 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Compensation Residual Networks for Class Imbalanced Learning
Aug 25, 2023



Learning generalizable representation and classifier for class-imbalanced data is challenging for data-driven deep models. Most studies attempt to re-balance the data distribution, which is prone to overfitting on tail classes and underfitting on head classes. In this work, we propose Dual Compensation Residual Networks to better fit both tail and head classes. Firstly, we propose dual Feature Compensation Module (FCM) and Logit Compensation Module (LCM) to alleviate the overfitting issue. The design of these two modules is based on the observation: an important factor causing overfitting is that there is severe feature drift between training and test data on tail classes. In details, the test features of a tail category tend to drift towards feature cloud of multiple similar head categories. So FCM estimates a multi-mode feature drift direction for each tail category and compensate for it. Furthermore, LCM translates the deterministic feature drift vector estimated by FCM along intra-class variations, so as to cover a larger effective compensation space, thereby better fitting the test features. Secondly, we propose a Residual Balanced Multi-Proxies Classifier (RBMC) to alleviate the under-fitting issue. Motivated by the observation that re-balancing strategy hinders the classifier from learning sufficient head knowledge and eventually causes underfitting, RBMC utilizes uniform learning with a residual path to facilitate classifier learning. Comprehensive experiments on Long-tailed and Class-Incremental benchmarks validate the efficacy of our method.
* 20 pages
BayLing: Bridging Cross-lingual Alignment and Instruction Following through Interactive Translation for Large Language Models
Jun 21, 2023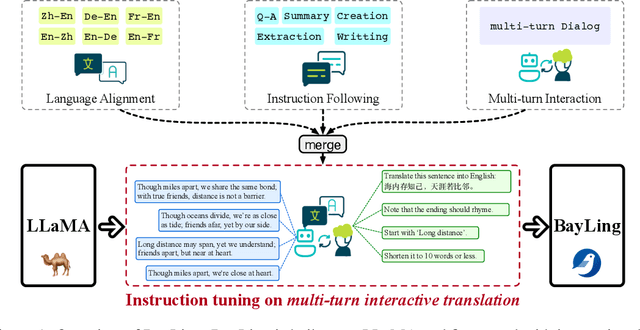
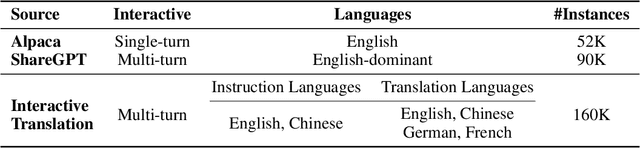

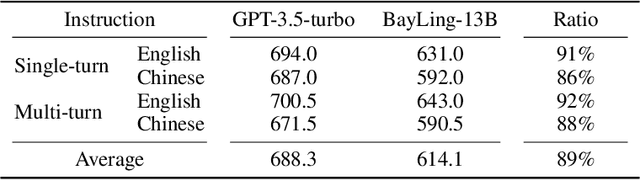
Large language models (LLMs) have demonstrated remarkable prowess in language understanding and generation. Advancing from foundation LLMs to instructionfollowing LLMs, instruction tuning plays a vital role in aligning LLMs to human preferences. However, the existing LLMs are usually focused on English, leading to inferior performance in non-English languages. In order to improve the performance for non-English languages, it is necessary to collect language-specific training data for foundation LLMs and construct language-specific instructions for instruction tuning, both of which are heavy loads. To minimize human workload, we propose to transfer the capabilities of language generation and instruction following from English to other languages through an interactive translation task. We have developed BayLing, an instruction-following LLM by utilizing LLaMA as the foundation LLM and automatically constructing interactive translation instructions for instructing tuning. Extensive assessments demonstrate that BayLing achieves comparable performance to GPT-3.5-turbo, despite utilizing a considerably smaller parameter size of only 13 billion. Experimental results on translation tasks show that BayLing achieves 95% of single-turn translation capability compared to GPT-4 with automatic evaluation and 96% of interactive translation capability compared to GPT-3.5-turbo with human evaluation. To estimate the performance on general tasks, we created a multi-turn instruction test set called BayLing-80. The experimental results on BayLing-80 indicate that BayLing achieves 89% of performance compared to GPT-3.5-turbo. BayLing also demonstrates outstanding performance on knowledge assessment of Chinese GaoKao and English SAT, second only to GPT-3.5-turbo among a multitude of instruction-following LLMs. Demo, homepage, code and models of BayLing are available.
