 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovariance-Driven Regression Trees: Reducing Overfitting in CART
Jan 12, 2026Decision trees are powerful machine learning algorithms, widely used in fields such as economics and medicine for their simplicity and interpretability. However, decision trees such as CART are prone to overfitting, especially when grown deep or the sample size is small. Conventional methods to reduce overfitting include pre-pruning and post-pruning, which constrain the growth of uninformative branches. In this paper, we propose a complementary approach by introducing a covariance-driven splitting criterion for regression trees (CovRT). This method is more robust to overfitting than the empirical risk minimization criterion used in CART, as it produces more balanced and stable splits and more effectively identifies covariates with true signals. We establish an oracle inequality of CovRT and prove that its predictive accuracy is comparable to that of CART in high-dimensional settings. We find that CovRT achieves superior prediction accuracy compared to CART in both simulations and real-world tasks.
AutoMR: A Universal Time Series Motion Recognition Pipeline
Feb 21, 2025



In this paper, we present an end-to-end automated motion recognition (AutoMR) pipeline designed for multimodal datasets. The proposed framework seamlessly integrates data preprocessing, model training, hyperparameter tuning, and evaluation, enabling robust performance across diverse scenarios. Our approach addresses two primary challenges: 1) variability in sensor data formats and parameters across datasets, which traditionally requires task-specific machine learning implementations, and 2) the complexity and time consumption of hyperparameter tuning for optimal model performance. Our library features an all-in-one solution incorporating QuartzNet as the core model, automated hyperparameter tuning, and comprehensive metrics tracking. Extensive experiments demonstrate its effectiveness on 10 diverse datasets, achieving state-of-the-art performance. This work lays a solid foundation for deploying motion-capture solutions across varied real-world applications.
Capturing Extreme Events in Turbulence using an Extreme Variational Autoencoder (xVAE)
Feb 07, 2025Turbulent flow fields are characterized by extreme events that are statistically intermittent and carry a significant amount of energy and physical importance. To emulate these flows, we introduce the extreme variational Autoencoder (xVAE), which embeds a max-infinitely divisible process with heavy-tailed distributions into a standard VAE framework, enabling accurate modeling of extreme events. xVAEs are neural network models that reduce system dimensionality by learning non-linear latent representations of data. We demonstrate the effectiveness of xVAE in large-eddy simulation data of wildland fire plumes, where intense heat release and complex plume-atmosphere interactions generate extreme turbulence. Comparisons with the commonly used Proper Orthogonal Decomposition (POD) modes show that xVAE is more robust in capturing extreme values and provides a powerful uncertainty quantification framework using variational Bayes. Additionally, xVAE enables analysis of the so-called copulas of fields to assess risks associated with rare events while rigorously accounting for uncertainty, such as simultaneous exceedances of high thresholds across multiple locations. The proposed approach provides a new direction for studying realistic turbulent flows, such as high-speed aerodynamics, space propulsion, and atmospheric and oceanic systems that are characterized by extreme events.
Training Data Attribution: Was Your Model Secretly Trained On Data Created By Mine?
Sep 24, 2024



The emergence of text-to-image models has recently sparked significant interest, but the attendant is a looming shadow of potential infringement by violating the user terms. Specifically, an adversary may exploit data created by a commercial model to train their own without proper authorization. To address such risk, it is crucial to investigate the attribution of a suspicious model's training data by determining whether its training data originates, wholly or partially, from a specific source model. To trace the generated data, existing methods require applying extra watermarks during either the training or inference phases of the source model. However, these methods are impractical for pre-trained models that have been released, especially when model owners lack security expertise. To tackle this challenge, we propose an injection-free training data attribution method for text-to-image models. It can identify whether a suspicious model's training data stems from a source model, without additional modifications on the source model. The crux of our method lies in the inherent memorization characteristic of text-to-image models. Our core insight is that the memorization of the training dataset is passed down through the data generated by the source model to the model trained on that data, making the source model and the infringing model exhibit consistent behaviors on specific samples. Therefore, our approach involves developing algorithms to uncover these distinct samples and using them as inherent watermarks to verify if a suspicious model originates from the source model. Our experiments demonstrate that our method achieves an accuracy of over 80\% in identifying the source of a suspicious model's training data, without interfering the original training or generation process of the source model.
CoAst: Validation-Free Contribution Assessment for Federated Learning based on Cross-Round Valuation
Sep 04, 2024



