 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding BROOK: A Multi-modal and Facial Video Database for Human-Vehicle Interaction Research
May 19, 2020

With the growing popularity of Autonomous Vehicles, more opportunities have bloomed in the context of Human-Vehicle Interactions. However, the lack of comprehensive and concrete database support for such specific use case limits relevant studies in the whole design spaces. In this paper, we present our work-in-progress BROOK, a public multi-modal database with facial video records, which could be used to characterize drivers' affective states and driving styles. We first explain how we over-engineer such database in details, and what we have gained through a ten-month study. Then we showcase a Neural Network-based predictor, leveraging BROOK, which supports multi-modal prediction (including physiological data of heart rate and skin conductance and driving status data of speed)through facial videos. Finally, we discuss related issues when building such a database and our future directions in the context of BROOK. We believe BROOK is an essential building block for future Human-Vehicle Interaction Research.
Parallel Data Augmentation for Formality Style Transfer
May 14, 2020
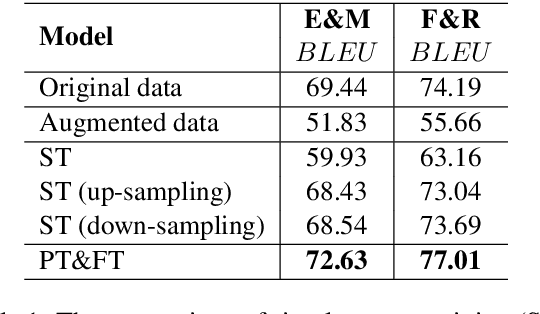

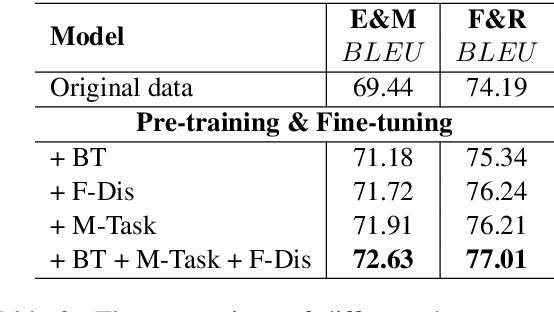
The main barrier to progress in the task of Formality Style Transfer is the inadequacy of training data. In this paper, we study how to augment parallel data and propose novel and simple data augmentation methods for this task to obtain useful sentence pairs with easily accessible models and systems. Experiments demonstrate that our augmented parallel data largely helps improve formality style transfer when it is used to pre-train the model, leading to the state-of-the-art results in the GYAFC benchmark dataset.
AGE Challenge: Angle Closure Glaucoma Evaluation in Anterior Segment Optical Coherence Tomography
May 05, 2020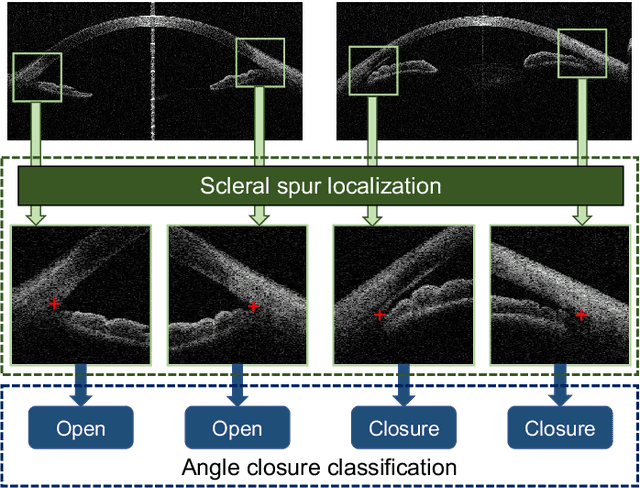
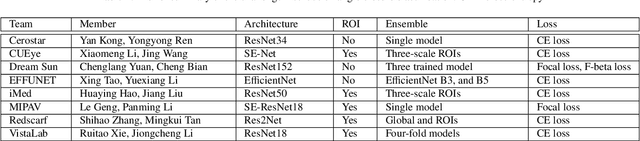
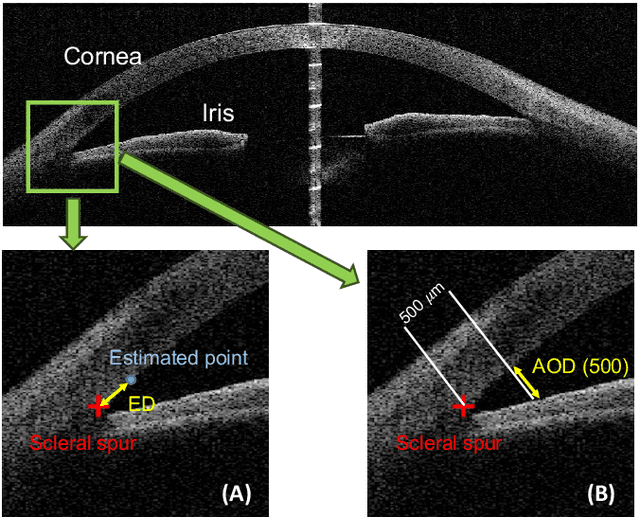
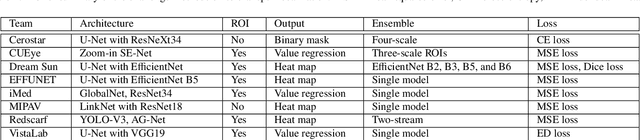
Angle closure glaucoma (ACG) is a more aggressive disease than open-angle glaucoma, where the abnormal anatomical structures of the anterior chamber angle (ACA) may cause an elevated intraocular pressure and gradually leads to glaucomatous optic neuropathy and eventually to visual impairment and blindness. Anterior Segment Optical Coherence Tomography (AS-OCT) imaging provides a fast and contactless way to discriminate angle closure from open angle. Although many medical image analysis algorithms have been developed for glaucoma diagnosis, only a few studies have focused on