 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Information Compensation Framework for Zero-Shot Skeleton-based Action Recognition
Jun 02, 2024



Zero-shot human skeleton-based action recognition aims to construct a model that can recognize actions outside the categories seen during training. Previous research has focused on aligning sequences' visual and semantic spatial distributions. However, these methods extract semantic features simply. They ignore that proper prompt design for rich and fine-grained action cues can provide robust representation space clustering. In order to alleviate the problem of insufficient information available for skeleton sequences, we design an information compensation learning framework from an information-theoretic perspective to improve zero-shot action recognition accuracy with a multi-granularity semantic interaction mechanism. Inspired by ensemble learning, we propose a multi-level alignment (MLA) approach to compensate information for action classes. MLA aligns multi-granularity embeddings with visual embedding through a multi-head scoring mechanism to distinguish semantically similar action names and visually similar actions. Furthermore, we introduce a new loss function sampling method to obtain a tight and robust representation. Finally, these multi-granularity semantic embeddings are synthesized to form a proper decision surface for classification. Significant action recognition performance is achieved when evaluated on the challenging NTU RGB+D, NTU RGB+D 120, and PKU-MMD benchmarks and validate that multi-granularity semantic features facilitate the differentiation of action clusters with similar visual features.
MindSemantix: Deciphering Brain Visual Experiences with a Brain-Language Model
May 29, 2024Deciphering the human visual experience through brain activities captured by fMRI represents a compelling and cutting-edge challenge in the field of neuroscience research. Compared to merely predicting the viewed image itself, decoding brain activity into meaningful captions provides a higher-level interpretation and summarization of visual information, which naturally enhances the application flexibility in real-world situations. In this work, we introduce MindSemantix, a novel multi-modal framework that enables LLMs to comprehend visually-evoked semantic content in brain activity. Our MindSemantix explores a more ideal brain captioning paradigm by weaving LLMs into brain activity analysis, crafting a seamless, end-to-end Brain-Language Model. To effectively capture semantic information from brain responses, we propose Brain-Text Transformer, utilizing a Brain Q-Former as its core architecture. It integrates a pre-trained brain encoder with a frozen LLM to achieve multi-modal alignment of brain-vision-language and establish a robust brain-language correspondence. To enhance the generalizability of neural representations, we pre-train our brain encoder on a large-scale, cross-subject fMRI dataset using self-supervised learning techniques. MindSemantix provides more feasibility to downstream brain decoding tasks such as stimulus reconstruction. Conditioned by MindSemantix captioning, our framework facilitates this process by integrating with advanced generative models like Stable Diffusion and excels in understanding brain visual perception. MindSemantix generates high-quality captions that are deeply rooted in the visual and semantic information derived from brain activity. This approach has demonstrated substantial quantitative improvements over prior art. Our code will be released.
Multi-modality Regional Alignment Network for Covid X-Ray Survival Prediction and Report Generation
May 23, 2024In response to the worldwide COVID-19 pandemic, advanced automated technologies have emerged as valuable tools to aid healthcare professionals in managing an increased workload by improving radiology report generation and prognostic analysis. This study proposes Multi-modality Regional Alignment Network (MRANet), an explainable model for radiology report generation and survival prediction that focuses on high-risk regions. By learning spatial correlation in the detector, MRANet visually grounds region-specific descriptions, providing robust anatomical regions with a completion strategy. The visual features of each region are embedded using a novel survival attention mechanism, offering spatially and risk-aware features for sentence encoding while maintaining global coherence across tasks. A cross LLMs alignment is employed to enhance the image-to-text transfer process, resulting in sentences rich with clinical detail and improved explainability for radiologist. Multi-center experiments validate both MRANet's overall performance and each module's composition within the model, encouraging further advancements in radiology report generation research emphasizing clinical interpretation and trustworthiness in AI models applied to medical studies. The code is available at https://github.com/zzs95/MRANet.
Region-specific Risk Quantification for Interpretable Prognosis of COVID-19
May 05, 2024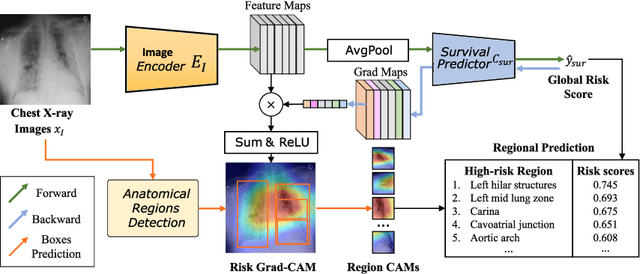
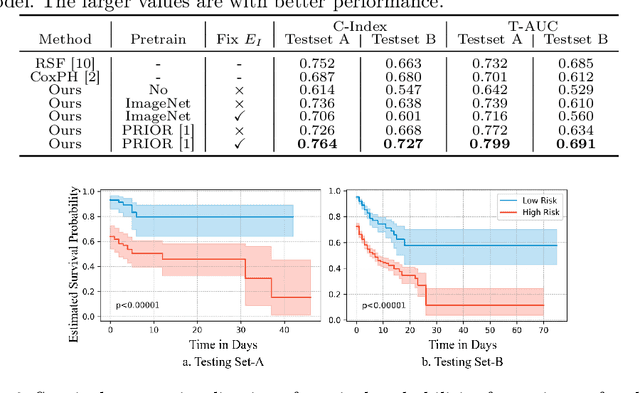