In the federated learning (FL) process, since the data held by each participant is different, it is necessary to figure out which participant has a higher contribution to the model performance. Effective contribution assessment can help motivate data owners to participate in the FL training. Research works in this field can be divided into two directions based on whether a validation dataset is required. Validation-based methods need to use representative validation data to measure the model accuracy, which is difficult to obtain in practical FL scenarios. Existing validation-free methods assess the contribution based on the parameters and gradients of local models and the global model in a single training round, which is easily compromised by the stochasticity of model training. In this work, we propose CoAst, a practical method to assess the FL participants' contribution without access to any validation data. The core idea of CoAst involves two aspects: one is to only count the most important part of model parameters through a weights quantization, and the other is a cross-round valuation based on the similarity between the current local parameters and the global parameter updates in several subsequent communication rounds. Extensive experiments show that CoAst has comparable assessment reliability to existing validation-based methods and outperforms existing validation-free methods.
Cognitive resilience: Unraveling the proficiency of image-captioning models to interpret masked visual content
Mar 23, 2024



This study explores the ability of Image Captioning (IC) models to decode masked visual content sourced from diverse datasets. Our findings reveal the IC model's capability to generate captions from masked images, closely resembling the original content. Notably, even in the presence of masks, the model adeptly crafts descriptive textual information that goes beyond what is observable in the original image-generated captions. While the decoding performance of the IC model experiences a decline with an increase in the masked region's area, the model still performs well when important regions of the image are not masked at high coverage.
Flexible and efficient spatial extremes emulation via variational autoencoders
Jul 16, 2023