AS-OCT imaging. In particular, there is no public AS-OCT dataset available for evaluating the existing methods in a uniform way, which limits the progress in the development of automated techniques for angle closure detection and assessment. To address this, we organized the Angle closure Glaucoma Evaluation challenge (AGE), held in conjunction with MICCAI 2019. The AGE challenge consisted of two tasks: scleral spur localization and angle closure classification. For this challenge, we released a large data of 4800 annotated AS-OCT images from 199 patients, and also proposed an evaluation framework to benchmark and compare different models. During the AGE challenge, over 200 teams registered online, and more than 1100 results were submitted for online evaluation. Finally, eight teams participated in the onsite challenge. In this paper, we summarize these eight onsite challenge methods and analyze their corresponding results in the two tasks. We further discuss limitations and future directions. In the AGE challenge, the top-performing approach had an average Euclidean Distance of 10 pixel in scleral spur localization, while in the task of angle closure classification, all the algorithms achieved the satisfactory performances, especially, 100% accuracy rate for top-two performances.
Query-Variant Advertisement Text Generation with Association Knowledge
Apr 14, 2020

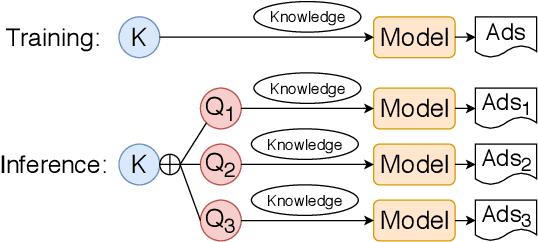
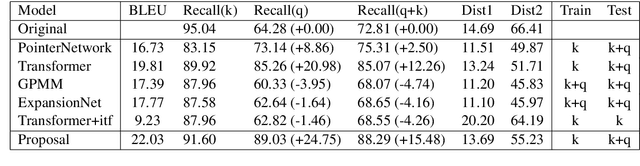
Advertising is an important revenue source for many companies. However, it is expensive to manually create advertisements that meet the needs of various queries for massive items. In this paper, we propose the query-variant advertisement text generation task that aims to generate candidate advertisements for different queries with various needs given the item keywords. In this task, for many different queries there is only one general purposed advertisement with no predefined query-advertisement pair, which would discourage traditional End-to-End models from generating query-variant advertisements for different queries with different needs. To deal with the problem, we propose a query-variant advertisement text generation model that takes keywords and associated external knowledge as input during training and adds different queries during inference. Adding external knowledge helps the model adapted to the information besides the item keywords during training, which makes the transition between training and inference more smoothing when the query is added during inference. Both automatic and human evaluation show that our model can generate more attractive and query-focused advertisements than the strong baselines.
