 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Instruction-Finetuned Language Models
Oct 20, 2022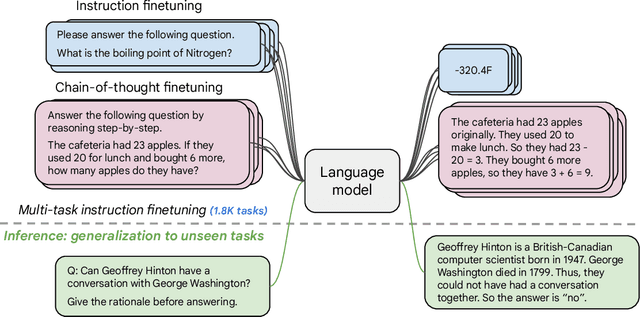

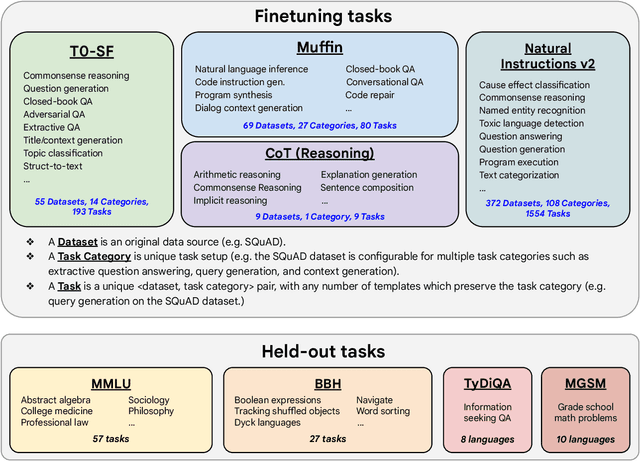

Finetuning language models on a collection of datasets phrased as instructions has been shown to improve model performance and generalization to unseen tasks. In this paper we explore instruction finetuning with a particular focus on (1) scaling the number of tasks, (2) scaling the model size, and (3) finetuning on chain-of-thought data. We find that instruction finetuning with the above aspects dramatically improves performance on a variety of model classes (PaLM, T5, U-PaLM), prompting setups (zero-shot, few-shot, CoT), and evaluation benchmarks (MMLU, BBH, TyDiQA, MGSM, open-ended generation). For instance, Flan-PaLM 540B instruction-finetuned on 1.8K tasks outperforms PALM 540B by a large margin (+9.4% on average). Flan-PaLM 540B achieves state-of-the-art performance on several benchmarks, such as 75.2% on five-shot MMLU. We also publicly release Flan-T5 checkpoints, which achieve strong few-shot performance even compared to much larger models, such as PaLM 62B. Overall, instruction finetuning is a general method for improving the performance and usability of pretrained language models.
Compositional Semantic Parsing with Large Language Models
Sep 30, 2022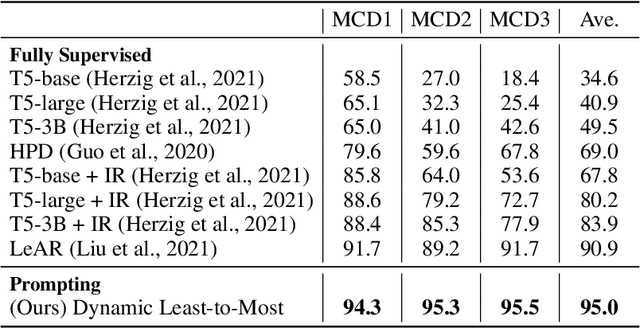
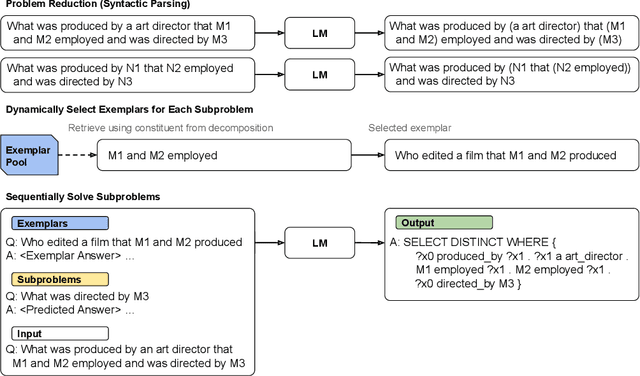
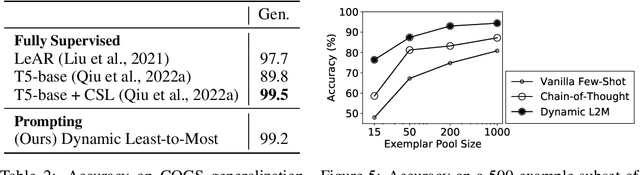
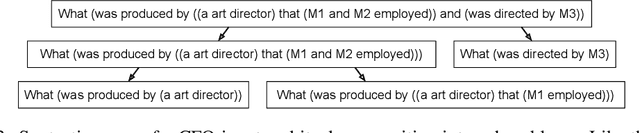
Humans can reason compositionally when presented with new tasks. Previous research shows that appropriate prompting techniques enable large language models (LLMs) to solve artificial compositional generalization tasks such as SCAN. In this work, we identify additional challenges in more realistic semantic parsing tasks with larger vocabulary and refine these prompting techniques to address them. Our best method is based on least-to-most prompting: it decomposes the problem using prompting-based syntactic parsing, then uses this decomposition to select appropriate exemplars and to sequentially generate the semantic parse. This method allows us to set a new state of the art for CFQ while requiring only 1% of the training data used by traditional approaches. Due to the general nature of our approach, we expect similar efforts will lead to new results in other tasks and domains, especially for knowledge-intensive applications.
