 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTOA-VLP: Spatial-Temporal Modeling of Object and Action for Video-Language Pre-training
Feb 20, 2023



Although large-scale video-language pre-training models, which usually build a global alignment between the video and the text, have achieved remarkable progress on various downstream tasks, the idea of adopting fine-grained information during the pre-training stage is not well explored. In this work, we propose STOA-VLP, a pre-training framework that jointly models object and action information across spatial and temporal dimensions. More specifically, the model regards object trajectories across frames and multiple action features from the video as fine-grained features. Besides, We design two auxiliary tasks to better incorporate both kinds of information into the pre-training process of the video-language model. The first is the dynamic object-text alignment task, which builds a better connection between object trajectories and the relevant noun tokens. The second is the spatial-temporal action set prediction, which guides the model to generate consistent action features by predicting actions found in the text. Extensive experiments on three downstream tasks (video captioning, text-video retrieval, and video question answering) demonstrate the effectiveness of our proposed STOA-VLP (e.g. 3.7 Rouge-L improvements on MSR-VTT video captioning benchmark, 2.9% accuracy improvements on MSVD video question answering benchmark, compared to previous approaches).
Controllable Text Generation via Probability Density Estimation in the Latent Space
Dec 16, 2022



Previous work on controllable text generation has explored the idea of control from the latent space, such as optimizing a representation with attribute-related classifiers or sampling a representation from relevant discrete samples. However, they are not effective enough in modeling both the latent space and the control, leaving controlled text with low quality and diversity. In this work, we propose a novel control framework using probability density estimation in the latent space. Our method utilizes an invertible transformation function, the Normalizing Flow, that maps the complex distributions in the latent space to simple Gaussian distributions in the prior space. Thus, we can perform sophisticated and flexible control in the prior space and feed the control effects back into the latent space owing to the one-one-mapping property of invertible transformations. Experiments on single-attribute controls and multi-attribute control reveal that our method outperforms several strong baselines on attribute relevance and text quality and achieves the SOTA. Further analysis of control strength adjustment demonstrates the flexibility of our control strategy.
A Distributional Lens for Multi-Aspect Controllable Text Generation
Oct 06, 2022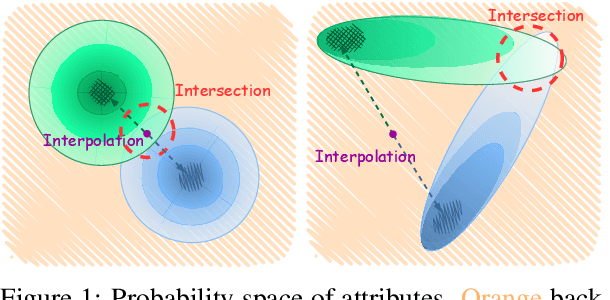
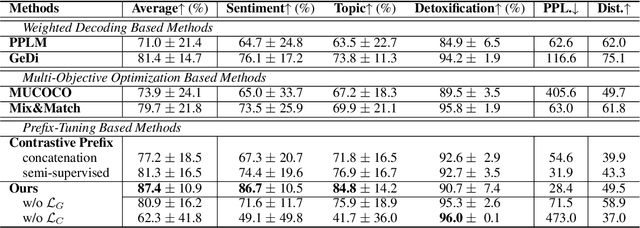
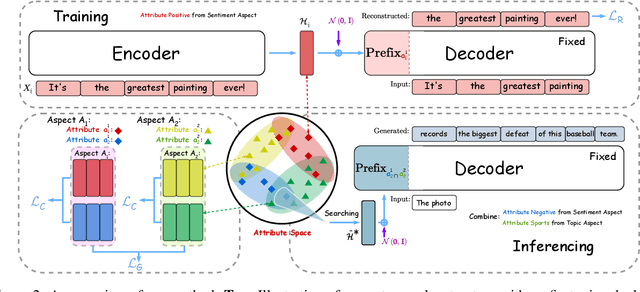
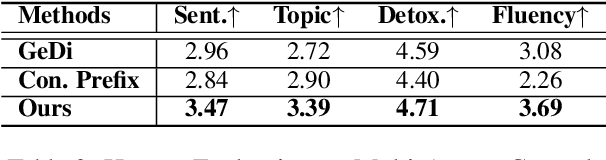
Multi-aspect controllable text generation is a more challenging and practical task than single-aspect control. Existing methods achieve complex multi-aspect control by fusing multiple controllers learned from single-aspect, but suffer from attribute degeneration caused by the mutual interference of these controllers. To address this, we provide observations on attribute fusion from a distributional perspective and propose to directly search for the intersection areas of multiple attribute distributions as their combination for generation. Our method first estimates the attribute space with an autoencoder structure. Afterward, we iteratively approach the intersections by jointly minimizing distances to points representing different attributes. Finally, we map them to attribute-relevant sentences with a prefix-tuning-based decoder. Experiments on the three-aspect control task, including sentiment, topic, and detoxification aspects, reveal that our method outperforms several strong baselines on attribute relevance and text quality and achieves the SOTA. Further analysis also supplies some explanatory support for the effectiveness of our approach.
