 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Teach: Learning Data-Free Knowledge Distillation from Curriculum
Aug 29, 2022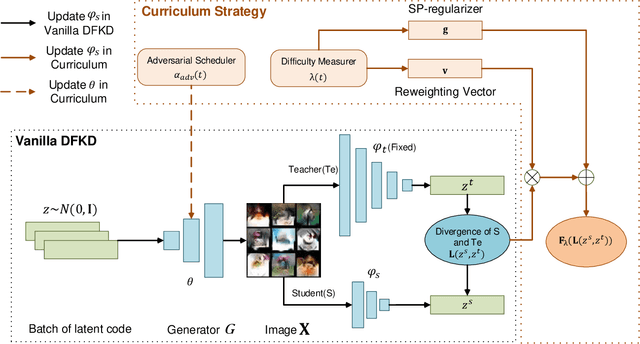
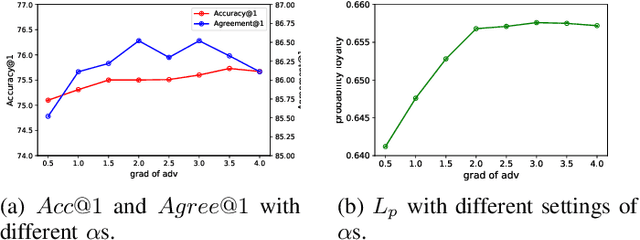
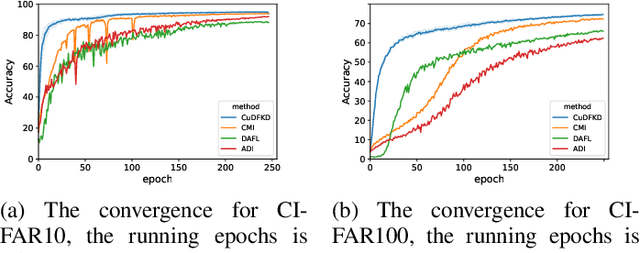
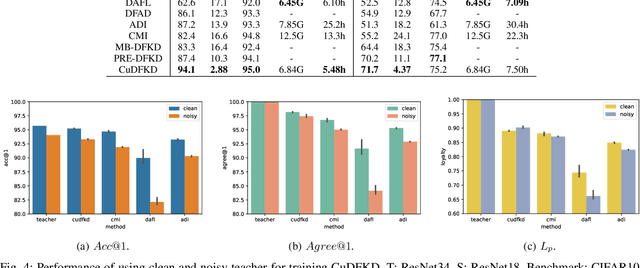
Data-free knowledge distillation (DFKD) aims at training lightweight student networks from teacher networks without training data. Existing approaches mainly follow the paradigm of generating informative samples and progressively updating student models by targeting data priors, boundary samples or memory samples. However, it is difficult for the previous DFKD methods to dynamically adjust the generation strategy at different training stages, which in turn makes it difficult to achieve efficient and stable training. In this paper, we explore how to teach students the model from a curriculum learning (CL) perspective and propose a new approach, namely "CuDFKD", i.e., "Data-Free Knowledge Distillation with Curriculum". It gradually learns from easy samples to difficult samples, which is similar to the way humans learn. In addition, we provide a theoretical analysis of the majorization minimization (MM) algorithm and explain the convergence of CuDFKD. Experiments conducted on benchmark datasets show that with a simple course design strategy, CuDFKD achieves the best performance over state-of-the-art DFKD methods and different benchmarks, such as 95.28\% top1 accuracy of the ResNet18 model on CIFAR10, which is better than training from scratch with data. The training is fast, reaching the highest accuracy of 90\% within 30 epochs, and the variance during training is stable. Also in this paper, the applicability of CuDFKD is also analyzed and discussed.