Jointly Modeling Aspect and Sentiment with Dynamic Heterogeneous Graph Neural Networks
Apr 14, 2020


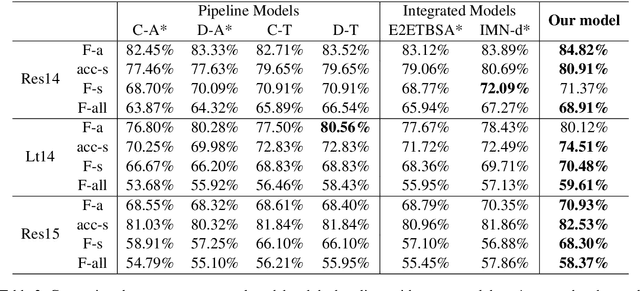
Target-Based Sentiment Analysis aims to detect the opinion aspects (aspect extraction) and the sentiment polarities (sentiment detection) towards them. Both the previous pipeline and integrated methods fail to precisely model the innate connection between these two objectives. In this paper, we propose a novel dynamic heterogeneous graph to jointly model the two objectives in an explicit way. Both the ordinary words and sentiment labels are treated as nodes in the heterogeneous graph, so that the aspect words can interact with the sentiment information. The graph is initialized with multiple types of dependencies, and dynamically modified during real-time prediction. Experiments on the benchmark datasets show that our model outperforms the state-of-the-art models. Further analysis demonstrates that our model obtains significant performance gain on the challenging instances under multiple-opinion aspects and no-opinion aspect situations.
Exploring and Distilling Cross-Modal Information for Image Captioning
Mar 15, 2020
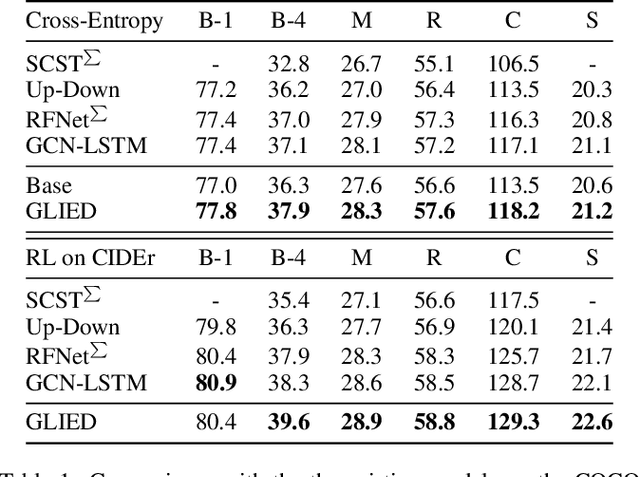
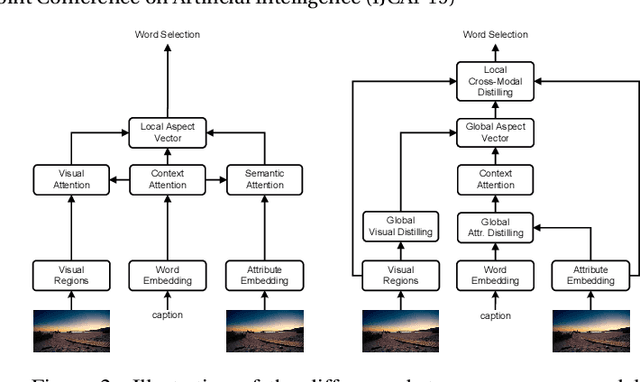
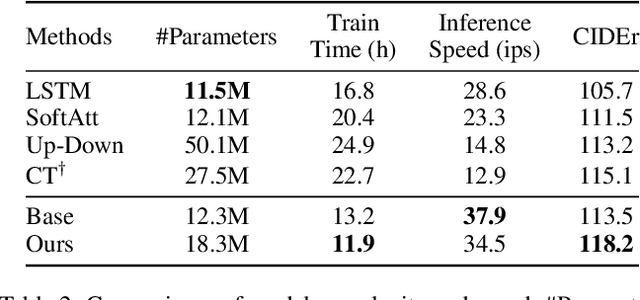
Recently, attention-based encoder-decoder models have been used extensively in image captioning. Yet there is still great difficulty for the current methods to achieve deep image understanding. In this work, we argue that such understanding requires visual attention to correlated image regions and semantic attention to coherent attributes of interest. Based on the Transformer, to perform effective attention, we explore image captioning from a cross-modal perspective and propose the Global-and-Local Information Exploring-and-Distilling approach that explores and distills the source information in vision and language. It globally provides the aspect vector, a spatial and relational representation of images based on caption contexts, through the extraction of salient region groupings and attribute collocations, and locally extracts the fine-grained regions and attributes in reference to the aspect vector for word selection. Our Transformer-based model achieves a CIDEr score of 129.3 in offline COCO evaluation on the COCO testing set with remarkable efficiency in terms of accuracy, speed, and parameter budget.
