 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurfelSoup: Learned Point Cloud Geometry Compression With a Probablistic SurfelTree Representation
Jan 30, 2026This paper presents SurfelSoup, an end-to-end learned surface-based framework for point cloud geometry compression, with surface-structured primitives for representation. It proposes a probabilistic surface representation, pSurfel, which models local point occupancies using a bounded generalized Gaussian distribution. In addition, the pSurfels are organized into an octree-like hierarchy, pSurfelTree, with a Tree Decision module that adaptively terminates the tree subdivision for rate-distortion optimal Surfel granularity selection. This formulation avoids redundant point-wise compression in smooth regions and produces compact yet smooth surface reconstructions. Experimental results under the MPEG common test condition show consistent gain on geometry compression over voxel-based baselines and MPEG standard G-PCC-GesTM-TriSoup, while providing visually superior reconstructions with smooth and coherent surface structures.
TeSO: Representing and Compressing 3D Point Cloud Scenes with Textured Surfel Octree
Aug 09, 20253D visual content streaming is a key technology for emerging 3D telepresence and AR/VR applications. One fundamental element underlying the technology is a versatile 3D representation that is capable of producing high-quality renders and can be efficiently compressed at the same time. Existing 3D representations like point clouds, meshes and 3D Gaussians each have limitations in terms of rendering quality, surface definition, and compressibility. In this paper, we present the Textured Surfel Octree (TeSO), a novel 3D representation that is built from point clouds but addresses the aforementioned limitations. It represents a 3D scene as cube-bounded surfels organized on an octree, where each surfel is further associated with a texture patch. By approximating a smooth surface with a large surfel at a coarser level of the octree, it reduces the number of primitives required to represent the 3D scene, and yet retains the high-frequency texture details through the texture map attached to each surfel. We further propose a compression scheme to encode the geometry and texture efficiently, leveraging the octree structure. The proposed textured surfel octree combined with the compression scheme achieves higher rendering quality at lower bit-rates compared to multiple point cloud and 3D Gaussian-based baselines.
U-Motion: Learned Point Cloud Video Compression with U-Structured Motion Estimation
Nov 21, 2024



Point cloud video (PCV) is a versatile 3D representation of dynamic scenes with many emerging applications. This paper introduces U-Motion, a learning-based compression scheme for both PCV geometry and attributes. We propose a U-Structured multiscale inter-frame prediction framework, U-Inter, which performs layer-wise explicit motion estimation and compensation (ME/MC) at different scales with varying levels of detail. It integrates both higher and lower-scale motion features, in addition to the information of current and previous frames, to enable accurate motion estimation at the current scale. In addition, we design a cascaded spatial predictive coding module to capture the inter-scale spatial redundancy remaining after U-Inter prediction. We further propose an effective context detach and restore scheme to reduce spatial-temporal redundancy in the motion and latent bit-streams and improve compression performance. We conduct experiments following the MPEG Common Test Condition and demonstrate that U-Motion can achieve significant gains over MPEG G-PCC-GesTM v3.0 and recently published learning-based methods for both geometry and attribute compression.
CipherDM: Secure Three-Party Inference for Diffusion Model Sampling
Sep 09, 2024



Diffusion Models (DMs) achieve state-of-the-art synthesis results in image generation and have been applied to various fields. However, DMs sometimes seriously violate user privacy during usage, making the protection of privacy an urgent issue. Using traditional privacy computing schemes like Secure Multi-Party Computation (MPC) directly in DMs faces significant computation and communication challenges. To address these issues, we propose CipherDM, the first novel, versatile and universal framework applying MPC technology to DMs for secure sampling, which can be widely implemented on multiple DM based tasks. We thoroughly analyze sampling latency breakdown, find time-consuming parts and design corresponding secure MPC protocols for computing nonlinear activations including SoftMax, SiLU and Mish. CipherDM is evaluated on popular architectures (DDPM, DDIM) using MNIST dataset and on SD deployed by diffusers. Compared to direct implementation on SPU, our approach improves running time by approximately 1.084\times \sim 2.328\times, and reduces communication costs by approximately 1.212\times \sim 1.791\times.