Function-Consistent Feature Distillation
Apr 24, 2023



Feature distillation makes the student mimic the intermediate features of the teacher. Nearly all existing feature-distillation methods use L2 distance or its slight variants as the distance metric between teacher and student features. However, while L2 distance is isotropic w.r.t. all dimensions, the neural network's operation on different dimensions is usually anisotropic, i.e., perturbations with the same 2-norm but in different dimensions of intermediate features lead to changes in the final output with largely different magnitude. Considering this, we argue that the similarity between teacher and student features should not be measured merely based on their appearance (i.e., L2 distance), but should, more importantly, be measured by their difference in function, namely how later layers of the network will read, decode, and process them. Therefore, we propose Function-Consistent Feature Distillation (FCFD), which explicitly optimizes the functional similarity between teacher and student features. The core idea of FCFD is to make teacher and student features not only numerically similar, but more importantly produce similar outputs when fed to the later part of the same network. With FCFD, the student mimics the teacher more faithfully and learns more from the teacher. Extensive experiments on image classification and object detection demonstrate the superiority of FCFD to existing methods. Furthermore, we can combine FCFD with many existing methods to obtain even higher accuracy. Our codes are available at https://github.com/LiuDongyang6/FCFD.
Diversity-Measurable Anomaly Detection
Mar 09, 2023



Reconstruction-based anomaly detection models achieve their purpose by suppressing the generalization ability for anomaly. However, diverse normal patterns are consequently not well reconstructed as well. Although some efforts have been made to alleviate this problem by modeling sample diversity, they suffer from shortcut learning due to undesired transmission of abnormal information. In this paper, to better handle the tradeoff problem, we propose Diversity-Measurable Anomaly Detection (DMAD) framework to enhance reconstruction diversity while avoid the undesired generalization on anomalies. To this end, we design Pyramid Deformation Module (PDM), which models diverse normals and measures the severity of anomaly by estimating multi-scale deformation fields from reconstructed reference to original input. Integrated with an information compression module, PDM essentially decouples deformation from prototypical embedding and makes the final anomaly score more reliable. Experimental results on both surveillance videos and industrial images demonstrate the effectiveness of our method. In addition, DMAD works equally well in front of contaminated data and anomaly-like normal samples.
