 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Dual-Exposure Quad-Bayer Patterns for Joint Denoising and Deblurring
Dec 10, 2024



Image degradation caused by noise and blur remains a persistent challenge in imaging systems, stemming from limitations in both hardware and methodology. Single-image solutions face an inherent tradeoff between noise reduction and motion blur. While short exposures can capture clear motion, they suffer from noise amplification. Long exposures reduce noise but introduce blur. Learning-based single-image enhancers tend to be over-smooth due to the limited information. Multi-image solutions using burst mode avoid this tradeoff by capturing more spatial-temporal information but often struggle with misalignment from camera/scene motion. To address these limitations, we propose a physical-model-based image restoration approach leveraging a novel dual-exposure Quad-Bayer pattern sensor. By capturing pairs of short and long exposures at the same starting point but with varying durations, this method integrates complementary noise-blur information within a single image. We further introduce a Quad-Bayer synthesis method (B2QB) to simulate sensor data from Bayer patterns to facilitate training. Based on this dual-exposure sensor model, we design a hierarchical convolutional neural network called QRNet to recover high-quality RGB images. The network incorporates input enhancement blocks and multi-level feature extraction to improve restoration quality. Experiments demonstrate superior performance over state-of-the-art deblurring and denoising methods on both synthetic and real-world datasets. The code, model, and datasets are publicly available at https://github.com/zhaoyuzhi/QRNet.
Adaptive Model Predictive Control for Differential-Algebraic Systems towards a Higher Path Accuracy for Physically Coupled Robots
Dec 04, 2024



The physical coupling between robots has the potential to improve the capabilities of multi-robot systems in challenging manufacturing processes. However, the path tracking accuracy of physically coupled robots is not studied adequately, especially considering the uncertain kinematic parameters, the mechanical elasticity, and the built-in controllers of off-the-shelf robots. This paper addresses these issues with a novel differential-algebraic system model which is verified against measurement data from real execution. The uncertain kinematic parameters are estimated online to adapt the model. Consequently, an adaptive model predictive controller is designed as a coordinator between the robots. The controller achieves a path tracking error reduction of 88.6% compared to the state-of-the-art benchmark in the simulation.
MTA: Multimodal Task Alignment for BEV Perception and Captioning
Nov 16, 2024Bird's eye view (BEV)-based 3D perception plays a crucial role in autonomous driving applications. The rise of large language models has spurred interest in BEV-based captioning to understand object behavior in the surrounding environment. However, existing approaches treat perception and captioning as separate tasks, focusing on the performance of only one of the tasks and overlooking the potential benefits of multimodal alignment. To bridge this gap between modalities, we introduce MTA, a novel multimodal task alignment framework that boosts both BEV perception and captioning. MTA consists of two key components: (1) BEV-Language Alignment (BLA), a contextual learning mechanism that aligns the BEV scene representations with ground-truth language representations, and (2) Detection-Captioning Alignment (DCA), a cross-modal prompting mechanism that aligns detection and captioning outputs. MTA integrates into state-of-the-art baselines during training, adding no extra computational complexity at runtime. Extensive experiments on the nuScenes and TOD3Cap datasets show that MTA significantly outperforms state-of-the-art baselines, achieving a 4.9% improvement in perception and a 9.2% improvement in captioning. These results underscore the effectiveness of unified alignment in reconciling BEV-based perception and captioning.
Selecting Between BERT and GPT for Text Classification in Political Science Research
Nov 07, 2024



Political scientists often grapple with data scarcity in text classification. Recently, fine-tuned BERT models and their variants have gained traction as effective solutions to address this issue. In this study, we investigate the potential of GPT-based models combined with prompt engineering as a viable alternative. We conduct a series of experiments across various classification tasks, differing in the number of classes and complexity, to evaluate the effectiveness of BERT-based versus GPT-based models in low-data scenarios. Our findings indicate that while zero-shot and few-shot learning with GPT models provide reasonable performance and are well-suited for early-stage research exploration, they generally fall short - or, at best, match - the performance of BERT fine-tuning, particularly as the training set reaches a substantial size (e.g., 1,000 samples). We conclude by comparing these approaches in terms of performance, ease of use, and cost, providing practical guidance for researchers facing data limitations. Our results are particularly relevant for those engaged in quantitative text analysis in low-resource settings or with limited labeled data.
