 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUntrained Neural Nets for Snapshot Compressive Imaging: Theory and Algorithms
Jun 06, 2024



Snapshot compressive imaging (SCI) recovers high-dimensional (3D) data cubes from a single 2D measurement, enabling diverse applications like video and hyperspectral imaging to go beyond standard techniques in terms of acquisition speed and efficiency. In this paper, we focus on SCI recovery algorithms that employ untrained neural networks (UNNs), such as deep image prior (DIP), to model source structure. Such UNN-based methods are appealing as they have the potential of avoiding the computationally intensive retraining required for different source models and different measurement scenarios. We first develop a theoretical framework for characterizing the performance of such UNN-based methods. The theoretical framework, on the one hand, enables us to optimize the parameters of data-modulating masks, and on the other hand, provides a fundamental connection between the number of data frames that can be recovered from a single measurement to the parameters of the untrained NN. We also employ the recently proposed bagged-deep-image-prior (bagged-DIP) idea to develop SCI Bagged Deep Video Prior (SCI-BDVP) algorithms that address the common challenges faced by standard UNN solutions. Our experimental results show that in video SCI our proposed solution achieves state-of-the-art among UNN methods, and in the case of noisy measurements, it even outperforms supervised solutions.
A Novel Defense Against Poisoning Attacks on Federated Learning: LayerCAM Augmented with Autoencoder
Jun 02, 2024



Recent attacks on federated learning (FL) can introduce malicious model updates that circumvent widely adopted Euclidean distance-based detection methods. This paper proposes a novel defense strategy, referred to as LayerCAM-AE, designed to counteract model poisoning in federated learning. The LayerCAM-AE puts forth a new Layer Class Activation Mapping (LayerCAM) integrated with an autoencoder (AE), significantly enhancing detection capabilities. Specifically, LayerCAM-AE generates a heat map for each local model update, which is then transformed into a more compact visual format. The autoencoder is designed to process the LayerCAM heat maps from the local model updates, improving their distinctiveness and thereby increasing the accuracy in spotting anomalous maps and malicious local models. To address the risk of misclassifications with LayerCAM-AE, a voting algorithm is developed, where a local model update is flagged as malicious if its heat maps are consistently suspicious over several rounds of communication. Extensive tests of LayerCAM-AE on the SVHN and CIFAR-100 datasets are performed under both Independent and Identically Distributed (IID) and non-IID settings in comparison with existing ResNet-50 and REGNETY-800MF defense models. Experimental results show that LayerCAM-AE increases detection rates (Recall: 1.0, Precision: 1.0, FPR: 0.0, Accuracy: 1.0, F1 score: 1.0, AUC: 1.0) and test accuracy in FL, surpassing the performance of both the ResNet-50 and REGNETY-800MF. Our code is available at: https://github.com/jjzgeeks/LayerCAM-AE
Leverage Variational Graph Representation For Model Poisoning on Federated Learning
Apr 24, 2024This paper puts forth a new training data-untethered model poisoning (MP) attack on federated learning (FL). The new MP attack extends an adversarial variational graph autoencoder (VGAE) to create malicious local models based solely on the benign local models overheard without any access to the training data of FL. Such an advancement leads to the VGAE-MP attack that is not only efficacious but also remains elusive to detection. VGAE-MP attack extracts graph structural correlations among the benign local models and the training data features, adversarially regenerates the graph structure, and generates malicious local models using the adversarial graph structure and benign models' features. Moreover, a new attacking algorithm is presented to train the malicious local models using VGAE and sub-gradient descent, while enabling an optimal selection of the benign local models for training the VGAE. Experiments demonstrate a gradual drop in FL accuracy under the proposed VGAE-MP attack and the ineffectiveness of existing defense mechanisms in detecting the attack, posing a severe threat to FL.
Deep Optics for Video Snapshot Compressive Imaging
Apr 08, 2024



