 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitative Intertextuality from the Digital Humanities Perspective: A Survey
Oct 30, 2025The connection between texts is referred to as intertextuality in literary theory, which served as an important theoretical basis in many digital humanities studies. Over the past decade, advancements in natural language processing have ushered intertextuality studies into the quantitative age. Large-scale intertextuality research based on cutting-edge methods has continuously emerged. This paper provides a roadmap for quantitative intertextuality studies, summarizing their data, methods, and applications. Drawing on data from multiple languages and topics, this survey reviews methods from statistics to deep learning. It also summarizes their applications in humanities and social sciences research and the associated platform tools. Driven by advances in computer technology, more precise, diverse, and large-scale intertext studies can be anticipated. Intertextuality holds promise for broader application in interdisciplinary research bridging AI and the humanities.
Restoring Ancient Ideograph: A Multimodal Multitask Neural Network Approach
Mar 11, 2024


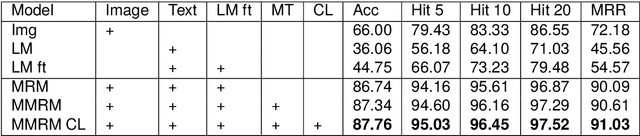
Cultural heritage serves as the enduring record of human thought and history. Despite significant efforts dedicated to the preservation of cultural relics, many ancient artefacts have been ravaged irreversibly by natural deterioration and human actions. Deep learning technology has emerged as a valuable tool for restoring various kinds of cultural heritages, including ancient text restoration. Previous research has approached ancient text restoration from either visual or textual perspectives, often overlooking the potential of synergizing multimodal information. This paper proposes a novel Multimodal Multitask Restoring Model (MMRM) to restore ancient texts, particularly emphasising the ideograph. This model combines context understanding with residual visual information from damaged ancient artefacts, enabling it to predict damaged characters and generate restored images simultaneously. We tested the MMRM model through experiments conducted on both simulated datasets and authentic ancient inscriptions. The results show that the proposed method gives insightful restoration suggestions in both simulation experiments and real-world scenarios. To the best of our knowledge, this work represents the pioneering application of multimodal deep learning in ancient text restoration, which will contribute to the understanding of ancient society and culture in digital humanities fields.
Query-Variant Advertisement Text Generation with Association Knowledge
Apr 14, 2020

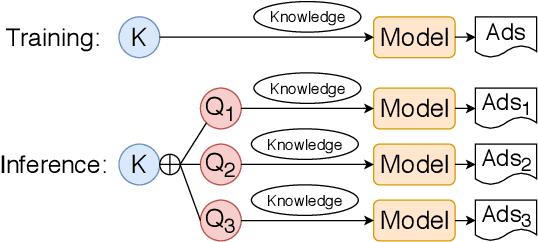
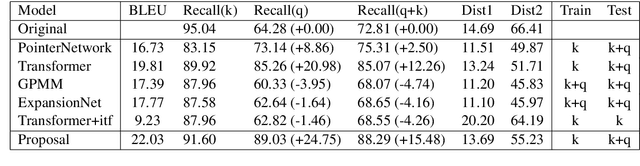
Advertising is an important revenue source for many companies. However, it is expensive to manually create advertisements that meet the needs of various queries for massive items. In this paper, we propose the query-variant advertisement text generation task that aims to generate candidate advertisements for different queries with various needs given the item keywords. In this task, for many different queries there is only one general purposed advertisement with no predefined query-advertisement pair, which would discourage traditional End-to-End models from generating query-variant advertisements for different queries with different needs. To deal with the problem, we propose a query-variant advertisement text generation model that takes keywords and associated external knowledge as input during training and adds different queries during inference. Adding external knowledge helps the model adapted to the information besides the item keywords during training, which makes the transition between training and inference more smoothing when the query is added during inference. Both automatic and human evaluation show that our model can generate more attractive and query-focused advertisements than the strong baselines.