Limitations of Language Models in Arithmetic and Symbolic Induction
Aug 09, 2022
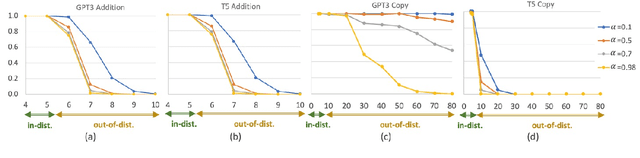

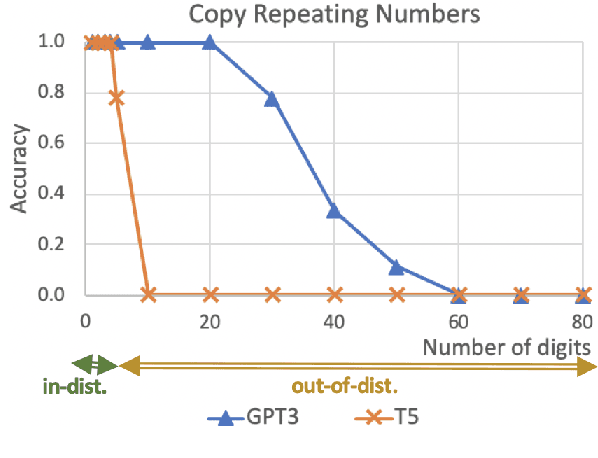
Recent work has shown that large pretrained Language Models (LMs) can not only perform remarkably well on a range of Natural Language Processing (NLP) tasks but also start improving on reasoning tasks such as arithmetic induction, symbolic manipulation, and commonsense reasoning with increasing size of models. However, it is still unclear what the underlying capabilities of these LMs are. Surprisingly, we find that these models have limitations on certain basic symbolic manipulation tasks such as copy, reverse, and addition. When the total number of symbols or repeating symbols increases, the model performance drops quickly. We investigate the potential causes behind this phenomenon and examine a set of possible methods, including explicit positional markers, fine-grained computation steps, and LMs with callable programs. Experimental results show that none of these techniques can solve the simplest addition induction problem completely. In the end, we introduce LMs with tutor, which demonstrates every single step of teaching. LMs with tutor is able to deliver 100% accuracy in situations of OOD and repeating symbols, shedding new insights on the boundary of large LMs in induction.
Visually-Augmented Language Modeling
May 20, 2022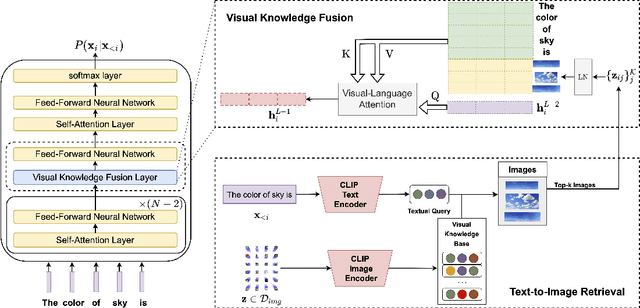

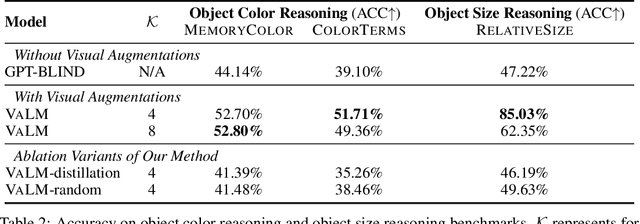
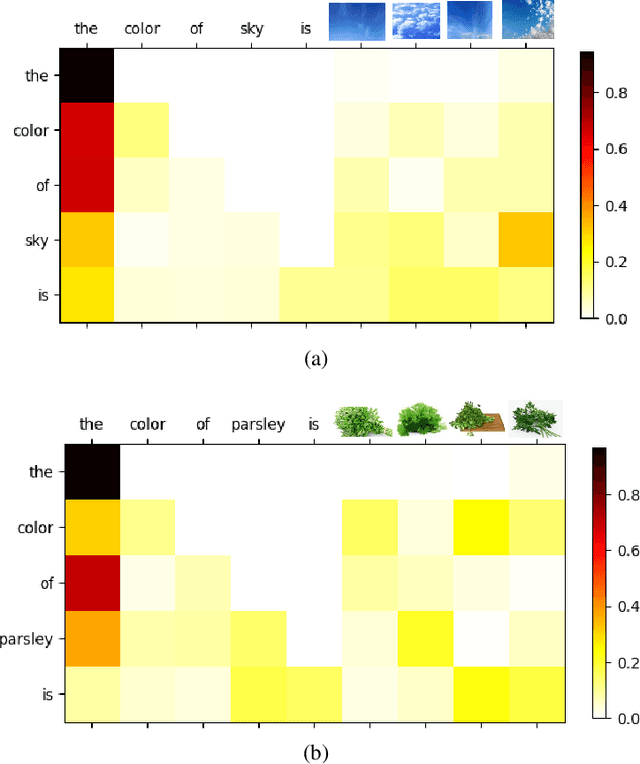