Learning to Select Bi-Aspect Information for Document-Scale Text Content Manipulation
Feb 24, 2020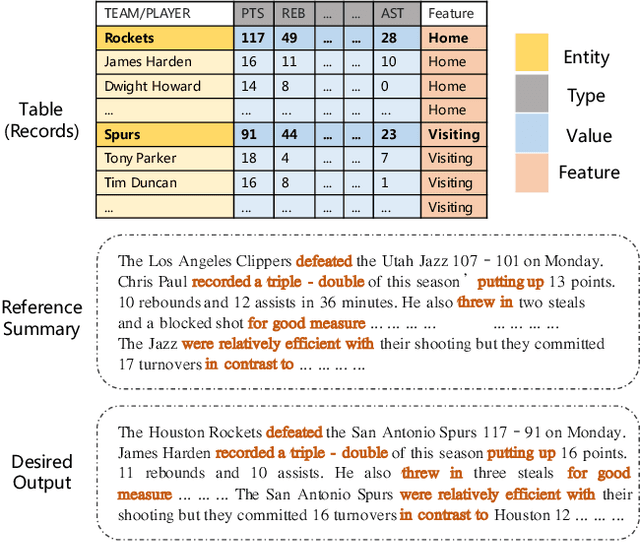
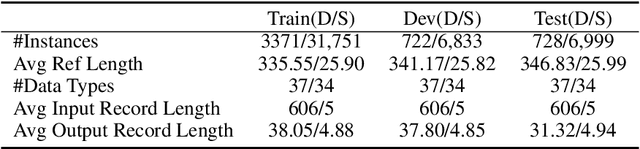
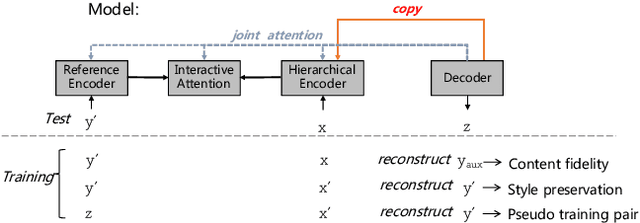
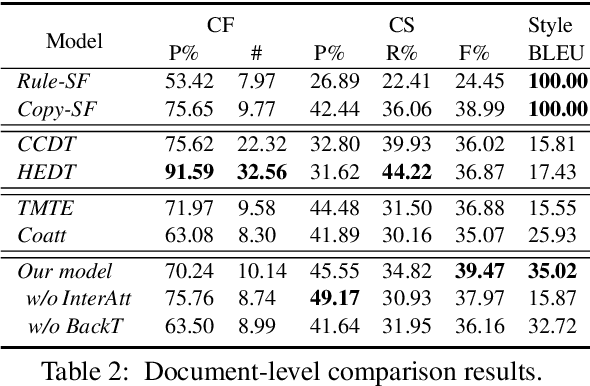
In this paper, we focus on a new practical task, document-scale text content manipulation, which is the opposite of text style transfer and aims to preserve text styles while altering the content. In detail, the input is a set of structured records and a reference text for describing another recordset. The output is a summary that accurately describes the partial content in the source recordset with the same writing style of the reference. The task is unsupervised due to lack of parallel data, and is challenging to select suitable records and style words from bi-aspect inputs respectively and generate a high-fidelity long document. To tackle those problems, we first build a dataset based on a basketball game report corpus as our testbed, and present an unsupervised neural model with interactive attention mechanism, which is used for learning the semantic relationship between records and reference texts to achieve better content transfer and better style preservation. In addition, we also explore the effectiveness of the back-translation in our task for constructing some pseudo-training pairs. Empirical results show superiority of our approaches over competitive methods, and the models also yield a new state-of-the-art result on a sentence-level dataset.