Mining Commonsense Facts from the Physical World
Feb 11, 2020
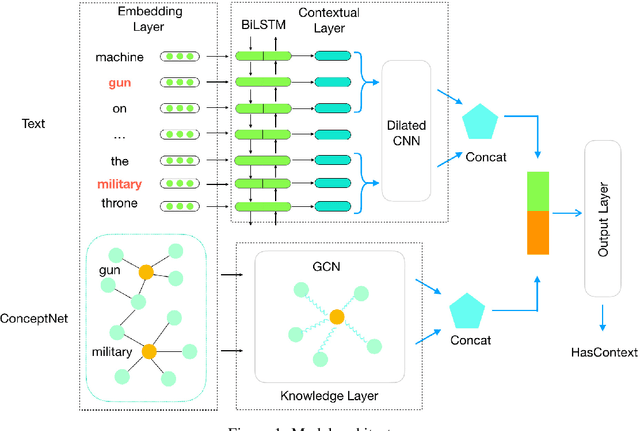
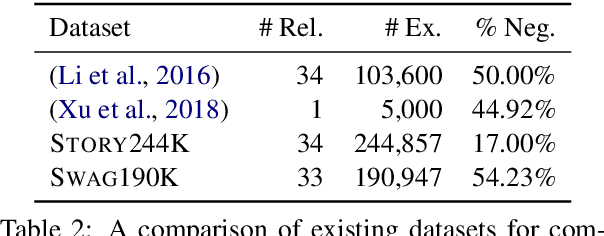
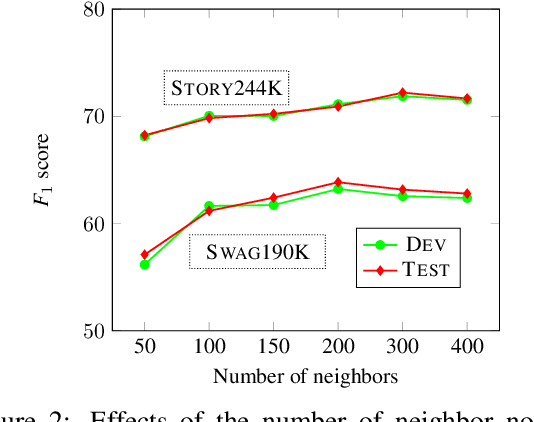
Textual descriptions of the physical world implicitly mention commonsense facts, while the commonsense knowledge bases explicitly represent such facts as triples. Compared to dramatically increased text data, the coverage of existing knowledge bases is far away from completion. Most of the prior studies on populating knowledge bases mainly focus on Freebase. To automatically complete commonsense knowledge bases to improve their coverage is under-explored. In this paper, we propose a new task of mining commonsense facts from the raw text that describes the physical world. We build an effective new model that fuses information from both sequence text and existing knowledge base resource. Then we create two large annotated datasets each with approximate 200k instances for commonsense knowledge base completion. Empirical results demonstrate that our model significantly outperforms baselines.