Clothes-Changing Person Re-identification with RGB Modality Only
Apr 14, 2022
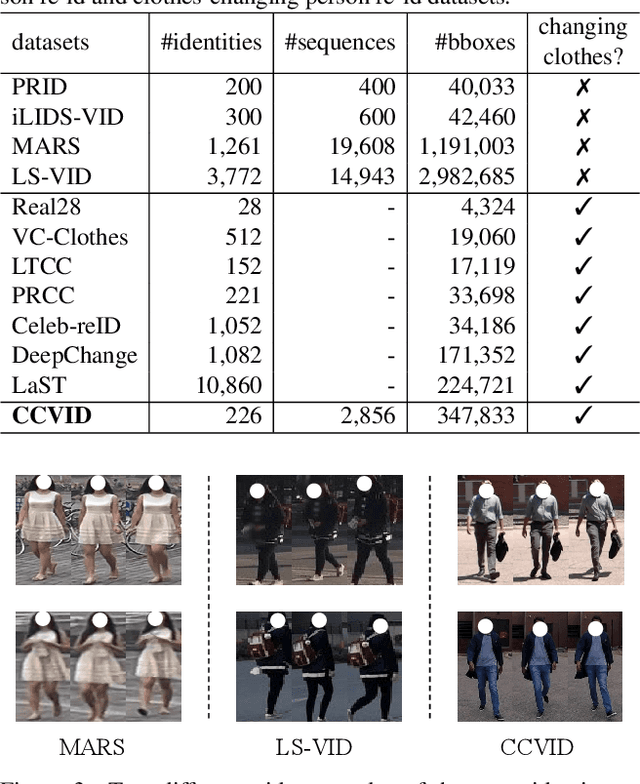
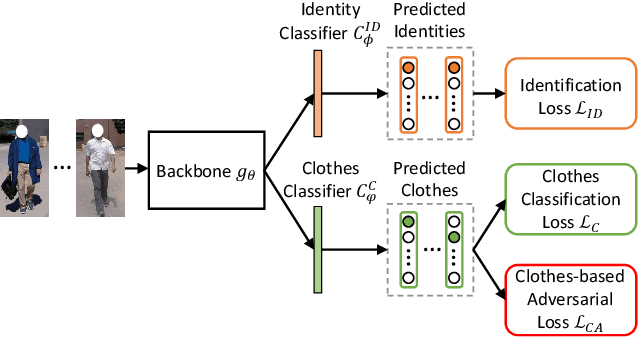
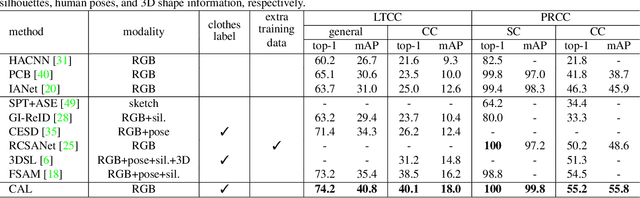
The key to address clothes-changing person re-identification (re-id) is to extract clothes-irrelevant features, e.g., face, hairstyle, body shape, and gait. Most current works mainly focus on modeling body shape from multi-modality information (e.g., silhouettes and sketches), but do not make full use of the clothes-irrelevant information in the original RGB images. In this paper, we propose a Clothes-based Adversarial Loss (CAL) to mine clothes-irrelevant features from the original RGB images by penalizing the predictive power of re-id model w.r.t. clothes. Extensive experiments demonstrate that using RGB images only, CAL outperforms all state-of-the-art methods on widely-used clothes-changing person re-id benchmarks. Besides, compared with images, videos contain richer appearance and additional temporal information, which can be used to model proper spatiotemporal patterns to assist clothes-changing re-id. Since there is no publicly available clothes-changing video re-id dataset, we contribute a new dataset named CCVID and show that there exists much room for improvement in modeling spatiotemporal information. The code and new dataset are available at: https://github.com/guxinqian/Simple-CCReID.
SEGA: Semantic Guided Attention on Visual Prototype for Few-Shot Learning
Nov 08, 2021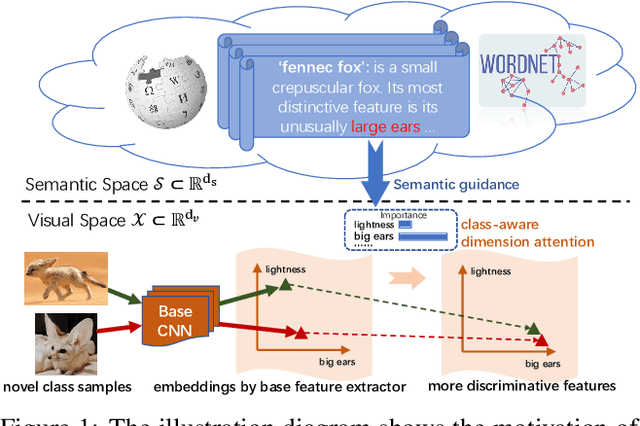


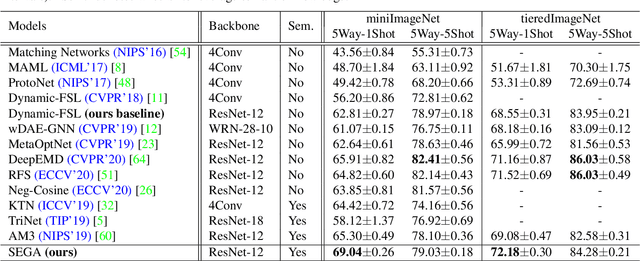
Teaching machines to recognize a new category based on few training samples especially only one remains challenging owing to the incomprehensive understanding of the novel category caused by the lack of data. However, human can learn new classes quickly even given few samples since human can tell what discriminative features should be focused on about each category based on both the visual and semantic prior knowledge. To better utilize those prior knowledge, we propose the SEmantic Guided Attention (SEGA) mechanism where the semantic knowledge is used to guide the visual perception in a top-down manner about what visual features should be paid attention to when distinguishing a category from the others. As a result, the embedding of the novel class even with few samples can be more discriminative. Concretely, a feature extractor is trained to embed few images of each novel class into a visual prototype with the help of transferring visual prior knowledge from base classes. Then we learn a network that maps semantic knowledge to category-specific attention vectors which will be used to perform feature selection to enhance the visual prototypes. Extensive experiments on miniImageNet, tieredImageNet, CIFAR-FS, and CUB indicate that our semantic guided attention realizes anticipated function and outperforms state-of-the-art results.