Measuring and Improving Compositional Generalization in Text-to-SQL via Component Alignment
May 04, 2022



In text-to-SQL tasks -- as in much of NLP -- compositional generalization is a major challenge: neural networks struggle with compositional generalization where training and test distributions differ. However, most recent attempts to improve this are based on word-level synthetic data or specific dataset splits to generate compositional biases. In this work, we propose a clause-level compositional example generation method. We first split the sentences in the Spider text-to-SQL dataset into sub-sentences, annotating each sub-sentence with its corresponding SQL clause, resulting in a new dataset Spider-SS. We then construct a further dataset, Spider-CG, by composing Spider-SS sub-sentences in different combinations, to test the ability of models to generalize compositionally. Experiments show that existing models suffer significant performance degradation when evaluated on Spider-CG, even though every sub-sentence is seen during training. To deal with this problem, we modify a number of state-of-the-art models to train on the segmented data of Spider-SS, and we show that this method improves the generalization performance.
Learning Bounded Context-Free-Grammar via LSTM and the Transformer:Difference and Explanations
Dec 16, 2021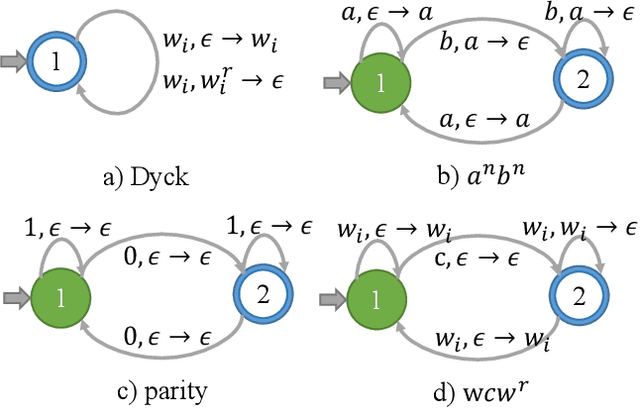
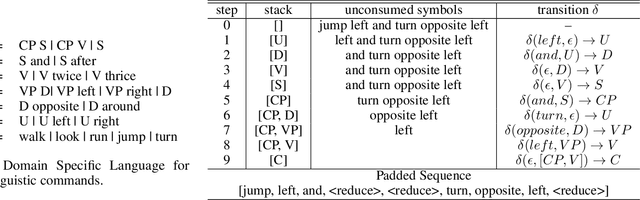
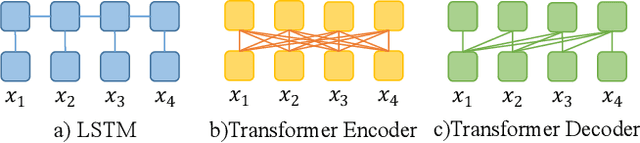
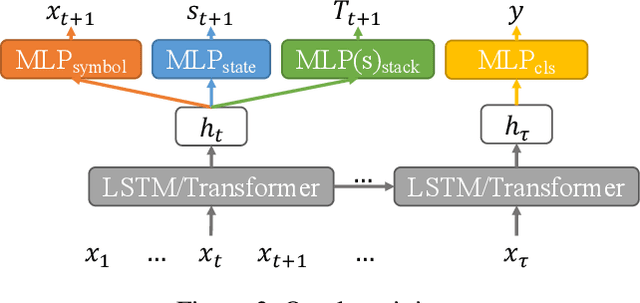
Long Short-Term Memory (LSTM) and Transformers are two popular neural architectures used for natural language processing tasks. Theoretical results show that both are Turing-complete and can represent any context-free language (CFL).In practice, it is often observed that Transformer models have better representation power than LSTM. But the reason is barely understood. We study such practical differences between LSTM and Transformer and propose an explanation based on their latent space decomposition patterns. To achieve this goal, we introduce an oracle training paradigm, which forces the decomposition of the latent representation of LSTM and the Transformer and