 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical Fidelity Reconstruction via Improved Consistency-Distilled Flow Matching for Dynamical Systems
May 07, 2026Reconstructing high-fidelity flow fields from low-fidelity observations is a central problem in scientific machine learning, yet recent diffusion and flow-matching models typically rely on iterative sampling, making them costly for latency-sensitive workflows such as ensemble forecasting, real-time visualization, and simulation-in-the-loop inference. We study whether a high-fidelity flow-matching generative model can be compressed into a compact one-step model for fast scientific flow reconstruction. Our approach distills an optimal-transport flow-matching teacher into a one-step consistency model. Low-fidelity observations are incorporated at inference by initializing the generative trajectory from a noised observation along the transport path, allowing an unconditional high-fidelity flow model to perform conditional reconstruction without retraining the teacher. We evaluate this distillation strategy on three fluid benchmarks, Smoke Buoyancy, Turbulent Channel Flow, and Kolmogorov Flow, using coarse-to-fine reconstruction as a controlled testbed at field sizes up to $256 \times 256$. Across these settings, the distilled student retains similar performance of the teacher's model on spectrum metrics, while using roughly half as many parameters and achieving a $12\times$ inference speedup over the flow-matching teacher. Under the same training budget, the distilled student also outperforms a one-step consistency model trained directly from scratch by $23.1\%$ in SSIM, showing that teacher distillation improves training efficiency rather than merely accelerating sampling. These results suggest a promising route for turning future high-capacity scientific generative models into compact reconstruction models that are faster to train, cheaper to run, and easier to deploy.
Controllable Text Generation via Probability Density Estimation in the Latent Space
Dec 16, 2022



Previous work on controllable text generation has explored the idea of control from the latent space, such as optimizing a representation with attribute-related classifiers or sampling a representation from relevant discrete samples. However, they are not effective enough in modeling both the latent space and the control, leaving controlled text with low quality and diversity. In this work, we propose a novel control framework using probability density estimation in the latent space. Our method utilizes an invertible transformation function, the Normalizing Flow, that maps the complex distributions in the latent space to simple Gaussian distributions in the prior space. Thus, we can perform sophisticated and flexible control in the prior space and feed the control effects back into the latent space owing to the one-one-mapping property of invertible transformations. Experiments on single-attribute controls and multi-attribute control reveal that our method outperforms several strong baselines on attribute relevance and text quality and achieves the SOTA. Further analysis of control strength adjustment demonstrates the flexibility of our control strategy.
A Distributional Lens for Multi-Aspect Controllable Text Generation
Oct 06, 2022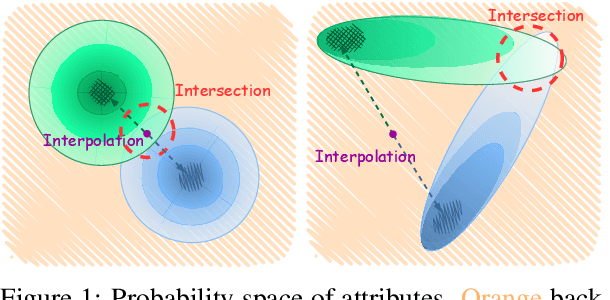
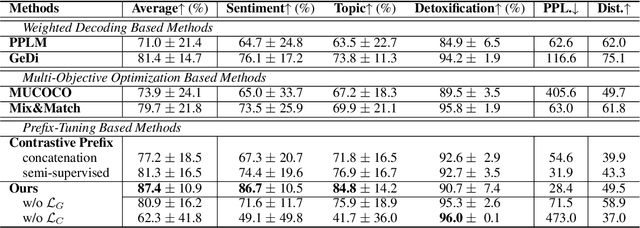
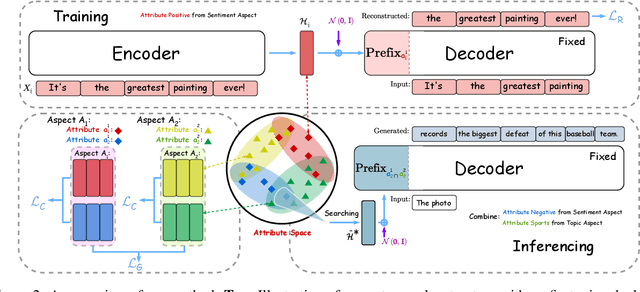
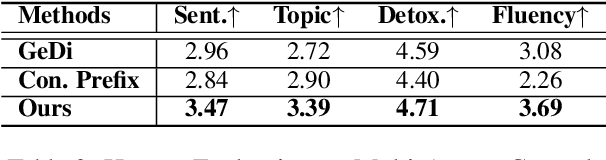
Multi-aspect controllable text generation is a more challenging and practical task than single-aspect control. Existing methods achieve complex multi-aspect control by fusing multiple controllers learned from single-aspect, but suffer from attribute degeneration caused by the mutual interference of these controllers. To address this, we provide observations on attribute fusion from a distributional perspective and propose to directly search for the intersection areas of multiple attribute distributions as their combination for generation. Our method first estimates the attribute space with an autoencoder structure. Afterward, we iteratively approach the intersections by jointly minimizing distances to points representing different attributes. Finally, we map them to attribute-relevant sentences with a prefix-tuning-based decoder. Experiments on the three-aspect control task, including sentiment, topic, and detoxification aspects, reveal that our method outperforms several strong baselines on attribute relevance and text quality and achieves the SOTA. Further analysis also supplies some explanatory support for the effectiveness of our approach.