HRFormer: High-Resolution Transformer for Dense Prediction
Nov 07, 2021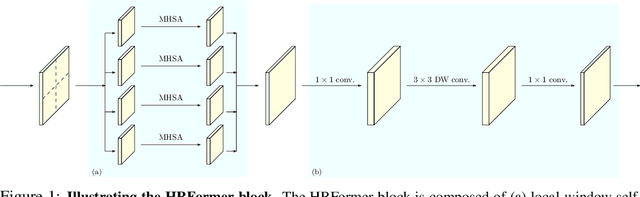
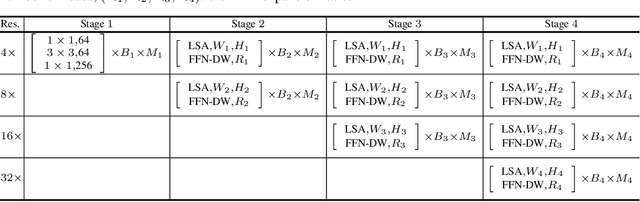


We present a High-Resolution Transformer (HRFormer) that learns high-resolution representations for dense prediction tasks, in contrast to the original Vision Transformer that produces low-resolution representations and has high memory and computational cost. We take advantage of the multi-resolution parallel design introduced in high-resolution convolutional networks (HRNet), along with local-window self-attention that performs self-attention over small non-overlapping image windows, for improving the memory and computation efficiency. In addition, we introduce a convolution into the FFN to exchange information across the disconnected image windows. We demonstrate the effectiveness of the High-Resolution Transformer on both human pose estimation and semantic segmentation tasks, e.g., HRFormer outperforms Swin transformer by $1.3$ AP on COCO pose estimation with $50\%$ fewer parameters and $30\%$ fewer FLOPs. Code is available at: https://github.com/HRNet/HRFormer.
UniCon: Unified Context Network for Robust Active Speaker Detection
Aug 05, 2021
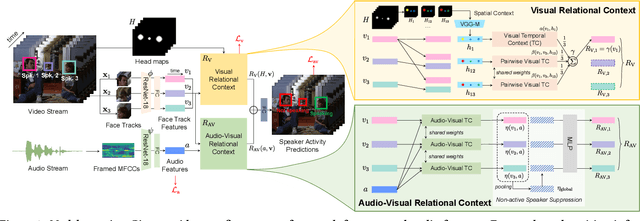
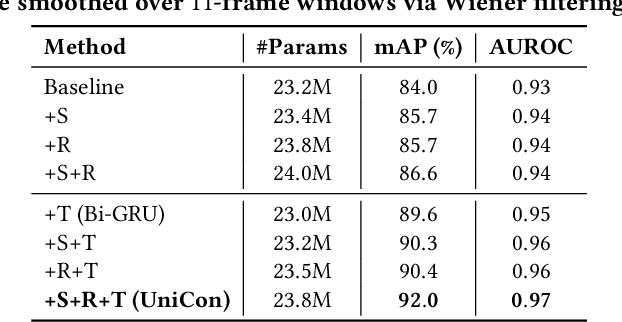

We introduce a new efficient framework, the Unified Context Network (UniCon), for robust active speaker detection (ASD). Traditional methods for ASD usually operate on each candidate's pre-cropped face track separately and do not sufficiently consider the relationships among the candidates. This potentially limits performance, especially in challenging scenarios with low-resolution faces, multiple candidates, etc. Our solution is a novel, unified framework that focuses on jointly modeling multiple types of contextual information: spatial context to indicate the position and scale of each candidate's face, relational context to capture the visual relationships among the candidates and contrast audio-visual affinities with each other, and temporal context to aggregate long-term information and smooth out local uncertainties. Based on such information, our model optimizes all candidates in a unified process for robust and reliable ASD. A thorough ablation study is performed on several challenging ASD benchmarks under different settings. In particular, our method outperforms the state-of-the-art by a large margin of about 15% mean Average Precision (mAP) absolute on two challenging subsets: one with three candidate speakers, and the other with faces smaller than 64 pixels. Together, our UniCon achieves 92.0% mAP on the AVA-ActiveSpeaker validation set, surpassing 90% for the first time on this challenging dataset at the time of submission. Project website: https://unicon-asd.github.io/.