Video snapshot compressive imaging (SCI) aims to capture a sequence of video frames with only a single shot of a 2D detector, whose backbones rest in optical modulation patterns (also known as masks) and a computational reconstruction algorithm. Advanced deep learning algorithms and mature hardware are putting video SCI into practical applications. Yet, there are two clouds in the sunshine of SCI: i) low dynamic range as a victim of high temporal multiplexing, and ii) existing deep learning algorithms' degradation on real system. To address these challenges, this paper presents a deep optics framework to jointly optimize masks and a reconstruction network. Specifically, we first propose a new type of structural mask to realize motion-aware and full-dynamic-range measurement. Considering the motion awareness property in measurement domain, we develop an efficient network for video SCI reconstruction using Transformer to capture long-term temporal dependencies, dubbed Res2former. Moreover, sensor response is introduced into the forward model of video SCI to guarantee end-to-end model training close to real system. Finally, we implement the learned structural masks on a digital micro-mirror device. Experimental results on synthetic and real data validate the effectiveness of the proposed framework. We believe this is a milestone for real-world video SCI. The source code and data are available at https://github.com/pwangcs/DeepOpticsSCI.
Dual-Scale Transformer for Large-Scale Single-Pixel Imaging
Apr 07, 2024Single-pixel imaging (SPI) is a potential computational imaging technique which produces image by solving an illposed reconstruction problem from few measurements captured by a single-pixel detector. Deep learning has achieved impressive success on SPI reconstruction. However, previous poor reconstruction performance and impractical imaging model limit its real-world applications. In this paper, we propose a deep unfolding network with hybrid-attention Transformer on Kronecker SPI model, dubbed HATNet, to improve the imaging quality of real SPI cameras. Specifically, we unfold the computation graph of the iterative shrinkagethresholding algorithm (ISTA) into two alternative modules: efficient tensor gradient descent and hybrid-attention multiscale denoising. By virtue of Kronecker SPI, the gradient descent module can avoid high computational overheads rooted in previous gradient descent modules based on vectorized SPI. The denoising module is an encoder-decoder architecture powered by dual-scale spatial attention for high- and low-frequency aggregation and channel attention for global information recalibration. Moreover, we build a SPI prototype to verify the effectiveness of the proposed method. Extensive experiments on synthetic and real data demonstrate that our method achieves the state-of-the-art performance. The source code and pre-trained models are available at https://github.com/Gang-Qu/HATNet-SPI.
Binarized Low-light Raw Video Enhancement
Mar 29, 2024



Recently, deep neural networks have achieved excellent performance on low-light raw video enhancement. However, they often come with high computational complexity and large memory costs, which hinder their applications on resource-limited devices. In this paper, we explore the feasibility of applying the extremely compact binary neural network (BNN) to low-light raw video enhancement. Nevertheless, there are two main issues with binarizing video enhancement models. One is how to fuse the temporal information to improve low-light denoising without complex modules. The other is how to narrow the performance gap between binary convolutions with the full precision ones. To address the first issue, we introduce a spatial-temporal shift operation, which is easy-to-binarize and effective. The temporal shift efficiently aggregates the features of neighbor frames and the spatial shift handles the misalignment caused by the large motion in videos. For the second issue, we present a distribution-aware binary convolution, which captures the distribution characteristics of real-valued input and incorporates them into plain binary convolutions to alleviate the degradation in performance. Extensive quantitative and qualitative experiments have shown our high-efficiency binarized low-light raw video enhancement method can attain a promising performance.
SCINeRF: Neural Radiance Fields from a Snapshot Compressive Image
Mar 29, 2024In this paper, we explore the potential of Snapshot Compressive Imaging (SCI) technique for recovering the underlying 3D scene representation from a single temporal compressed image. SCI is a cost-effective method that enables the recording of high-dimensional data, such as hyperspectral or temporal information, into a single image using low-cost 2D imaging sensors. To achieve this, a series of specially designed 2D masks are usually employed, which not only reduces storage requirements but also offers potential privacy protection. Inspired by this, to take one step further, our approach builds upon the powerful 3D scene representation capabilities of neural radiance fields (NeRF). Specifically, we formulate the physical imaging process of SCI as part of the training of NeRF, allowing us to exploit its impressive performance in capturing complex scene structures. To assess the effectiveness of our method, we conduct extensive evaluations using both synthetic data and real data captured by our SCI system. Extensive experimental results demonstrate that our proposed approach surpasses the state-of-the-art methods in terms of image reconstruction and novel view image synthesis. Moreover, our method also exhibits the ability to restore high frame-rate multi-view consistent images by leveraging SCI and the rendering capabilities of NeRF. The code is available at https://github.com/WU-CVGL/SCINeRF.
A First Look at GPT Apps: Landscape and Vulnerability
Feb 23, 2024With the advancement of Large Language Models (LLMs), increasingly sophisticated and powerful GPTs are entering the market. Despite their popularity, the LLM ecosystem still remains unexplored. Additionally, LLMs' susceptibility to attacks raises concerns over safety and plagiarism. Thus, in this work, we conduct a pioneering exploration of GPT stores, aiming to study vulnerabilities and plagiarism within GPT applications. To begin with, we conduct, to our knowledge, the first large-scale monitoring and analysis of two stores, an unofficial GPTStore.AI, and an official OpenAI GPT Store. Then, we propose a TriLevel GPT Reversing (T-GR) strategy for extracting GPT internals. To complete these two tasks efficiently, we develop two automated tools: one for web scraping and another designed for programmatically interacting with GPTs. Our findings reveal a significant enthusiasm among users and developers for GPT interaction and creation, as evidenced by the rapid increase in GPTs and their creators. However, we also uncover a widespread failure to protect GPT internals, with nearly 90% of system prompts easily accessible, leading to considerable plagiarism and duplication among GPTs.
Inflation with Diffusion: Efficient Temporal Adaptation for Text-to-Video Super-Resolution
Jan 18, 2024