Table-to-Text Generation with Effective Hierarchical Encoder on Three Dimensions (Row, Column and Time)
Sep 05, 2019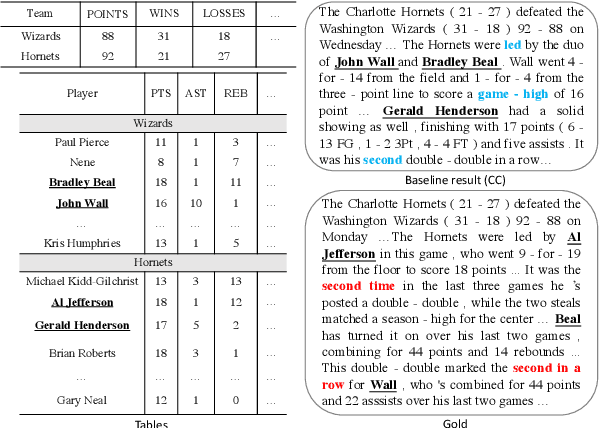
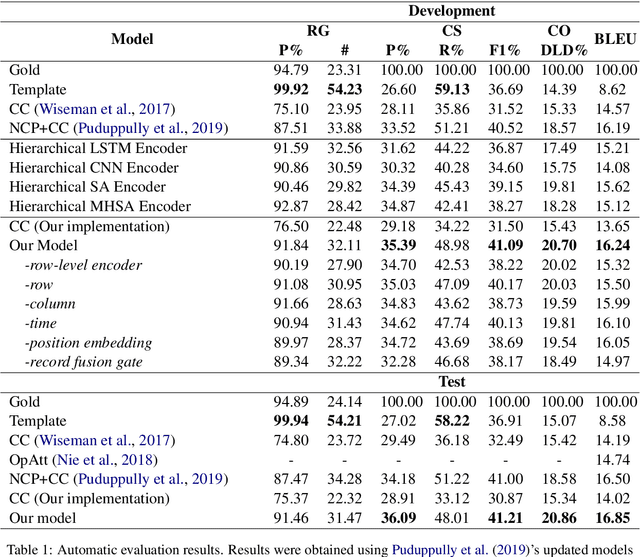
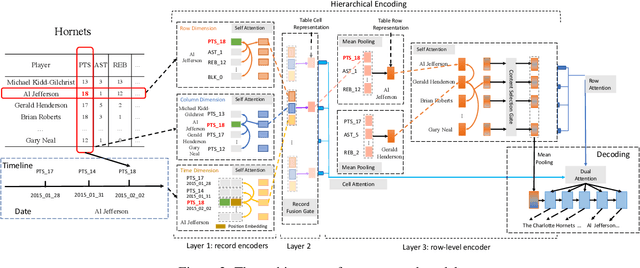
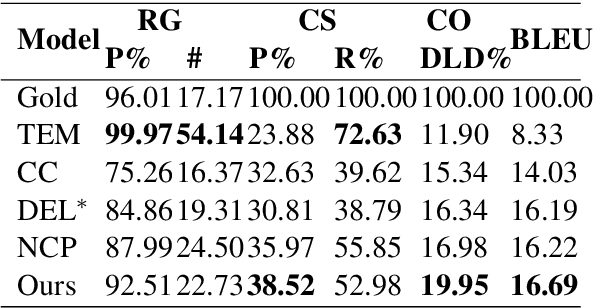
Although Seq2Seq models for table-to-text generation have achieved remarkable progress, modeling table representation in one dimension is inadequate. This is because (1) the table consists of multiple rows and columns, which means that encoding a table should not depend only on one dimensional sequence or set of records and (2) most of the tables are time series data (e.g. NBA game data, stock market data), which means that the description of the current table may be affected by its historical data. To address aforementioned problems, not only do we model each table cell considering other records in the same row, we also enrich table's representation by modeling each table cell in context of other cells in the same column or with historical (time dimension) data respectively. In addition, we develop a table cell fusion gate to combine representations from row, column and time dimension into one dense vector according to the saliency of each dimension's representation. We evaluated our methods on ROTOWIRE, a benchmark dataset of NBA basketball games. Both automatic and human evaluation results demonstrate the effectiveness of our model with improvement of 2.66 in BLEU over the strong baseline and outperformance of state-of-the-art model.