Human language is grounded on multimodal knowledge including visual knowledge like colors, sizes, and shapes. However, current large-scale pre-trained language models rely on the text-only self-supervised training with massive text data, which precludes them from utilizing relevant visual information when necessary. To address this, we propose a novel pre-training framework, named VaLM, to Visually-augment text tokens with retrieved relevant images for Language Modeling. Specifically, VaLM builds on a novel text-vision alignment method via an image retrieval module to fetch corresponding images given a textual context. With the visually-augmented context, VaLM uses a visual knowledge fusion layer to enable multimodal grounded language modeling by attending on both text context and visual knowledge in images. We evaluate the proposed model on various multimodal commonsense reasoning tasks, which require visual information to excel. VaLM outperforms the text-only baseline with substantial gains of +8.66% and +37.81% accuracy on object color and size reasoning, respectively.
Task-adaptive Pre-training and Self-training are Complementary for Natural Language Understanding
Sep 14, 2021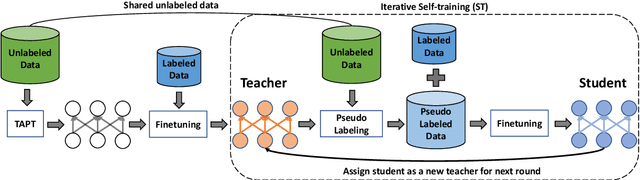
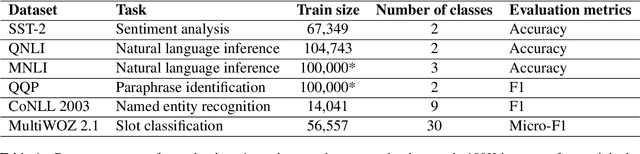
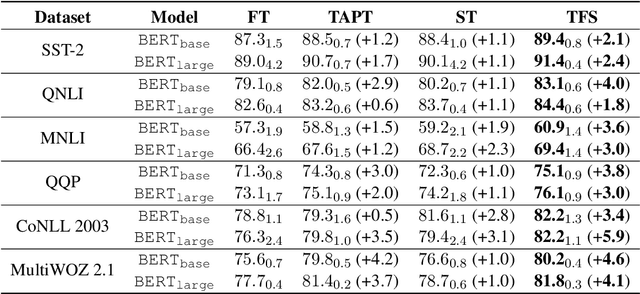
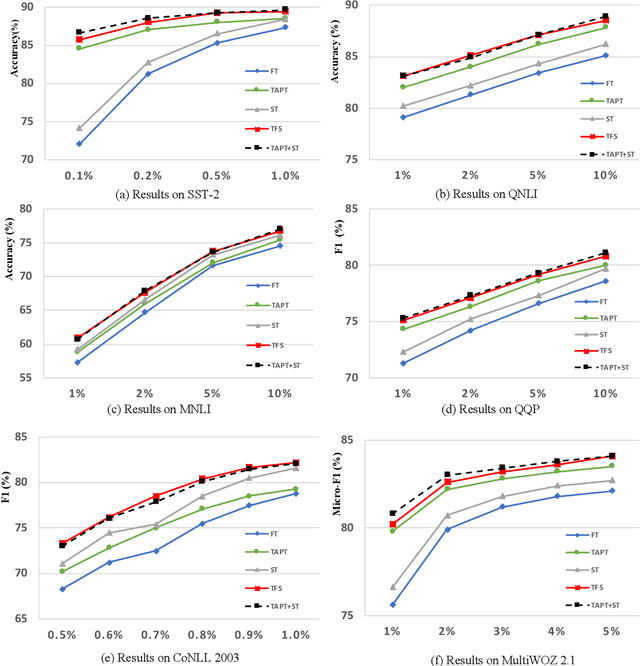
Task-adaptive pre-training (TAPT) and Self-training (ST) have emerged as the major semi-supervised approaches to improve natural language understanding (NLU) tasks with massive amount of unlabeled data. However, it's unclear whether they learn similar representations or they can be effectively combined. In this paper, we show that TAPT and ST can be complementary with simple TFS protocol by following TAPT -> Finetuning -> Self-training (TFS) process. Experimental