 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning 1D Causal Visual Representation with De-focus Attention Networks
Jun 06, 2024Modality differences have led to the development of heterogeneous architectures for vision and language models. While images typically require 2D non-causal modeling, texts utilize 1D causal modeling. This distinction poses significant challenges in constructing unified multi-modal models. This paper explores the feasibility of representing images using 1D causal modeling. We identify an "over-focus" issue in existing 1D causal vision models, where attention overly concentrates on a small proportion of visual tokens. The issue of "over-focus" hinders the model's ability to extract diverse visual features and to receive effective gradients for optimization. To address this, we propose De-focus Attention Networks, which employ learnable bandpass filters to create varied attention patterns. During training, large and scheduled drop path rates, and an auxiliary loss on globally pooled features for global understanding tasks are introduced. These two strategies encourage the model to attend to a broader range of tokens and enhance network optimization. Extensive experiments validate the efficacy of our approach, demonstrating that 1D causal visual representation can perform comparably to 2D non-causal representation in tasks such as global perception, dense prediction, and multi-modal understanding. Code is released at https://github.com/OpenGVLab/De-focus-Attention-Networks.
Counting-Stars: A Simple, Efficient, and Reasonable Strategy for Evaluating Long-Context Large Language Models
Mar 25, 2024

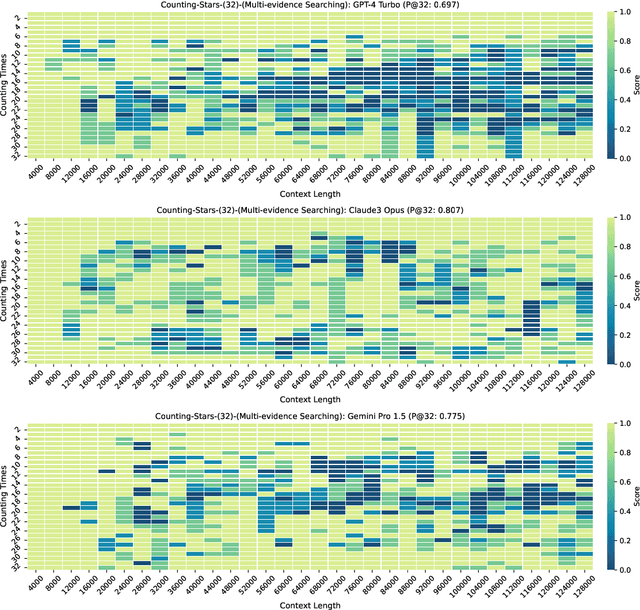
While recent research endeavors have concentrated on developing Large Language Models (LLMs) with robust long-context capabilities, due to the lack of appropriate evaluation strategies, relatively little is known about how well the long-context capability and performance of leading LLMs (e.g., GPT-4 Turbo and Kimi Chat). To address this gap, we propose a simple, efficient, and reasonable strategy for evaluating long-context LLMs as a new benchmark, named Counting-Stars. The Counting-Stars is designed to require LLMs to fully understand and capture long dependencies in long contexts, further being able to collect inter-dependency across multiple pieces of evidence spanning the entire context to finish the task. Based on the Counting-Stars, we conduct experiments to evaluate the two leading long-context LLMs, i.e., GPT-4 Turbo and Kimi Chat. The experimental results indicate that GPT-4 Turbo and Kimi Chat achieve significant performance in the long context from 4K to 128K. We further present several intriguing analyses regarding the behavior of LLMs processing long context.
Memory efficient location recommendation through proximity-aware representation
Oct 24, 2023



Sequential location recommendation plays a huge role in modern life, which can enhance user experience, bring more profit to businesses and assist in government administration. Although methods for location recommendation have evolved significantly thanks to the development of recommendation systems, there is still limited utilization of geographic information, along with the ongoing challenge of addressing data sparsity. In response, we introduce a Proximity-aware based region representation for Sequential Recommendation (PASR for short), built upon the Self-Attention Network architecture. We tackle the sparsity issue through a novel loss function employing importance sampling, which emphasizes informative negative samples during optimization. Moreover, PASR enhances the integration of geographic information by employing a self-attention-based geography encoder to the hierarchical grid and proximity grid at each GPS point. To further leverage geographic information, we utilize the proximity-aware negative samplers to enhance the quality of negative samples. We conducted evaluations using three real-world Location-Based Social Networking (LBSN) datasets, demonstrating that PASR surpasses state-of-the-art sequential location recommendation methods
Bot or Human? Detecting ChatGPT Imposters with A Single Question
May 16, 2023