Many real-world processes have complex tail dependence structures that cannot be characterized using classical Gaussian processes. More flexible spatial extremes models such as Gaussian scale mixtures and single-station conditioning models exhibit appealing extremal dependence properties but are often exceedingly prohibitive to fit and simulate from. In this paper, we develop a new spatial extremes model that has flexible and non-stationary dependence properties, and we integrate it in the encoding-decoding structure of a variational autoencoder (extVAE). The extVAE can be used as a spatio-temporal emulator that characterizes the distribution of potential mechanistic model output states and produces outputs that have the same properties as the inputs, especially in the tail. Through extensive simulation studies, we show that our extVAE is vastly more time-efficient than traditional Bayesian inference while also outperforming many spatial extremes models with a stationary dependence structure. To further demonstrate the computational power of the extVAE, we analyze a high-resolution satellite-derived dataset of sea surface temperature in the Red Sea, which includes daily measurements at 16703 grid cells.
Input Perturbation: A New Paradigm between Central and Local Differential Privacy
Feb 20, 2020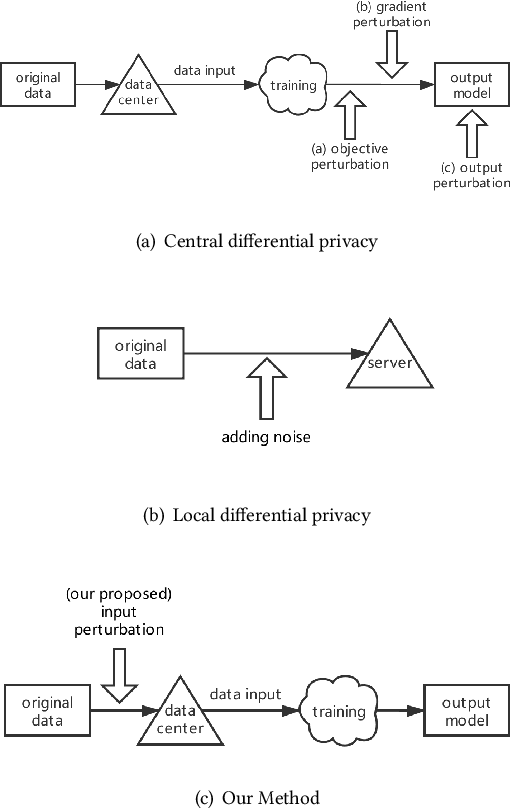
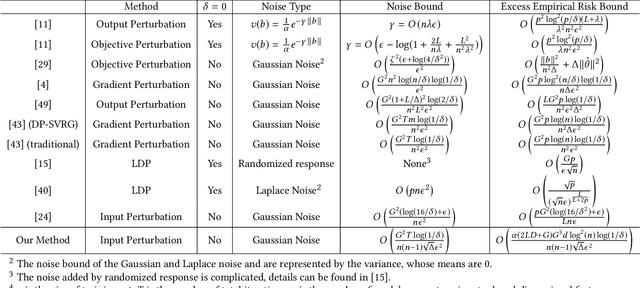
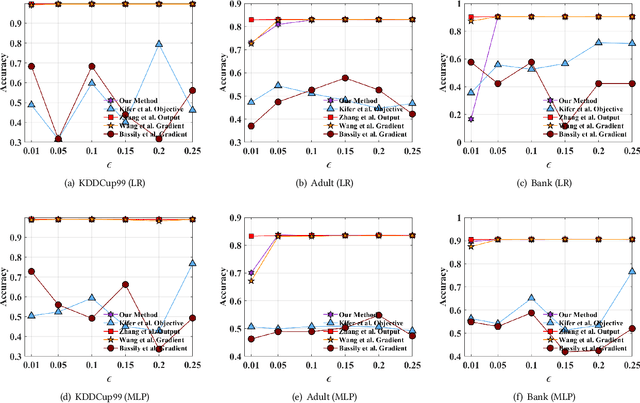
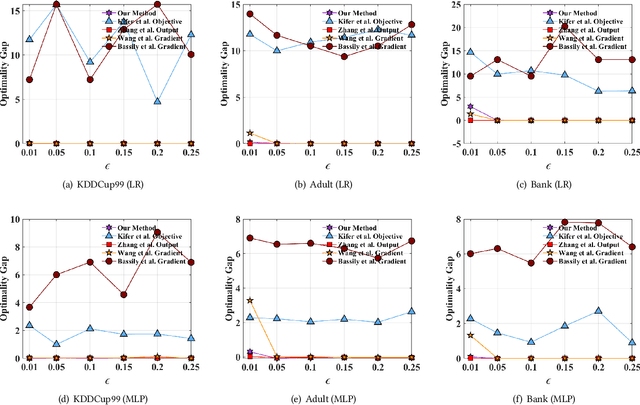
Traditionally, there are two models on differential privacy: the central model and the local model. The central model focuses on the machine learning model and the local model focuses on the training data. In this paper, we study the \textit{input perturbation} method in differentially private empirical risk minimization (DP-ERM), preserving privacy of the central model. By adding noise to the original training data and training with the `perturbed data', we achieve ($\epsilon$,$\delta$)-differential privacy on the final model, along with some kind of privacy on the original data. We observe that there is an interesting connection between the local model and the central model: the perturbation on the original data causes the perturbation on the gradient, and finally the model parameters. This observation means that our method builds a bridge between local and central model, protecting the data, the gradient and the model simultaneously, which is more superior than previous central methods. Detailed theoretical analysis and experiments show that our method achieves almost the same (or even better) performance as some of the best previous central methods with more protections on privacy, which is an attractive result. Moreover, we extend our method to a more general case: the loss function satisfies the Polyak-Lojasiewicz condition, which is more general than strong convexity, the constraint on the loss function in most previous work.