results show that TFS protocol can effectively utilize unlabeled data to achieve strong combined gains consistently across six datasets covering sentiment classification, paraphrase identification, natural language inference, named entity recognition and dialogue slot classification. We investigate various semi-supervised settings and consistently show that gains from TAPT and ST can be strongly additive by following TFS procedure. We hope that TFS could serve as an important semi-supervised baseline for future NLP studies.
Semi-Supervised Hypothesis Transfer for Source-Free Domain Adaptation
Jul 14, 2021



Domain Adaptation has been widely used to deal with the distribution shift in vision, language, multimedia etc. Most domain adaptation methods learn domain-invariant features with data from both domains available. However, such a strategy might be infeasible in practice when source data are unavailable due to data-privacy concerns. To address this issue, we propose a novel adaptation method via hypothesis transfer without accessing source data at adaptation stage. In order to fully use the limited target data, a semi-supervised mutual enhancement method is proposed, in which entropy minimization and augmented label propagation are used iteratively to perform inter-domain and intra-domain alignments. Compared with state-of-the-art methods, the experimental results on three public datasets demonstrate that our method gets up to 19.9% improvements on semi-supervised adaptation tasks.
Lifelong Learning of Hate Speech Classification on Social Media
Jun 05, 2021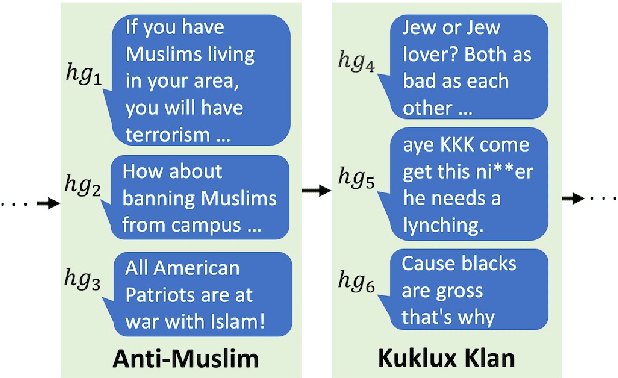
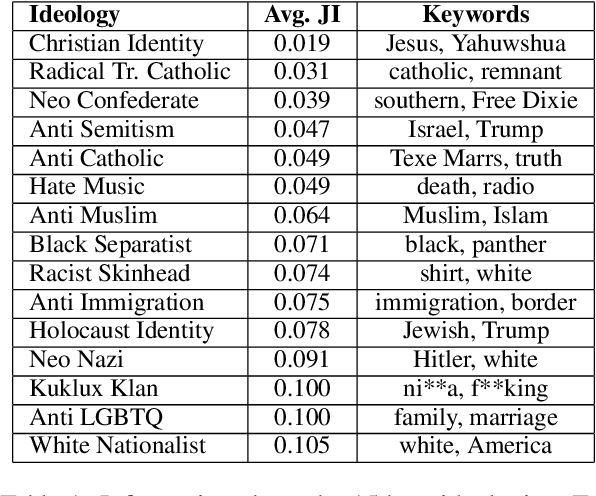