Locality-aware Channel-wise Dropout for Occluded Face Recognition
Jul 20, 2021
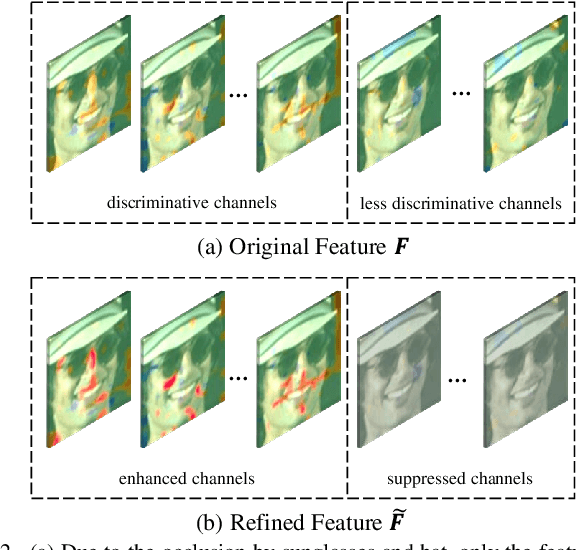
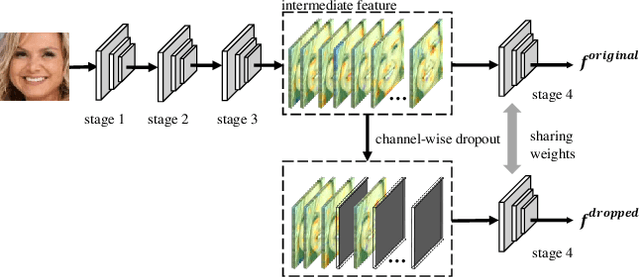
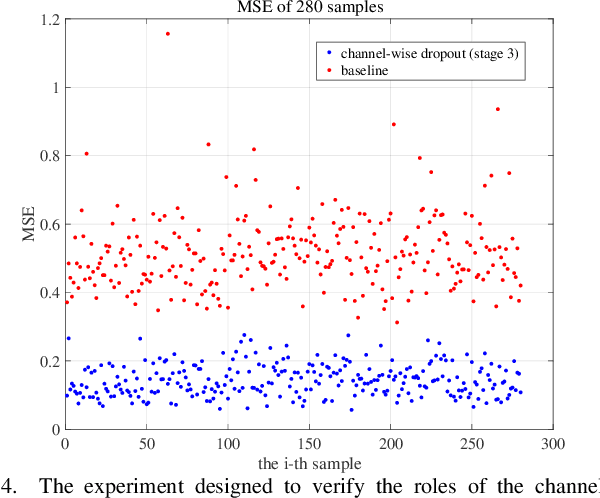
Face recognition remains a challenging task in unconstrained scenarios, especially when faces are partially occluded. To improve the robustness against occlusion, augmenting the training images with artificial occlusions has been proved as a useful approach. However, these artificial occlusions are commonly generated by adding a black rectangle or several object templates including sunglasses, scarfs and phones, which cannot well simulate the realistic occlusions. In this paper, based on the argument that the occlusion essentially damages a group of neurons, we propose a novel and elegant occlusion-simulation method via dropping the activations of a group of neurons in some elaborately selected channel. Specifically, we first employ a spatial regularization to encourage each feature channel to respond to local and different face regions. In this way, the activations affected by an occlusion in a local region are more likely to be located in a single feature channel. Then, the locality-aware channel-wise dropout (LCD) is designed to simulate the occlusion by dropping out the entire feature channel. Furthermore, by randomly dropping out several feature channels, our method can well simulate the occlusion of larger area. The proposed LCD can encourage its succeeding layers to minimize the intra-class feature variance caused by occlusions, thus leading to improved robustness against occlusion. In addition, we design an auxiliary spatial attention module by learning a channel-wise attention vector to reweight the feature channels, which improves the contributions of non-occluded regions. Extensive experiments on various benchmarks show that the proposed method outperforms state-of-the-art methods with a remarkable improvement.