Large language models like ChatGPT have recently demonstrated impressive capabilities in natural language understanding and generation, enabling various applications including translation, essay writing, and chit-chatting. However, there is a concern that they can be misused for malicious purposes, such as fraud or denial-of-service attacks. Therefore, it is crucial to develop methods for detecting whether the party involved in a conversation is a bot or a human. In this paper, we propose a framework named FLAIR, Finding Large language model Authenticity via a single Inquiry and Response, to detect conversational bots in an online manner. Specifically, we target a single question scenario that can effectively differentiate human users from bots. The questions are divided into two categories: those that are easy for humans but difficult for bots (e.g., counting, substitution, positioning, noise filtering, and ASCII art), and those that are easy for bots but difficult for humans (e.g., memorization and computation). Our approach shows different strengths of these questions in their effectiveness, providing a new way for online service providers to protect themselves against nefarious activities and ensure that they are serving real users. We open-sourced our dataset on https://github.com/hongwang600/FLAIR and welcome contributions from the community to enrich such detection datasets.
STOA-VLP: Spatial-Temporal Modeling of Object and Action for Video-Language Pre-training
Feb 20, 2023



Although large-scale video-language pre-training models, which usually build a global alignment between the video and the text, have achieved remarkable progress on various downstream tasks, the idea of adopting fine-grained information during the pre-training stage is not well explored. In this work, we propose STOA-VLP, a pre-training framework that jointly models object and action information across spatial and temporal dimensions. More specifically, the model regards object trajectories across frames and multiple action features from the video as fine-grained features. Besides, We design two auxiliary tasks to better incorporate both kinds of information into the pre-training process of the video-language model. The first is the dynamic object-text alignment task, which builds a better connection between object trajectories and the relevant noun tokens. The second is the spatial-temporal action set prediction, which guides the model to generate consistent action features by predicting actions found in the text. Extensive experiments on three downstream tasks (video captioning, text-video retrieval, and video question answering) demonstrate the effectiveness of our proposed STOA-VLP (e.g. 3.7 Rouge-L improvements on MSR-VTT video captioning benchmark, 2.9% accuracy improvements on MSVD video question answering benchmark, compared to previous approaches).
Consistent Style Transfer
Jan 06, 2022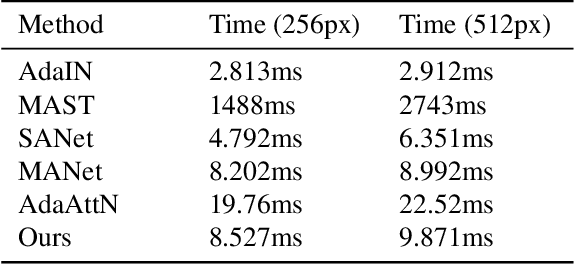
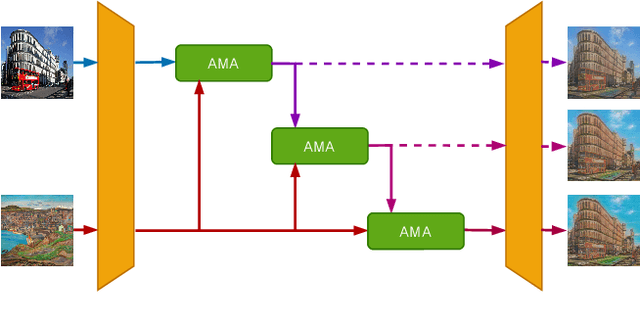