Learning Dynamic Point Cloud Compression via Hierarchical Inter-frame Block Matching
May 16, 2023



3D dynamic point cloud (DPC) compression relies on mining its temporal context, which faces significant challenges due to DPC's sparsity and non-uniform structure. Existing methods are limited in capturing sufficient temporal dependencies. Therefore, this paper proposes a learning-based DPC compression framework via hierarchical block-matching-based inter-prediction module to compensate and compress the DPC geometry in latent space. Specifically, we propose a hierarchical motion estimation and motion compensation (Hie-ME/MC) framework for flexible inter-prediction, which dynamically selects the granularity of optical flow to encapsulate the motion information accurately. To improve the motion estimation efficiency of the proposed inter-prediction module, we further design a KNN-attention block matching (KABM) network that determines the impact of potential corresponding points based on the geometry and feature correlation. Finally, we compress the residual and the multi-scale optical flow with a fully-factorized deep entropy model. The experiment result on the MPEG-specified Owlii Dynamic Human Dynamic Point Cloud (Owlii) dataset shows that our framework outperforms the previous state-of-the-art methods and the MPEG standard V-PCC v18 in inter-frame low-delay mode.
Multiscale Latent-Guided Entropy Model for LiDAR Point Cloud Compression
Sep 26, 2022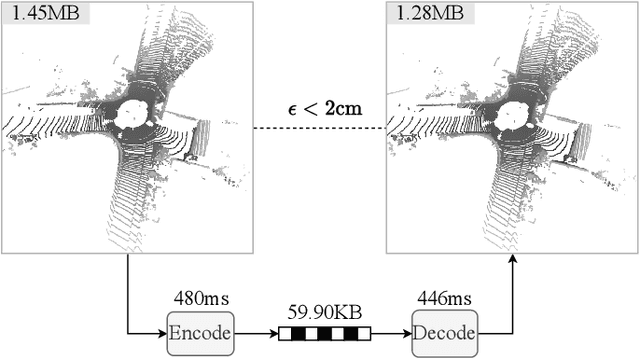
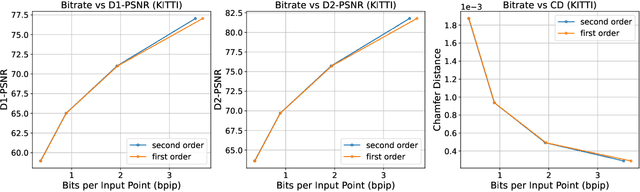
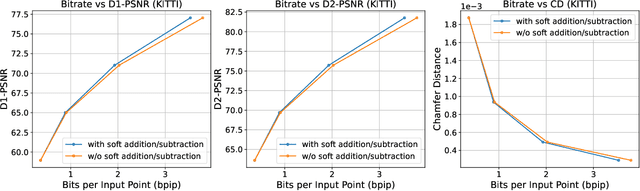

The non-uniform distribution and extremely sparse nature of the LiDAR point cloud (LPC) bring significant challenges to its high-efficient compression. This paper proposes a novel end-to-end, fully-factorized deep framework that encodes the original LPC into an octree structure and hierarchically decomposes the octree entropy model in layers. The proposed framework utilizes a hierarchical latent variable as side information to encapsulate the sibling and ancestor dependence, which provides sufficient context information for the modelling of point cloud distribution while enabling the parallel encoding and decoding of octree nodes in the same layer. Besides, we propose a residual coding framework for the compression of the latent variable, which explores the spatial correlation of each layer by progressive downsampling, and model the corresponding residual with a fully-factorized entropy model. Furthermore, we propose soft addition and subtraction for residual coding to improve network flexibility. The comprehensive experiment results on the LiDAR benchmark SemanticKITTI and MPEG-specified dataset Ford demonstrates that our proposed framework achieves state-of-the-art performance among all the previous LPC frameworks. Besides, our end-to-end, fully-factorized framework is proved by experiment to be high-parallelized and time-efficient and saves more than 99.8% of decoding time compared to previous state-of-the-art methods on LPC compression.