Temporal Scaling Law for Large Language Models
Apr 27, 2024Recently, Large Language Models (LLMs) are widely adopted in a wide range of tasks, leading to increasing attention towards the research on how scaling LLMs affects their performance. Existing works, termed as Scaling Laws, have discovered that the loss of LLMs scales as power laws with model size, computational budget, and dataset size. However, the performance of LLMs throughout the training process remains untouched. In this paper, we propose the novel concept of Temporal Scaling Law and study the loss of LLMs from the temporal dimension. We first investigate the imbalance of loss on each token positions and develop a reciprocal-law across model scales and training stages. We then derive the temporal scaling law by studying the temporal patterns of the reciprocal-law parameters. Results on both in-distribution (IID) data and out-of-distribution (OOD) data demonstrate that our temporal scaling law accurately predicts the performance of LLMs in future training stages. Moreover, the temporal scaling law reveals that LLMs learn uniformly on different token positions, despite the loss imbalance. Experiments on pre-training LLMs in various scales show that this phenomenon verifies the default training paradigm for generative language models, in which no re-weighting strategies are attached during training. Overall, the temporal scaling law provides deeper insight into LLM pre-training.
LORD: Large Models based Opposite Reward Design for Autonomous Driving
Mar 27, 2024



Reinforcement learning (RL) based autonomous driving has emerged as a promising alternative to data-driven imitation learning approaches. However, crafting effective reward functions for RL poses challenges due to the complexity of defining and quantifying good driving behaviors across diverse scenarios. Recently, large pretrained models have gained significant attention as zero-shot reward models for tasks specified with desired linguistic goals. However, the desired linguistic goals for autonomous driving such as "drive safely" are ambiguous and incomprehensible by pretrained models. On the other hand, undesired linguistic goals like "collision" are more concrete and tractable. In this work, we introduce LORD, a novel large models based opposite reward design through undesired linguistic goals to enable the efficient use of large pretrained models as zero-shot reward models. Through extensive experiments, our proposed framework shows its efficiency in leveraging the power of large pretrained models for achieving safe and enhanced autonomous driving. Moreover, the proposed approach shows improved generalization capabilities as it outperforms counterpart methods across diverse and challenging driving scenarios.
MGTR: Multi-Granular Transformer for Motion Prediction with LiDAR
Dec 05, 2023Motion prediction has been an essential component of autonomous driving systems since it handles highly uncertain and complex scenarios involving moving agents of different types. In this paper, we propose a Multi-Granular TRansformer (MGTR) framework, an encoder-decoder network that exploits context features in different granularities for different kinds of traffic agents. To further enhance MGTR's capabilities, we leverage LiDAR point cloud data by incorporating LiDAR semantic features from an off-the-shelf LiDAR feature extractor. We evaluate MGTR on Waymo Open Dataset motion prediction benchmark and show that the proposed method achieved state-of-the-art performance, ranking 1st on its leaderboard (https://waymo.com/open/challenges/2023/motion-prediction/).
PMP-Swin: Multi-Scale Patch Message Passing Swin Transformer for Retinal Disease Classification
Nov 20, 2023Retinal disease is one of the primary causes of visual impairment, and early diagnosis is essential for preventing further deterioration. Nowadays, many works have explored Transformers for diagnosing diseases due to their strong visual representation capabilities. However, retinal diseases exhibit milder forms and often present with overlapping signs, which pose great difficulties for accurate multi-class classification. Therefore, we propose a new framework named Multi-Scale Patch Message Passing Swin Transformer for multi-class retinal disease classification. Specifically, we design a Patch Message Passing (PMP) module based on the Message Passing mechanism to establish global interaction for pathological semantic features and to exploit the subtle differences further between different diseases. Moreover, considering the various scale of pathological features we integrate multiple PMP modules for different patch sizes. For evaluation, we have constructed a new dataset, named OPTOS dataset, consisting of 1,033 high-resolution fundus images photographed by Optos camera and conducted comprehensive experiments to validate the efficacy of our proposed method. And the results on both the public dataset and our dataset demonstrate that our method achieves remarkable performance compared to state-of-the-art methods.
DEFN: Dual-Encoder Fourier Group Harmonics Network for Three-Dimensional Macular Hole Reconstruction with Stochastic Retinal Defect Augmentation and Dynamic Weight Composition
Nov 01, 2023The spatial and quantitative parameters of macular holes are vital for diagnosis, surgical choices, and post-op monitoring. Macular hole diagnosis and treatment rely heavily on spatial and quantitative data, yet the scarcity of such data has impeded the progress of deep learning techniques for effective segmentation and real-time 3D reconstruction. To address this challenge, we assembled the world's largest macular hole dataset, Retinal OCTfor Macular Hole Enhancement (ROME-3914), and a Comprehensive Archive for Retinal Segmentation (CARS-30k), both expertly annotated. In addition, we developed an innovative 3D segmentation network, the Dual-Encoder FuGH Network (DEFN), which integrates three innovative modules: Fourier Group Harmonics (FuGH), Simplified 3D Spatial Attention (S3DSA) and Harmonic Squeeze-and-Excitation Module (HSE). These three modules synergistically filter noise, reduce computational complexity, emphasize detailed features, and enhance the network's representation ability. We also proposed a novel data augmentation method, Stochastic Retinal Defect Injection (SRDI), and a network optimization strategy DynamicWeightCompose (DWC), to further improve the performance of DEFN. Compared with 13 baselines, our DEFN shows the best performance. We also offer precise 3D retinal reconstruction and quantitative metrics, bringing revolutionary diagnostic and therapeutic decision-making tools for ophthalmologists, and is expected to completely reshape the diagnosis and treatment patterns of difficult-to-treat macular degeneration. The source code is publicly available at: https://github.com/IIPL-HangzhouDianUniversity/DEFN-Pytorch.