Gaze Estimation with an Ensemble of Four Architectures
Jul 05, 2021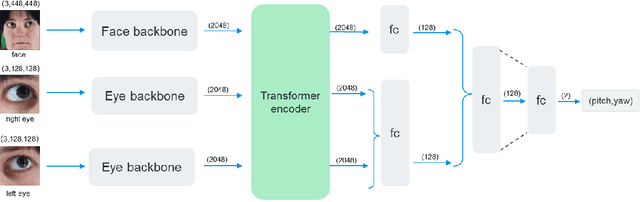
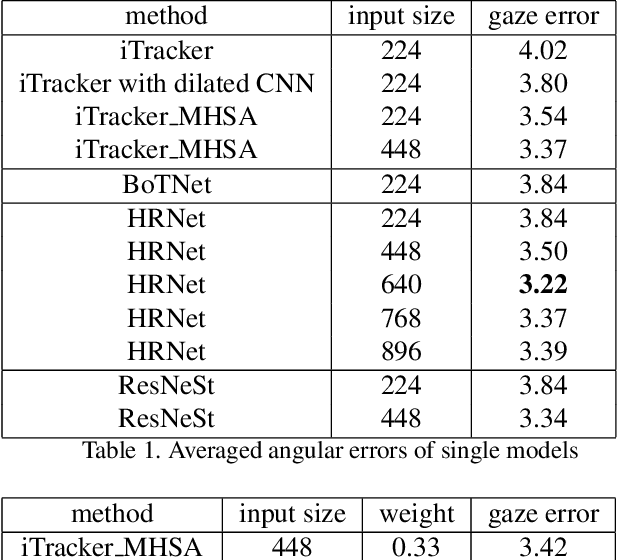
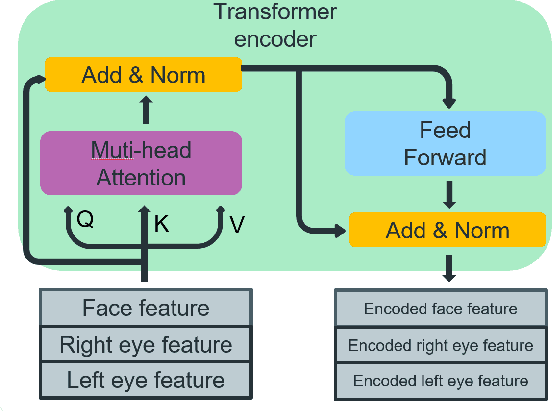
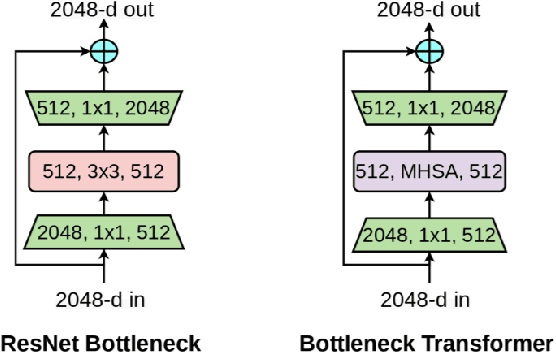
This paper presents a method for gaze estimation according to face images. We train several gaze estimators adopting four different network architectures, including an architecture designed for gaze estimation (i.e.,iTracker-MHSA) and three originally designed for general computer vision tasks(i.e., BoTNet, HRNet, ResNeSt). Then, we select the best six estimators and ensemble their predictions through a linear combination. The method ranks the first on the leader-board of ETH-XGaze Competition, achieving an average angular error of $3.11^{\circ}$ on the ETH-XGaze test set.