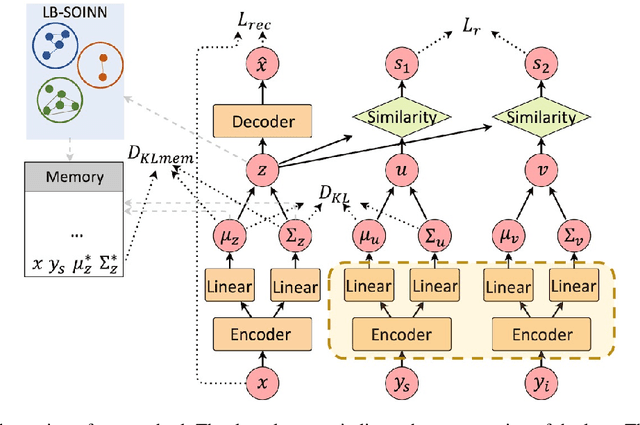
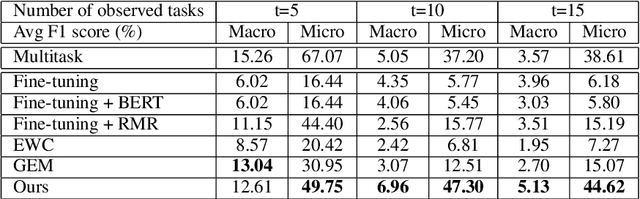
Existing work on automated hate speech classification assumes that the dataset is fixed and the classes are pre-defined. However, the amount of data in social media increases every day, and the hot topics changes rapidly, requiring the classifiers to be able to continuously adapt to new data without forgetting the previously learned knowledge. This ability, referred to as lifelong learning, is crucial for the real-word application of hate speech classifiers in social media. In this work, we propose lifelong learning of hate speech classification on social media. To alleviate catastrophic forgetting, we propose to use Variational Representation Learning (VRL) along with a memory module based on LB-SOINN (Load-Balancing Self-Organizing Incremental Neural Network). Experimentally, we show that combining variational representation learning and the LB-SOINN memory module achieves better performance than the commonly-used lifelong learning techniques.
Inductive Relation Prediction by BERT
Mar 12, 2021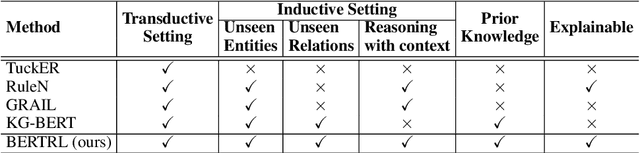
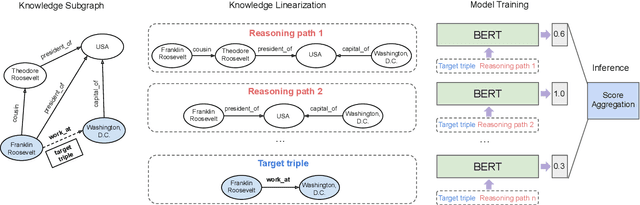
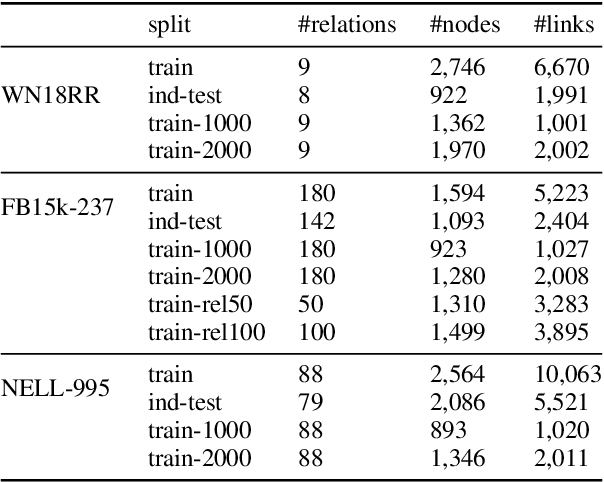
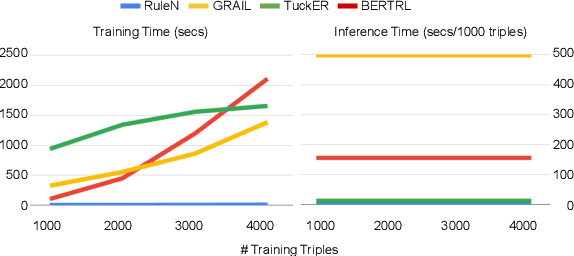
Relation prediction in knowledge graphs is dominated by embedding based methods which mainly focus on the transductive setting. Unfortunately, they are not able to handle inductive learning where unseen entities and relations are present and cannot take advantage of prior knowledge. Furthermore, their inference process is not easily explainable. In this work, we propose an all-in-one solution, called BERTRL (BERT-based Relational