supervises with the transitions of the Pushdown Automaton (PDA) of the corresponding CFL. With the forced decomposition, we show that the performance upper bounds of LSTM and Transformer in learning CFL are close: both of them can simulate a stack and perform stack operation along with state transitions. However, the absence of forced decomposition leads to the failure of LSTM models to capture the stack and stack operations, while having a marginal impact on the Transformer model. Lastly, we connect the experiment on the prototypical PDA to a real-world parsing task to re-verify the conclusions
SMORE: Knowledge Graph Completion and Multi-hop Reasoning in Massive Knowledge Graphs
Nov 01, 2021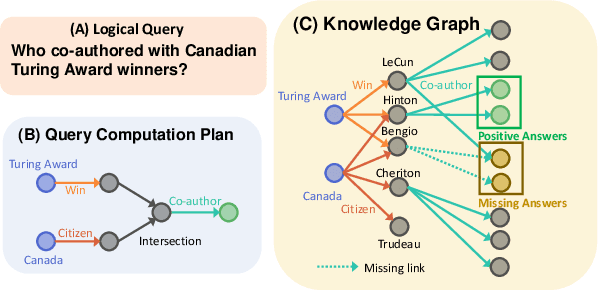

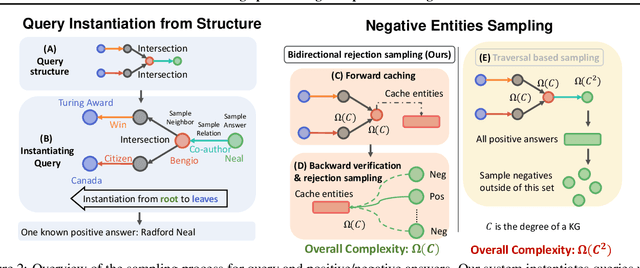
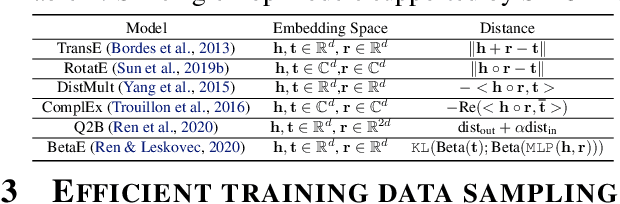
Knowledge graphs (KGs) capture knowledge in the form of head--relation--tail triples and are a crucial component in many AI systems. There are two important reasoning tasks on KGs: (1) single-hop knowledge graph completion, which involves predicting individual links in the KG; and (2), multi-hop reasoning, where the goal is to predict which KG entities satisfy a given logical query. Embedding-based methods solve both tasks by first computing an embedding for each entity and relation, then using them to form predictions. However, existing scalable KG embedding frameworks only support single-hop knowledge graph completion and cannot be applied to the more challenging multi-hop reasoning task. Here we present Scalable Multi-hOp REasoning (SMORE), the first general framework for both single-hop and multi-hop reasoning in KGs. Using a single machine SMORE can perform multi-hop reasoning in Freebase KG (86M entities, 338M edges), which is 1,500x larger than previously considered KGs. The key to SMORE's runtime performance is a novel bidirectional rejection sampling that achieves a square root reduction of the complexity of online training data generation. Furthermore, SMORE exploits asynchronous scheduling, overlapping CPU-based data sampling, GPU-based embedding computation, and frequent CPU--GPU IO. SMORE increases throughput (i.e., training speed) over prior multi-hop KG frameworks by 2.2x with minimal GPU memory requirements (2GB for training 400-dim embeddings on 86M-node Freebase) and achieves near linear speed-up with the number of GPUs. Moreover, on the simpler single-hop knowledge graph completion task SMORE achieves comparable or even better runtime performance to state-of-the-art frameworks on both single GPU and multi-GPU settings.