D-DPCC: Deep Dynamic Point Cloud Compression via 3D Motion Prediction
May 02, 2022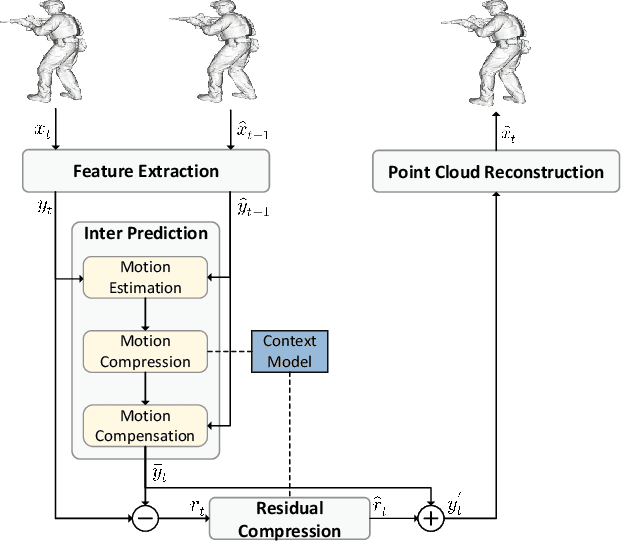
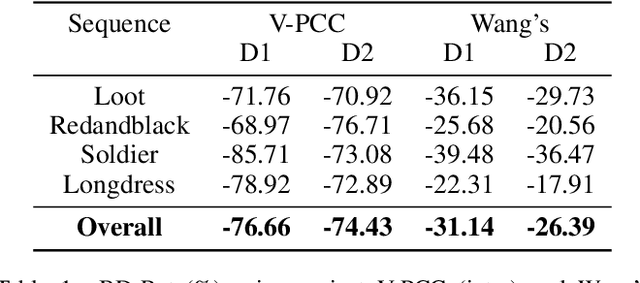
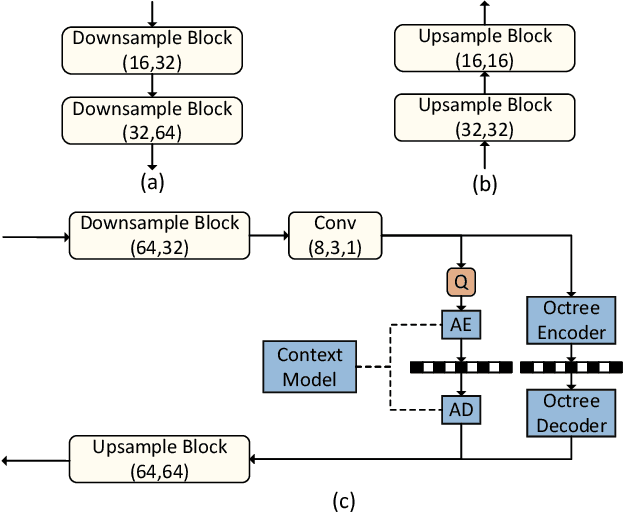
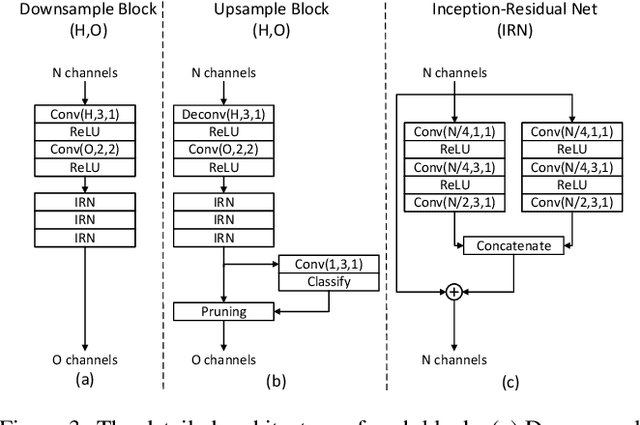
The non-uniformly distributed nature of the 3D dynamic point cloud (DPC) brings significant challenges to its high-efficient inter-frame compression. This paper proposes a novel 3D sparse convolution-based Deep Dynamic Point Cloud Compression (D-DPCC) network to compensate and compress the DPC geometry with 3D motion estimation and motion compensation in the feature space. In the proposed D-DPCC network, we design a {\it Multi-scale Motion Fusion} (MMF) module to accurately estimate the 3D optical flow between the feature representations of adjacent point cloud frames. Specifically, we utilize a 3D sparse convolution-based encoder to obtain the latent representation for motion estimation in the feature space and introduce the proposed MMF module for fused 3D motion embedding. Besides, for motion compensation, we propose a 3D {\it Adaptively Weighted Interpolation} (3DAWI) algorithm with a penalty coefficient to adaptively decrease the impact of distant neighbors. We compress the motion embedding and the residual with a lossy autoencoder-based network. To our knowledge, this paper is the first work proposing an end-to-end deep dynamic point cloud compression framework. The experimental result shows that the proposed D-DPCC framework achieves an average 76\% BD-Rate (Bjontegaard Delta Rate) gains against state-of-the-art Video-based Point Cloud Compression (V-PCC) v13 in inter mode.