Learning), which leverages pre-trained language model and fine-tunes it by taking relation instances and their possible reasoning paths as training samples. BERTRL outperforms the SOTAs in 15 out of 18 cases in both inductive and transductive settings. Meanwhile, it demonstrates strong generalization capability in few-shot learning and is explainable.
Composite Re-Ranking for Efficient Document Search with BERT
Mar 12, 2021
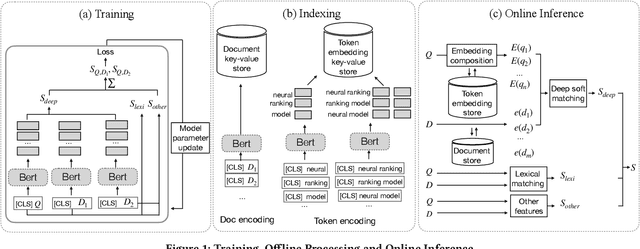

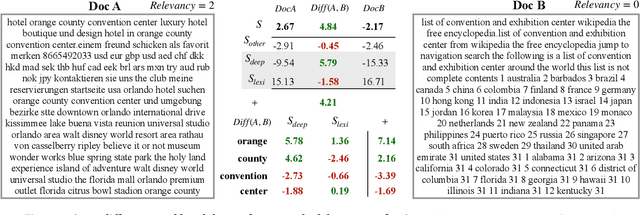
Although considerable efforts have been devoted to transformer-based ranking models for document search, the relevance-efficiency tradeoff remains a critical problem for ad-hoc ranking. To overcome this challenge, this paper presents BECR (BERT-based Composite Re-Ranking), a composite re-ranking scheme that combines deep contextual token interactions and traditional lexical term-matching features. In particular, BECR exploits a token encoding mechanism to decompose the query representations into pre-computable uni-grams and skip-n-grams. By applying token encoding on top of a dual-encoder architecture, BECR separates the attentions between a query and a document while capturing the contextual semantics of a query. In contrast to previous approaches, this framework does not perform expensive BERT computations during online inference. Thus, it is significantly faster, yet still able to achieve high competitiveness in ad-hoc ranking relevance. Finally, an in-depth comparison between BECR and other start-of-the-art neural ranking baselines is described using the TREC datasets, thereby further demonstrating the enhanced relevance and efficiency of BECR.