Visual Agreement Regularized Training for Multi-Modal Machine Translation
Dec 27, 2019
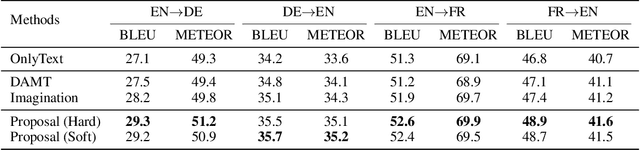
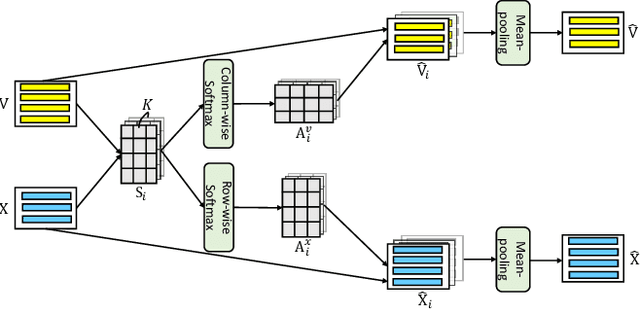
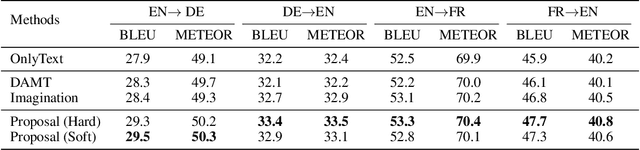
Multi-modal machine translation aims at translating the source sentence into a different language in the presence of the paired image. Previous work suggests that additional visual information only provides dispensable help to translation, which is needed in several very special cases such as translating ambiguous words. To make better use of visual information, this work presents visual agreement regularized training. The proposed approach jointly trains the source-to-target and target-to-source translation models and encourages them to share the same focus on the visual information when generating semantically equivalent visual words (e.g. "ball" in English and "ballon" in French). Besides, a simple yet effective multi-head co-attention model is also introduced to capture interactions between visual and textual features. The results show that our approaches can outperform competitive baselines by a large margin on the Multi30k dataset. Further analysis demonstrates that the proposed regularized training can effectively improve the agreement of attention on the image, leading to better use of visual information.
Explicit Sparse Transformer: Concentrated Attention Through Explicit Selection
Dec 25, 2019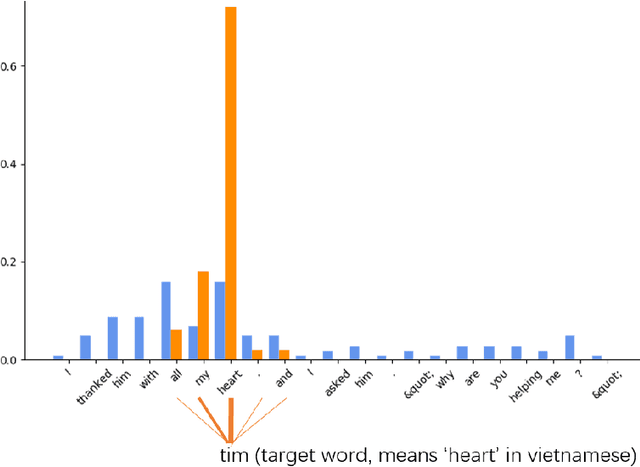
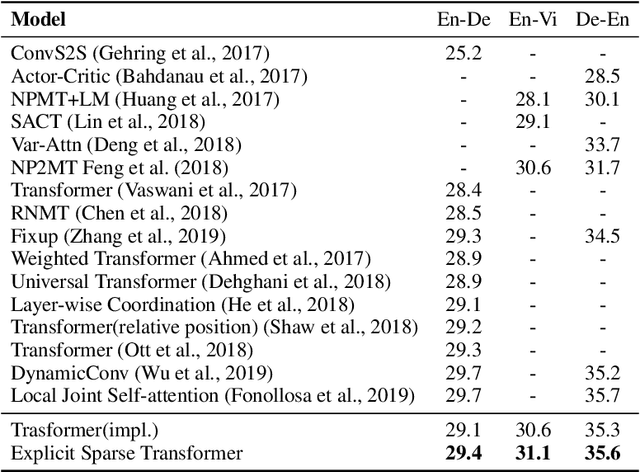
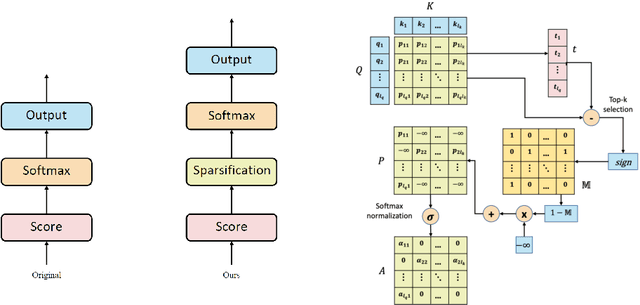
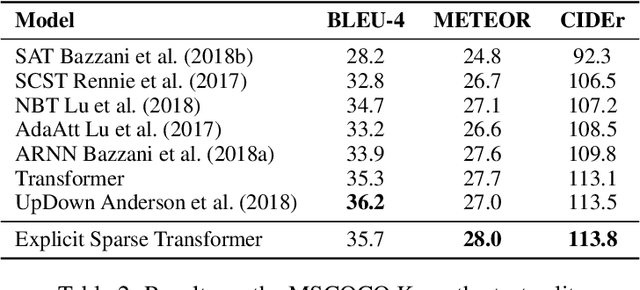
Self-attention based Transformer has demonstrated the state-of-the-art performances in a number of natural language processing tasks. Self-attention is able to model long-term dependencies, but it may suffer from the extraction of irrelevant information in the context. To tackle the problem, we propose a novel model called \textbf{Explicit Sparse Transformer}. Explicit Sparse Transformer is able to improve the concentration of attention on the global context through an explicit selection of the most relevant segments. Extensive experimental results on a series of natural language processing and computer vision tasks, including neural machine translation, image captioning, and language modeling, all demonstrate the