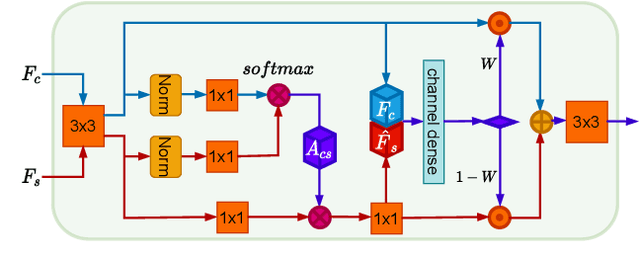
Recently, attentional arbitrary style transfer methods have been proposed to achieve fine-grained results, which manipulates the point-wise similarity between content and style features for stylization. However, the attention mechanism based on feature points ignores the feature multi-manifold distribution, where each feature manifold corresponds to a semantic region in the image. Consequently, a uniform content semantic region is rendered by highly different patterns from various style semantic regions, producing inconsistent stylization results with visual artifacts. We proposed the progressive attentional manifold alignment (PAMA) to alleviate this problem, which repeatedly applies attention operations and space-aware interpolations. The attention operation rearranges style features dynamically according to the spatial distribution of content features. This makes the content and style manifolds correspond on the feature map. Then the space-aware interpolation adaptively interpolates between the corresponding content and style manifolds to increase their similarity. By gradually aligning the content manifolds to style manifolds, the proposed PAMA achieves state-of-the-art performance while avoiding the inconsistency of semantic regions. Codes are available at https://github.com/computer-vision2022/PAMA.
StyleSDF: High-Resolution 3D-Consistent Image and Geometry Generation
Dec 21, 2021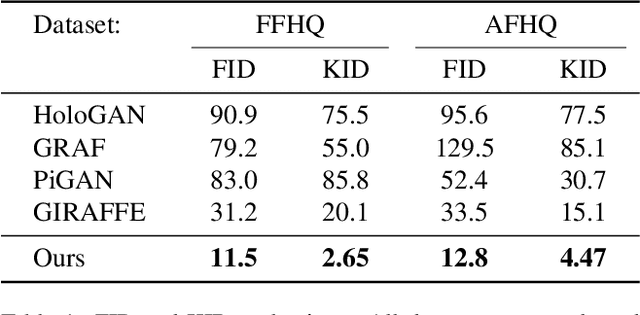
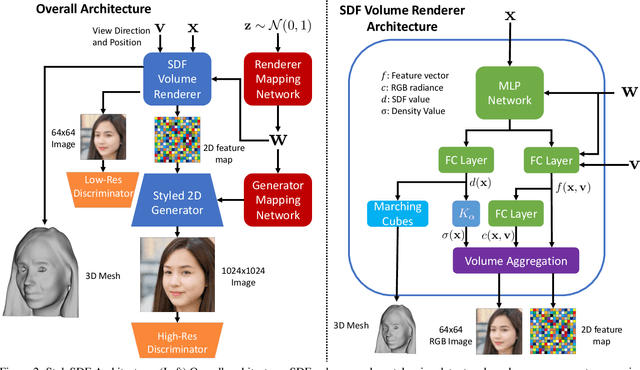