Speech2Slot: An End-to-End Knowledge-based Slot Filling from Speech
May 10, 2021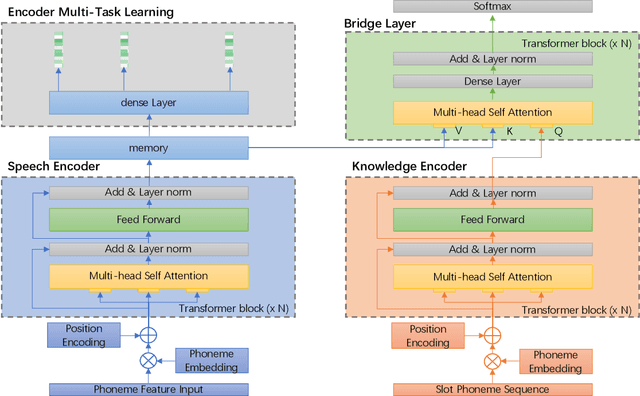
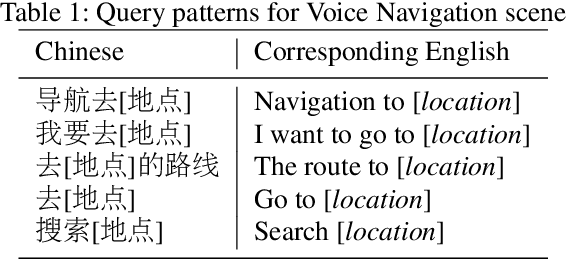
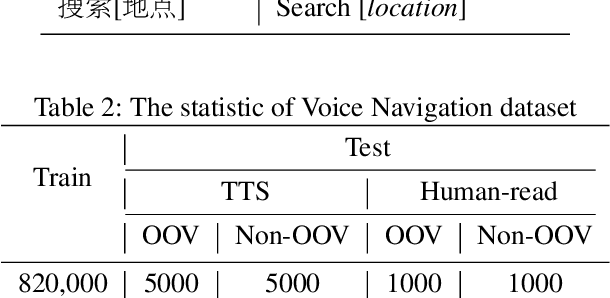
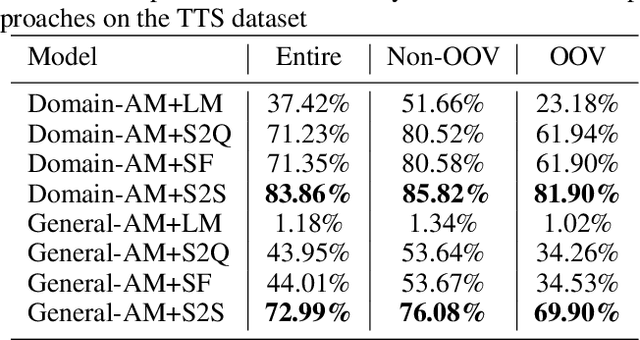
In contrast to conventional pipeline Spoken Language Understanding (SLU) which consists of automatic speech recognition (ASR) and natural language understanding (NLU), end-to-end SLU infers the semantic meaning directly from speech and overcomes the error propagation caused by ASR. End-to-end slot filling (SF) from speech is an essential component of end-to-end SLU, and is usually regarded as a sequence-to-sequence generation problem, heavily relied on the performance of language model of ASR. However, it is hard to generate a correct slot when the slot is out-of-vovabulary (OOV) in training data, especially when a slot is an anti-linguistic entity without grammatical rule. Inspired by object detection in computer vision that is to detect the object from an image, we consider SF as the task of slot detection from speech. In this paper, we formulate the SF task as a matching task and propose an end-to-end knowledge-based SF model, named Speech-to-Slot (Speech2Slot), to leverage knowledge to detect the boundary of a slot from the speech. We also release a large-scale dataset of Chinese speech for slot filling, containing more than 830,000 samples. The experiments show that our approach is markedly superior to the conventional pipeline SLU approach, and outperforms the state-of-the-art end-to-end SF approach with 12.51% accuracy improvement.