RobustART: Benchmarking Robustness on Architecture Design and Training Techniques
Sep 15, 2021
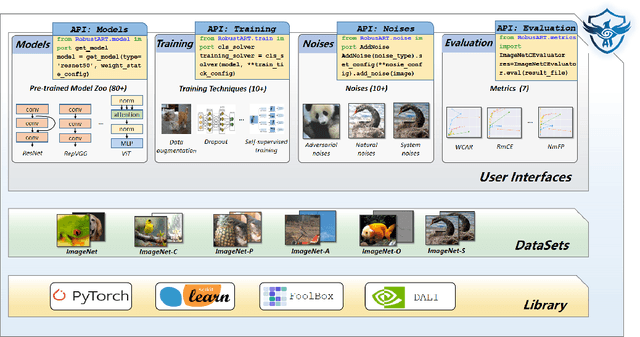

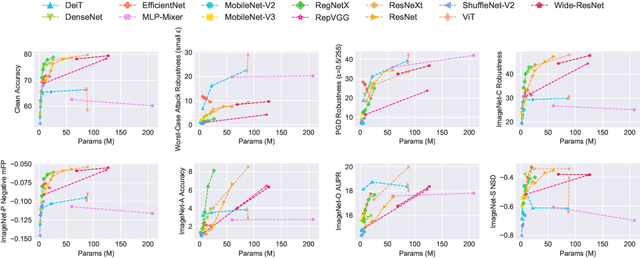
Deep neural networks (DNNs) are vulnerable to adversarial noises, which motivates the benchmark of model robustness. Existing benchmarks mainly focus on evaluating the defenses, but there are no comprehensive studies of how architecture design and general training techniques affect robustness. Comprehensively benchmarking their relationships will be highly beneficial for better understanding and developing robust DNNs. Thus, we propose RobustART, the first comprehensive Robustness investigation benchmark on ImageNet (including open-source toolkit, pre-trained model zoo, datasets, and analyses) regarding ARchitecture design (44 human-designed off-the-shelf architectures and 1200+ networks from neural architecture search) and Training techniques (10+ general techniques, e.g., data augmentation) towards diverse noises (adversarial, natural, and system noises). Extensive experiments revealed and substantiated several insights for the first time, for example: (1) adversarial training largely improves the clean accuracy and all types of robustness for Transformers and MLP-Mixers; (2) with comparable sizes, CNNs > Transformers > MLP-Mixers on robustness against natural and system noises; Transformers > MLP-Mixers > CNNs on adversarial robustness; (3) for some light-weight architectures (e.g., EfficientNet, MobileNetV2, and MobileNetV3), increasing model sizes or using extra training data cannot improve robustness. Our benchmark http://robust.art/ : (1) presents an open-source platform for conducting comprehensive evaluation on diverse robustness types; (2) provides a variety of pre-trained models with different training techniques to facilitate robustness evaluation; (3) proposes a new view to better understand the mechanism towards designing robust DNN architectures, backed up by the analysis. We will continuously contribute to building this ecosystem for the community.