Cross-modal Image Retrieval with Deep Mutual Information Maximization
Mar 10, 2021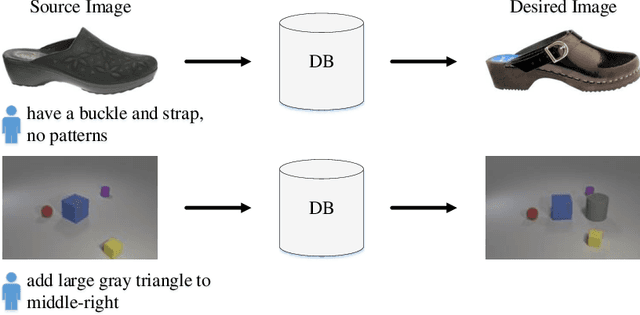
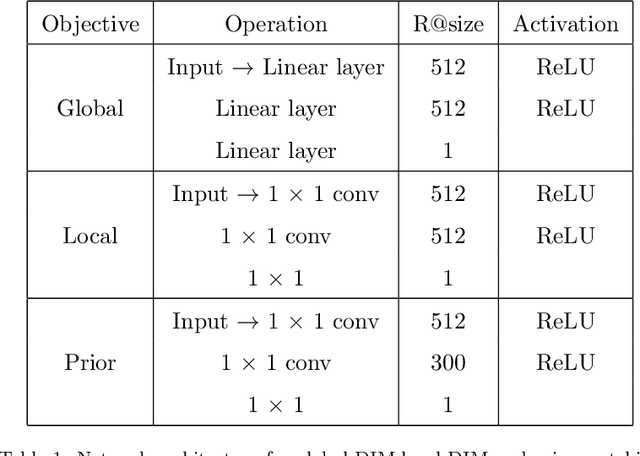
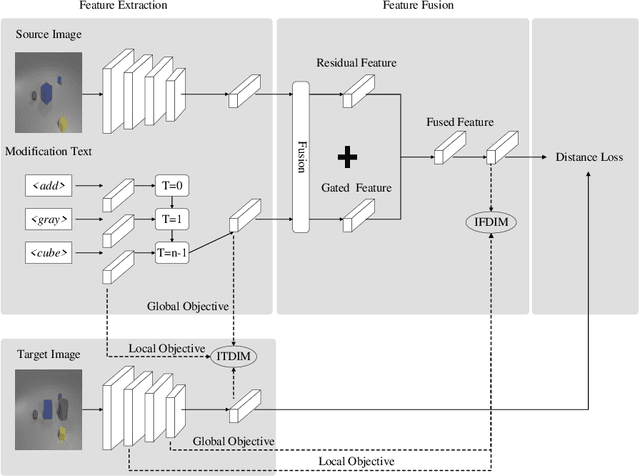
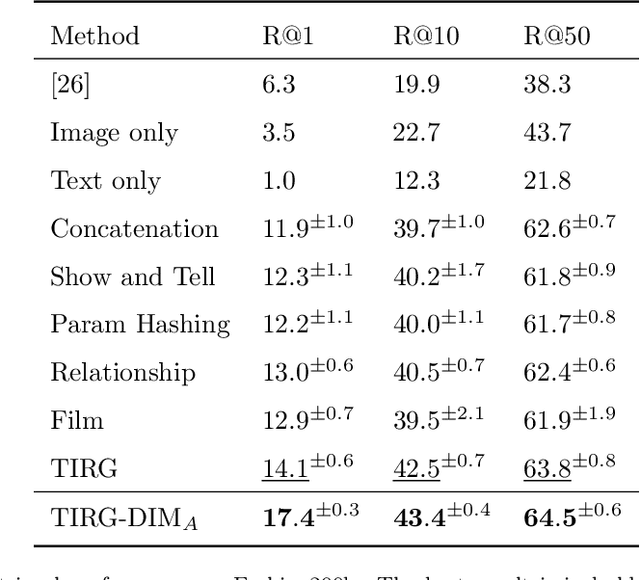
In this paper, we study the cross-modal image retrieval, where the inputs contain a source image plus some text that describes certain modifications to this image and the desired image. Prior work usually uses a three-stage strategy to tackle this task: 1) extract the features of the inputs; 2) fuse the feature of the source image and its modified text to obtain fusion feature; 3) learn a similarity metric between the desired image and the source image + modified text by using deep metric learning. Since classical image/text encoders can learn the useful representation and common pair-based loss functions of distance metric learning are enough for cross-modal retrieval, people usually improve retrieval accuracy by designing new fusion networks. However, these methods do not successfully handle the modality gap caused by the inconsistent distribution and representation of the features of different modalities, which greatly influences the feature fusion and similarity learning. To alleviate this problem, we adopt the contrastive self-supervised learning method Deep InforMax (DIM) to our approach to bridge this gap by enhancing the dependence between the text, the image, and their fusion. Specifically, our method narrows the modality gap between the text modality and the image modality by maximizing mutual information between their not exactly semantically identical representation. Moreover, we seek an effective common subspace for the semantically same fusion feature and desired image's feature by utilizing Deep InforMax