We introduce a high resolution, 3D-consistent image and shape generation technique which we call StyleSDF. Our method is trained on single-view RGB data only, and stands on the shoulders of StyleGAN2 for image generation, while solving two main challenges in 3D-aware GANs: 1) high-resolution, view-consistent generation of the RGB images, and 2) detailed 3D shape. We achieve this by merging a SDF-based 3D representation with a style-based 2D generator. Our 3D implicit network renders low-resolution feature maps, from which the style-based network generates view-consistent, 1024x1024 images. Notably, our SDF-based 3D modeling defines detailed 3D surfaces, leading to consistent volume rendering. Our method shows higher quality results compared to state of the art in terms of visual and geometric quality.
Data Pricing in Machine Learning Pipelines
Aug 18, 2021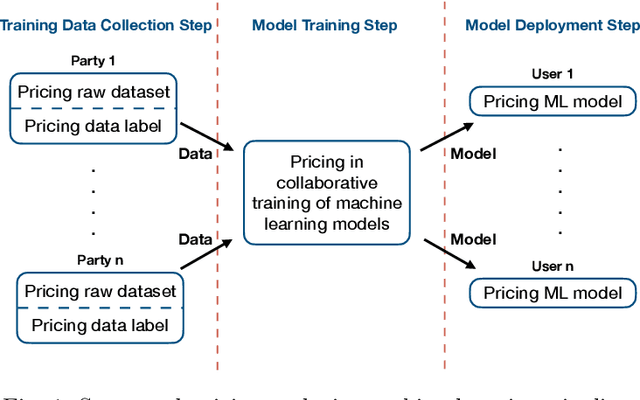
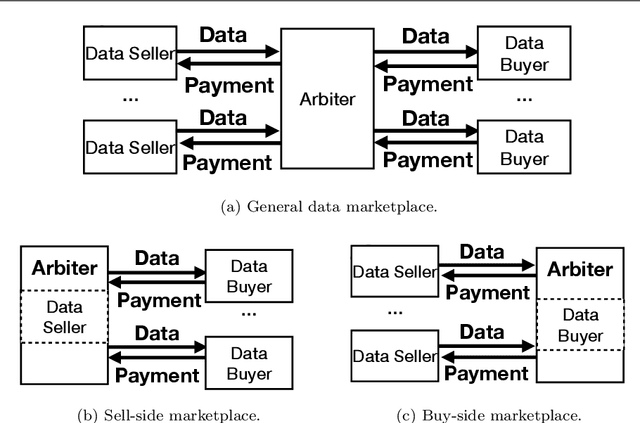
Machine learning is disruptive. At the same time, machine learning can only succeed by collaboration among many parties in multiple steps naturally as pipelines in an eco-system, such as collecting data for possible machine learning applications, collaboratively training models by multiple parties and delivering machine learning services to end users. Data is critical and penetrating in the whole machine learning pipelines. As machine learning pipelines involve many parties and, in order to be successful, have to form a constructive and dynamic eco-system, marketplaces and data pricing are fundamental in connecting and facilitating those many parties. In this article, we survey the principles and the latest research development of data pricing in machine learning pipelines. We start with a brief review of data marketplaces and pricing desiderata. Then, we focus on pricing in three important steps in machine learning pipelines. To understand pricing in the step of training data collection, we review pricing raw data sets and data labels. We also investigate pricing in the step of collaborative training of machine learning models, and overview pricing machine learning models for end users in the step of machine learning deployment. We also discuss a series of possible future directions.
RL-CSDia: Representation Learning of Computer Science Diagrams
Mar 10, 2021
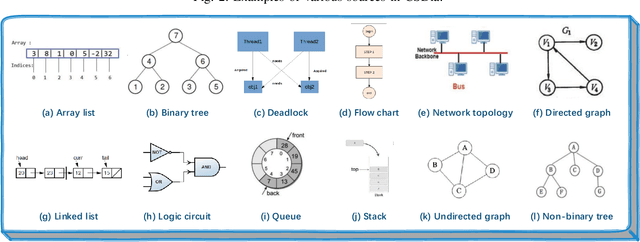
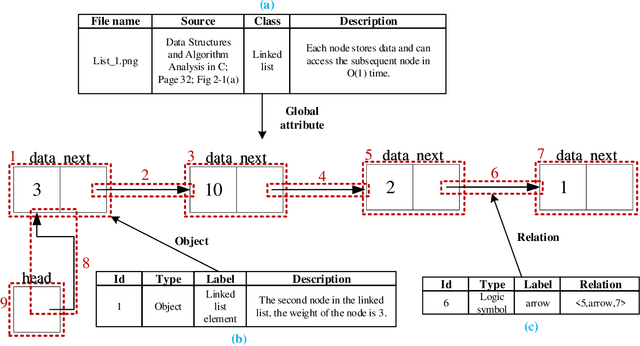
Recent studies on computer vision mainly focus on natural images that express real-world scenes. They achieve outstanding performance on diverse tasks such as visual question answering. Diagram is a special form of visual expression that frequently appears in the education field and is of great significance for learners to understand multimodal knowledge. Current research on diagrams preliminarily focuses on natural disciplines such as Biology and Geography, whose expressions are still similar to natural images. Another type of diagrams such as from Computer Science is composed of graphics containing complex topologies and relations, and research on this type of diagrams is still blank. The main challenges of graphic diagrams understanding are the rarity of data and the confusion of semantics, which are mainly reflected in the diversity of expressions. In this paper, we construct a novel dataset of graphic diagrams named Computer Science Diagrams (CSDia). It contains more than 1,200 diagrams and exhaustive annotations of objects and relations. Considering the visual noises caused by the various expressions in diagrams, we introduce the topology of diagrams to parse topological structure. After that, we propose Diagram Parsing Net (DPN) to represent the diagram from three branches: topology, visual feature, and text, and apply the model to the diagram classification task to evaluate the ability of diagrams understanding. The results show the effectiveness of the proposed DPN on diagrams understanding.
Time-Travel Rephotography
Dec 22, 2020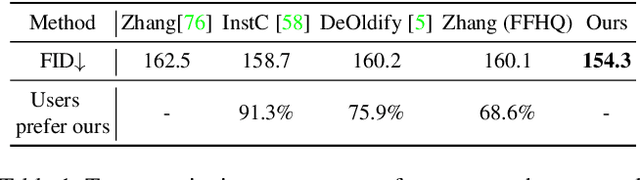
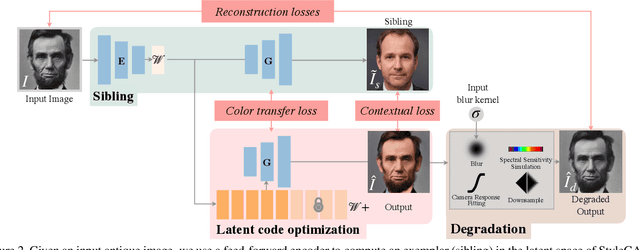


Many historical people are captured only in old, faded, black and white photos, that have been distorted by the limitations of early cameras and the passage of time. This paper simulates traveling back in time with a modern camera to rephotograph famous subjects. Unlike conventional image restoration filters which apply independent operations like denoising, colorization, and superresolution, we leverage the StyleGAN2 framework to project old photos into the space of modern high-resolution photos, achieving all of these effects in a unified framework. A unique challenge with this approach is capturing the identity and pose of the photo's subject and not the many artifacts in low-quality antique photos. Our comparisons to current state-of-the-art restoration filters show significant improvements and compelling results for a variety of important historical people.