Exploring Underexplored Limitations of Cross-Domain Text-to-SQL Generalization
Sep 11, 2021

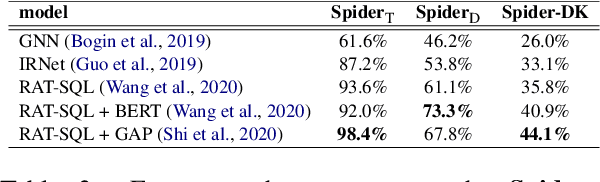
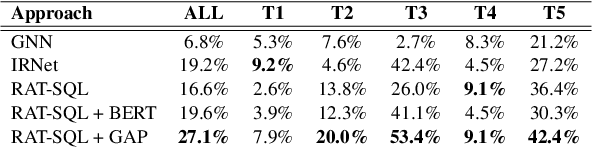
Recently, there has been significant progress in studying neural networks for translating text descriptions into SQL queries under the zero-shot cross-domain setting. Despite achieving good performance on some public benchmarks, we observe that existing text-to-SQL models do not generalize when facing domain knowledge that does not frequently appear in the training data, which may render the worse prediction performance for unseen domains. In this work, we investigate the robustness of text-to-SQL models when the questions require rarely observed domain knowledge. In particular, we define five types of domain knowledge and introduce Spider-DK (DK is the abbreviation of domain knowledge), a human-curated dataset based on the Spider benchmark for text-to-SQL translation. NL questions in Spider-DK are selected from Spider, and we modify some samples by adding domain knowledge that reflects real-world question paraphrases. We demonstrate that the prediction accuracy dramatically drops on samples that require such domain knowledge, even if the domain knowledge appears in the training set, and the model provides the correct predictions for related training samples.
Natural SQL: Making SQL Easier to Infer from Natural Language Specifications
Sep 11, 2021



Addressing the mismatch between natural language descriptions and the corresponding SQL queries is a key challenge for text-to-SQL translation. To bridge this gap, we propose an SQL intermediate representation (IR) called Natural SQL (NatSQL). Specifically, NatSQL preserves the core functionalities of SQL, while it simplifies the queries as follows: (1) dispensing with operators and keywords such as GROUP BY, HAVING, FROM, JOIN ON, which are usually hard to find counterparts for in the text descriptions; (2) removing the need for nested subqueries and set operators; and (3) making schema linking easier by reducing the required number of schema items. On Spider, a challenging text-to-SQL benchmark that contains complex and nested SQL queries, we demonstrate that NatSQL outperforms other IRs, and significantly improves the performance of several previous SOTA models. Furthermore, for existing models that do not support executable SQL generation, NatSQL easily enables them to generate executable SQL queries, and achieves the new state-of-the-art execution accuracy.