advantages of Explicit Sparse Transformer in model performance. We also show that our proposed sparse attention method achieves comparable or better results than the previous sparse attention method, but significantly reduces training and testing time. For example, the inference speed is twice that of sparsemax in Transformer model. Code will be available at \url{https://github.com/lancopku/Explicit-Sparse-Transformer}
MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning
Nov 17, 2019
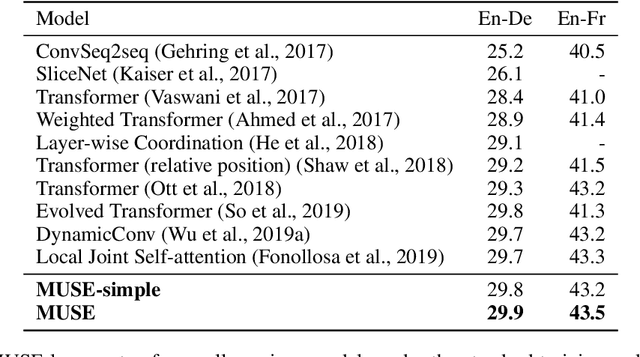
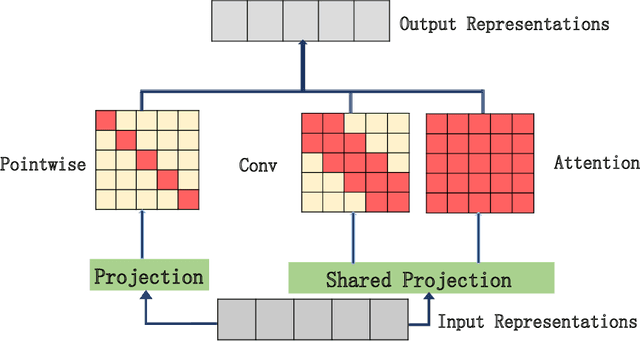
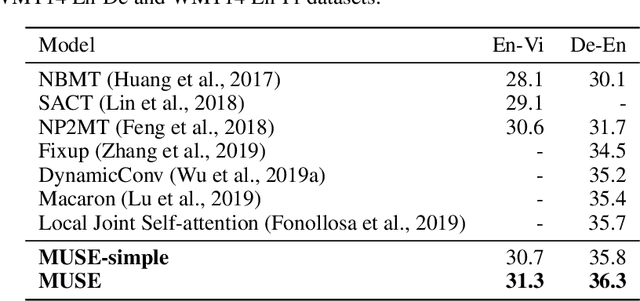
In sequence to sequence learning, the self-attention mechanism proves to be highly effective, and achieves significant improvements in many tasks. However, the self-attention mechanism is not without its own flaws. Although self-attention can model extremely long dependencies, the attention in deep layers tends to overconcentrate on a single token, leading to insufficient use of local information and difficultly in representing long sequences. In this work, we explore parallel multi-scale representation learning on sequence data, striving to capture both long-range and short-range language structures. To this end, we propose the Parallel MUlti-Scale attEntion (MUSE) and MUSE-simple. MUSE-simple contains the basic idea of parallel multi-scale sequence representation learning, and it encodes the sequence in parallel, in terms of different scales with the help from self-attention, and pointwise transformation. MUSE builds on MUSE-simple and explores combining convolution and self-attention for learning sequence representations from more different scales. We focus on machine translation and the proposed approach achieves substantial performance improvements over Transformer, especially on long sequences. More importantly, we find that although conceptually simple, its success in practice requires intricate considerations, and the multi-scale attention must build on unified semantic space. Under common setting, the proposed model achieves substantial performance and outperforms all previous models on three main machine translation tasks. In addition, MUSE has potential for accelerating inference due to its parallelism. Code will be available at https://github.com/lancopku/MUSE