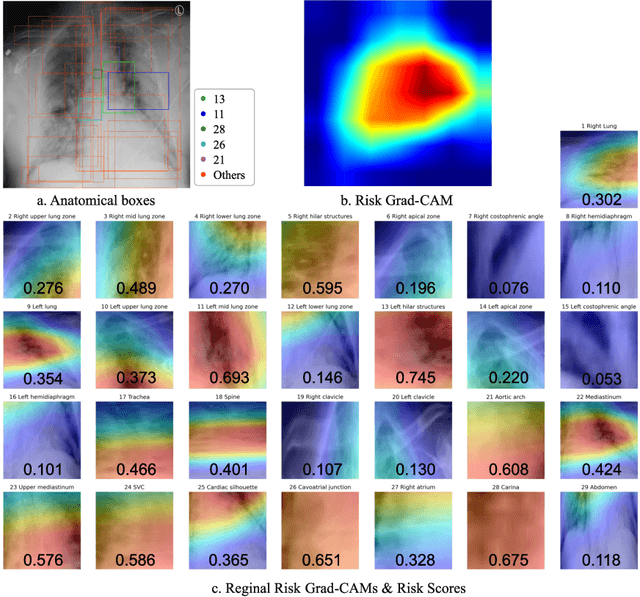
The COVID-19 pandemic has strained global public health, necessitating accurate diagnosis and intervention to control disease spread and reduce mortality rates. This paper introduces an interpretable deep survival prediction model designed specifically for improved understanding and trust in COVID-19 prognosis using chest X-ray (CXR) images. By integrating a large-scale pretrained image encoder, Risk-specific Grad-CAM, and anatomical region detection techniques, our approach produces regional interpretable outcomes that effectively capture essential disease features while focusing on rare but critical abnormal regions. Our model's predictive results provide enhanced clarity and transparency through risk area localization, enabling clinicians to make informed decisions regarding COVID-19 diagnosis with better understanding of prognostic insights. We evaluate the proposed method on a multi-center survival dataset and demonstrate its effectiveness via quantitative and qualitative assessments, achieving superior C-indexes (0.764 and 0.727) and time-dependent AUCs (0.799 and 0.691). These results suggest that our explainable deep survival prediction model surpasses traditional survival analysis methods in risk prediction, improving interpretability for clinical decision making and enhancing AI system trustworthiness.
Meta Invariance Defense Towards Generalizable Robustness to Unknown Adversarial Attacks
Apr 04, 2024



Despite providing high-performance solutions for computer vision tasks, the deep neural network (DNN) model has been proved to be extremely vulnerable to adversarial attacks. Current defense mainly focuses on the known attacks, but the adversarial robustness to the unknown attacks is seriously overlooked. Besides, commonly used adaptive learning and fine-tuning technique is unsuitable for adversarial defense since it is essentially a zero-shot problem when deployed. Thus, to tackle this challenge, we propose an attack-agnostic defense method named Meta Invariance Defense (MID). Specifically, various combinations of adversarial attacks are randomly sampled from a manually constructed Attacker Pool to constitute different defense tasks against unknown attacks, in which a student encoder is supervised by multi-consistency distillation to learn the attack-invariant features via a meta principle. The proposed MID has two merits: 1) Full distillation from pixel-, feature- and prediction-level between benign and adversarial samples facilitates the discovery of attack-invariance. 2) The model simultaneously achieves robustness to the imperceptible adversarial perturbations in high-level image classification and attack-suppression in low-level robust image regeneration. Theoretical and empirical studies on numerous benchmarks such as ImageNet verify the generalizable robustness and superiority of MID under various attacks.
InstructBrush: Learning Attention-based Instruction Optimization for Image Editing
Mar 27, 2024