Latent Execution for Neural Program Synthesis Beyond Domain-Specific Languages
Jun 29, 2021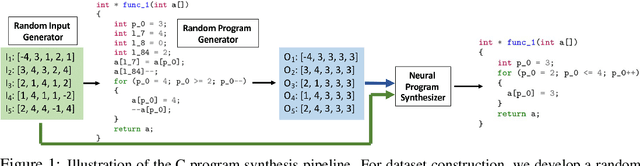

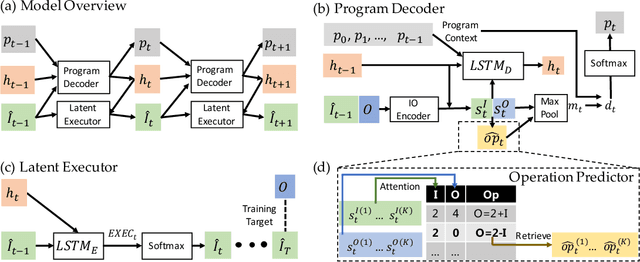
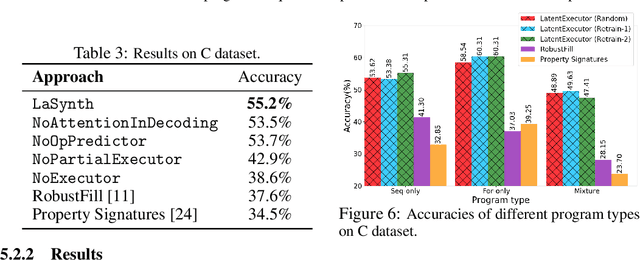
Program synthesis from input-output examples has been a long-standing challenge, and recent works have demonstrated some success in designing deep neural networks for program synthesis. However, existing efforts in input-output neural program synthesis have been focusing on domain-specific languages, thus the applicability of previous approaches to synthesize code in full-fledged popular programming languages, such as C, remains a question. The main challenges lie in two folds. On the one hand, the program search space grows exponentially when the syntax and semantics of the programming language become more complex, which poses higher requirements on the synthesis algorithm. On the other hand, increasing the complexity of the programming language also imposes more difficulties on data collection, since building a large-scale training set for input-output program synthesis require random program generators to sample programs and input-output examples. In this work, we take the first step to synthesize C programs from input-output examples. In particular, we propose LaSynth, which learns the latent representation to approximate the execution of partially generated programs, even if their semantics are not well-defined. We demonstrate the possibility of synthesizing elementary C code from input-output examples, and leveraging learned execution significantly improves the prediction performance over existing approaches. Meanwhile, compared to the randomly generated ground-truth programs, LaSynth synthesizes more concise programs that resemble human-written code. We show that training on these synthesized programs further improves the prediction performance for both Karel and C program synthesis, indicating the promise of leveraging the learned program synthesizer to improve the dataset quality for input-output program synthesis.