between the low-level layer of the image encoder and the high-level layer of the fusion network. Extensive experiments on three large-scale benchmark datasets show that we have bridged the modality gap between different modalities and achieve state-of-the-art retrieval performance.
Attention-based Domain Adaptation for Time Series Forecasting
Feb 17, 2021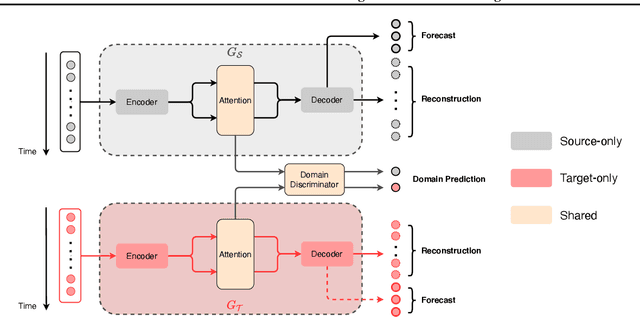
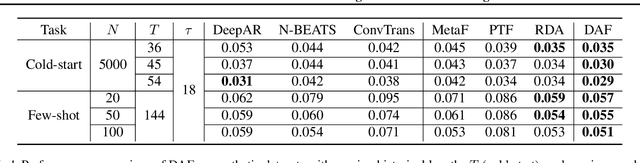

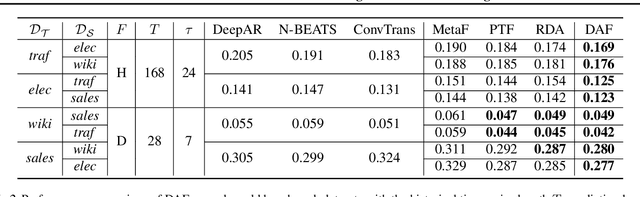
Recent years have witnessed deep neural networks gaining increasing popularity in the field of time series forecasting. A primary reason of their success is their ability to effectively capture complex temporal dynamics across multiple related time series. However, the advantages of these deep forecasters only start to emerge in the presence of a sufficient amount of data. This poses a challenge for typical forecasting problems in practice, where one either has a small number of time series, or limited observations per time series, or both. To cope with the issue of data scarcity, we propose a novel domain adaptation framework, Domain Adaptation Forecaster (DAF), that leverages the statistical strengths from another relevant domain with abundant data samples (source) to improve the performance on the domain of interest with limited data (target). In particular, we propose an attention-based shared module with a domain discriminator across domains as well as private modules for individual domains. This allows us to jointly train the source and target domains by generating domain-invariant latent features while retraining domain-specific features. Extensive experiments on various domains demonstrate that our proposed method outperforms state-of-the-art baselines on synthetic and real-world datasets.