In recent years, instruction-based image editing methods have garnered significant attention in image editing. However, despite encompassing a wide range of editing priors, these methods are helpless when handling editing tasks that are challenging to accurately describe through language. We propose InstructBrush, an inversion method for instruction-based image editing methods to bridge this gap. It extracts editing effects from exemplar image pairs as editing instructions, which are further applied for image editing. Two key techniques are introduced into InstructBrush, Attention-based Instruction Optimization and Transformation-oriented Instruction Initialization, to address the limitations of the previous method in terms of inversion effects and instruction generalization. To explore the ability of instruction inversion methods to guide image editing in open scenarios, we establish a TransformationOriented Paired Benchmark (TOP-Bench), which contains a rich set of scenes and editing types. The creation of this benchmark paves the way for further exploration of instruction inversion. Quantitatively and qualitatively, our approach achieves superior performance in editing and is more semantically consistent with the target editing effects.
An Open-World, Diverse, Cross-Spatial-Temporal Benchmark for Dynamic Wild Person Re-Identification
Mar 22, 2024Person re-identification (ReID) has made great strides thanks to the data-driven deep learning techniques. However, the existing benchmark datasets lack diversity, and models trained on these data cannot generalize well to dynamic wild scenarios. To meet the goal of improving the explicit generalization of ReID models, we develop a new Open-World, Diverse, Cross-Spatial-Temporal dataset named OWD with several distinct features. 1) Diverse collection scenes: multiple independent open-world and highly dynamic collecting scenes, including streets, intersections, shopping malls, etc. 2) Diverse lighting variations: long time spans from daytime to nighttime with abundant illumination changes. 3) Diverse person status: multiple camera networks in all seasons with normal/adverse weather conditions and diverse pedestrian appearances (e.g., clothes, personal belongings, poses, etc.). 4) Protected privacy: invisible faces for privacy critical applications. To improve the implicit generalization of ReID, we further propose a Latent Domain Expansion (LDE) method to develop the potential of source data, which decouples discriminative identity-relevant and trustworthy domain-relevant features and implicitly enforces domain-randomized identity feature space expansion with richer domain diversity to facilitate domain invariant representations. Our comprehensive evaluations with most benchmark datasets in the community are crucial for progress, although this work is far from the grand goal toward open-world and dynamic wild applications.
Semi-Supervised Learning for Anomaly Traffic Detection via Bidirectional Normalizing Flows
Mar 13, 2024



With the rapid development of the Internet, various types of anomaly traffic are threatening network security. We consider the problem of anomaly network traffic detection and propose a three-stage anomaly detection framework using only normal traffic. Our framework can generate pseudo anomaly samples without prior knowledge of anomalies to achieve the detection of anomaly data. Firstly, we employ a reconstruction method to learn the deep representation of normal samples. Secondly, these representations are normalized to a standard normal distribution using a bidirectional flow module. To simulate anomaly samples, we add noises to the normalized representations which are then passed through the generation direction of the bidirectional flow module. Finally, a simple classifier is trained to differentiate the normal samples and pseudo anomaly samples in the latent space. During inference, our framework requires only two modules to detect anomalous samples, leading to a considerable reduction in model size. According to the experiments, our method achieves the state of-the-art results on the common benchmarking datasets of anomaly network traffic detection. The code is given in the https://github.com/ZxuanDang/ATD-via-Flows.git
DAMSDet: Dynamic Adaptive Multispectral Detection Transformer with Competitive Query Selection and Adaptive Feature Fusion
Mar 07, 2024



Infrared-visible object detection aims to achieve robust even full-day object detection by fusing the complementary information of infrared and visible images. However, highly dynamically variable complementary characteristics and commonly existing modality misalignment make the fusion of complementary information difficult. In this paper, we propose a Dynamic Adaptive Multispectral Detection Transformer (DAMSDet) to simultaneously address these two challenges. Specifically, we propose a Modality Competitive Query Selection strategy to provide useful prior information. This strategy can dynamically select basic salient modality feature representation for each object. To effectively mine the complementary information and adapt to misalignment situations, we propose a Multispectral Deformable Cross-attention module to adaptively sample and aggregate multi-semantic level features of infrared and visible images for each object. In addition, we further adopt the cascade structure of DETR to better mine complementary information. Experiments on four public datasets of different scenes demonstrate significant improvements compared to other state-of-the-art methods. The code will be released at https://github.com/gjj45/DAMSDet.
Are Dense Labels Always Necessary for 3D Object Detection from Point Cloud?
Mar 05, 2024



Current state-of-the-art (SOTA) 3D object detection methods often require a large amount of 3D bounding box annotations for training. However, collecting such large-scale densely-supervised datasets is notoriously costly. To reduce the cumbersome data annotation process, we propose a novel sparsely-annotated framework, in which we just annotate one 3D object per scene. Such a sparse annotation strategy could significantly reduce the heavy annotation burden, while inexact and incomplete sparse supervision may severely deteriorate the detection performance. To address this issue, we develop the SS3D++ method that alternatively improves 3D detector training and confident fully-annotated scene generation in a unified learning scheme. Using sparse annotations as seeds, we progressively generate confident fully-annotated scenes based on designing a missing-annotated instance mining module and reliable background mining module. Our proposed method produces competitive results when compared with SOTA weakly-supervised methods using the same or even more annotation costs. Besides, compared with SOTA fully-supervised methods, we achieve on-par or even better performance on the KITTI dataset with about 5x less annotation cost, and 90% of their performance on the Waymo dataset with about 15x less annotation cost. The additional unlabeled training scenes could further boost the performance. The code will be available at https://github.com/gaocq/SS3D2.