning techniques, detecting and interpreting such subtle signals has become an emerging research direction. However, existing studies often focus on specific tasks or modalities, and models still face challenges in robustness, representation ability, and generalization when handling subtle and weak signals in real-world environments. To promote research in this area, we organize the Subtle visual Challenge, which aims to learn robust representations for subtle visual signals. The challenge includes two tasks: cross-domain multimodal deception detection and remote photoplethysmography (rPPG) estimation. We hope that this challenge will encourage the development of more robust and generalizable models for subtle visual understanding, and further advance research in computer vision and multimodal learning. A total of 22 teams submitted their final results to this workshop competition, and the corresponding baseline models have been released on the \href{https://sites.google.com/view/svc-cvpr26}{MMDD2026 platform}\footnote{https://sites.google.com/view/svc-cvpr26}
Human Detection in Realistic Through-the-Wall Environments using Raw Radar ADC Data and Parametric Neural Networks
Mar 20, 2024



The radar signal processing algorithm is one of the core components in through-wall radar human detection technology. Traditional algorithms (e.g., DFT and matched filtering) struggle to adaptively handle low signal-to-noise ratio echo signals in challenging and dynamic real-world through-wall application environments, which becomes a major bottleneck in the system. In this paper, we introduce an end-to-end through-wall radar human detection network (TWP-CNN), which takes raw radar Analog-to-Digital Converter (ADC) signals without any preprocessing as input. We replace the conventional radar signal processing flow with the proposed DFT-based adaptive feature extraction (DAFE) module. This module employs learnable parameterized 3D complex convolution layers to extract superior feature representations from ADC signals, which is beyond the limitation of traditional preprocessing methods. Additionally, by embedding phase information from radar data within the network and employing multi-task learning, a more accurate detection is achieved. Finally, due to the absence of through-wall radar datasets containing raw ADC data, we gathered a realistic through-wall (RTW) dataset using our in-house developed through-wall radar system. We trained and validated our proposed method on this dataset to confirm its effectiveness and superiority in real through-wall detection scenarios.
SOM-Net: Unrolling the Subspace-based Optimization for Solving Full-wave Inverse Scattering Problems
Sep 08, 2022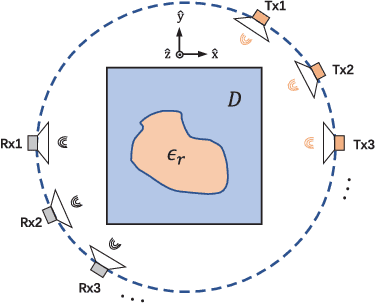
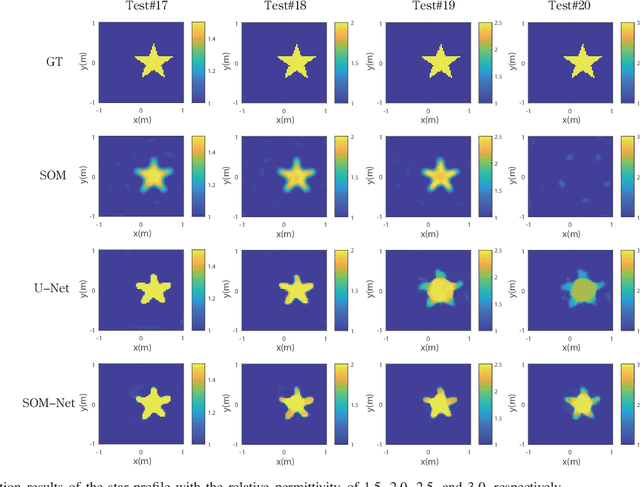
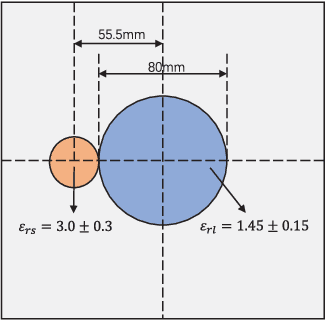
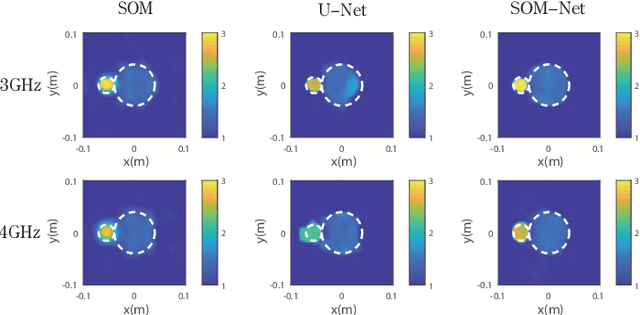
In this paper, an unrolling algorithm of the iterative subspace-based optimization method (SOM) is proposed for solving full-wave inverse scattering problems (ISPs). The unrolling network, named SOM-Net, inherently embeds the Lippmann- Schwinger physical model into the design of network structures. The SOM-Net takes the deterministic induced current and the raw permittivity image obtained from back-propagation (BP) as the input. It then updates the induced current and the permittivity successively in sub-network blocks of the SOM- Net by imitating iterations of the SOM. The final output of the SOM-Net is the full predicted induced current, from which the scattered field and the permittivity image can also be deduced analytically. The parameters of the SOM-Net are optimized in a supervised manner with the total loss to simultaneously ensure the consistency of the induced current, the scattered field, and the permittivity in the governing equations. Numerical tests on both synthetic and experimental data verify the superior performance of the proposed SOM-Net over typical ones. The results on challenging examples like scatterers with tough profiles or high permittivity demonstrate the good generalization ability of the SOM-Net. With the use of deep unrolling technology, this work builds a bridge between traditional iterative methods and deep learning methods for solving ISPs.