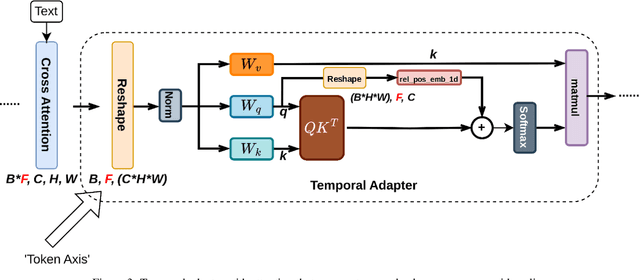
We propose an efficient diffusion-based text-to-video super-resolution (SR) tuning approach that leverages the readily learned capacity of pixel level image diffusion model to capture spatial information for video generation. To accomplish this goal, we design an efficient architecture by inflating the weightings of the text-to-image SR model into our video generation framework. Additionally, we incorporate a temporal adapter to ensure temporal coherence across video frames. We investigate different tuning approaches based on our inflated architecture and report trade-offs between computational costs and super-resolution quality. Empirical evaluation, both quantitative and qualitative, on the Shutterstock video dataset, demonstrates that our approach is able to perform text-to-video SR generation with good visual quality and temporal consistency. To evaluate temporal coherence, we also present visualizations in video format in https://drive.google.com/drive/folders/1YVc-KMSJqOrEUdQWVaI-Yfu8Vsfu_1aO?usp=sharing .
SnapCap: Efficient Snapshot Compressive Video Captioning
Jan 10, 2024Video Captioning (VC) is a challenging multi-modal task since it requires describing the scene in language by understanding various and complex videos. For machines, the traditional VC follows the "imaging-compression-decoding-and-then-captioning" pipeline, where compression is pivot for storage and transmission. However, in such a pipeline, some potential shortcomings are inevitable, i.e., information redundancy resulting in low efficiency and information loss during the sampling process for captioning. To address these problems, in this paper, we propose a novel VC pipeline to generate captions directly from the compressed measurement, which can be captured by a snapshot compressive sensing camera and we dub our model SnapCap. To be more specific, benefiting from the signal simulation, we have access to obtain abundant measurement-video-annotation data pairs for our model. Besides, to better extract language-related visual representations from the compressed measurement, we propose to distill the knowledge from videos via a pre-trained CLIP with plentiful language-vision associations to guide the learning of our SnapCap. To demonstrate the effectiveness of SnapCap, we conduct experiments on two widely-used VC datasets. Both the qualitative and quantitative results verify the superiority of our pipeline over conventional VC pipelines. In particular, compared to the "caption-after-reconstruction" methods, our SnapCap can run at least 3$\times$ faster, and achieve better caption results.