SpreadsheetCoder: Formula Prediction from Semi-structured Context
Jun 26, 2021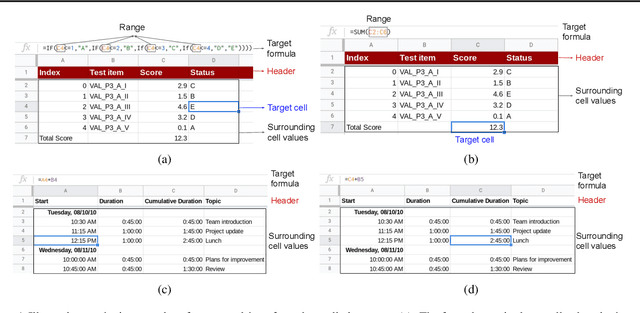
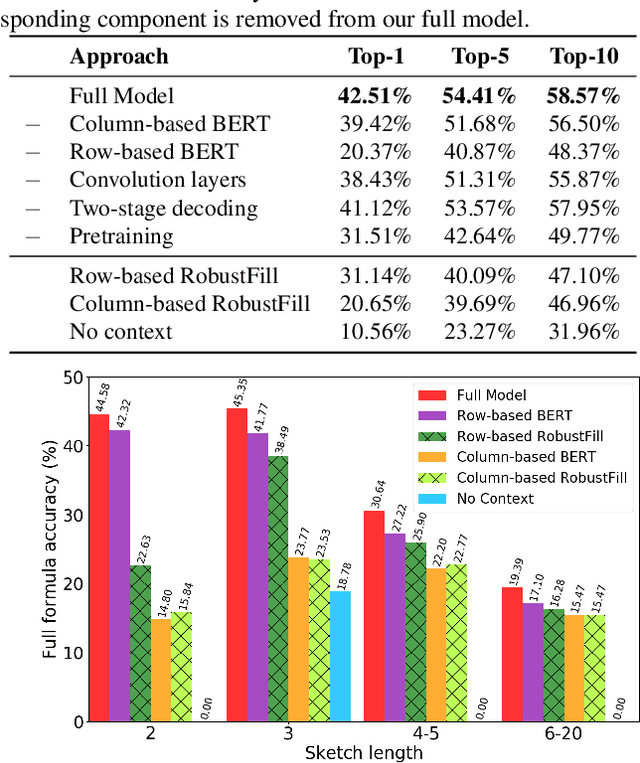
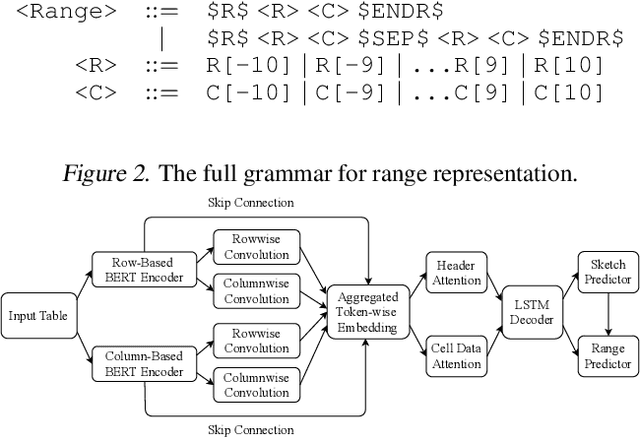
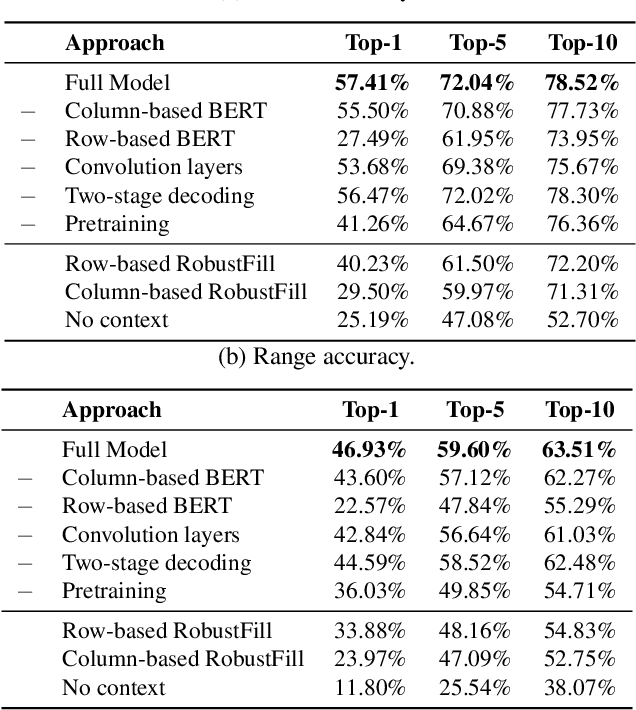
Spreadsheet formula prediction has been an important program synthesis problem with many real-world applications. Previous works typically utilize input-output examples as the specification for spreadsheet formula synthesis, where each input-output pair simulates a separate row in the spreadsheet. However, this formulation does not fully capture the rich context in real-world spreadsheets. First, spreadsheet data entries are organized as tables, thus rows and columns are not necessarily independent from each other. In addition, many spreadsheet tables include headers, which provide high-level descriptions of the cell data. However, previous synthesis approaches do not consider headers as part of the specification. In this work, we present the first approach for synthesizing spreadsheet formulas from tabular context, which includes both headers and semi-structured tabular data. In particular, we propose SpreadsheetCoder, a BERT-based model architecture to represent the tabular context in both row-based and column-based formats. We train our model on a large dataset of spreadsheets, and demonstrate that SpreadsheetCoder achieves top-1 prediction accuracy of 42.51%, which is a considerable improvement over baselines that do not employ rich tabular context. Compared to the rule-based system, SpreadsheetCoder assists 82% more users in composing formulas on Google Sheets.